
独家 | 降维是数据科学家的必由之路

作者:shanthababu 翻译:王可汗
校对:欧阳锦
本文约2200字,建议阅读10分钟
本文为大家介绍了降维的概念及降维技术主成分分析(PCA)在特征工程中的应用。
https://datahack.analyticsvidhya.com/contest/data-science-blogathon-7/

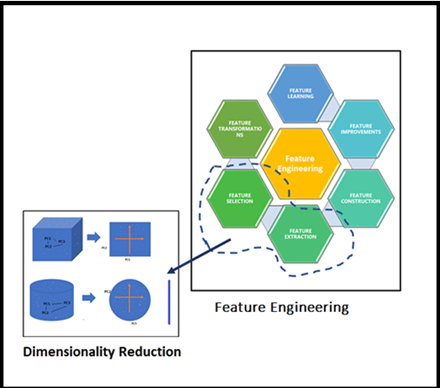
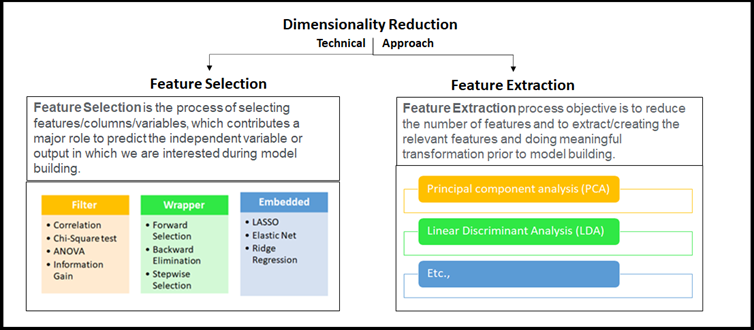
1-D,2-D

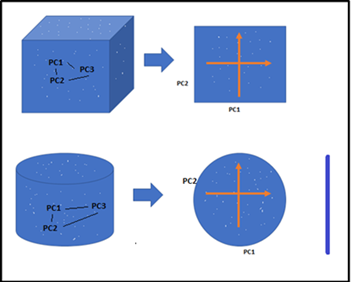
它有助于消除冗余的特征和噪声误差因素,最终增强给定数据集的可视化。
由于降低了维度,可以表现出优秀的内存管理。
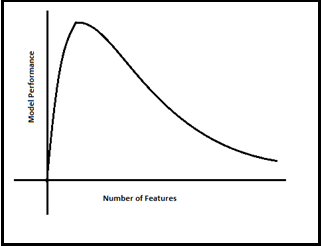
通过从数据集中删除不必要的特征列表来选择正确的特征,从而提高模型的性能。
当然,更少的维度(强制性的维度列表)需要更少的计算效率,更快地训练模型,提高模型的准确性。
大大降低了整个模型及其性能的复杂性和过拟合。

# Import all the necessary packagesimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import confusion_matrixfrom sklearn.metrics import accuracy_scorefrom sklearn import metrics%matplotlib inlineimport matplotlib.pyplot as plt%matplotlib inlinewq_dataset = pd.read_csv('winequality.csv')
wq_dataset.head(5)
wq_dataset.describe()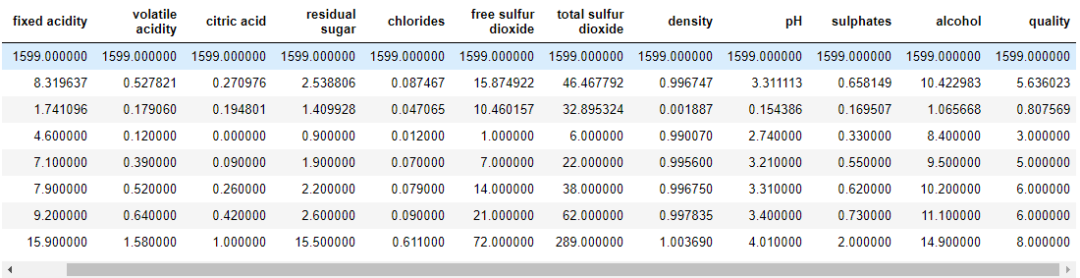
wq_dataset.isnull().any()
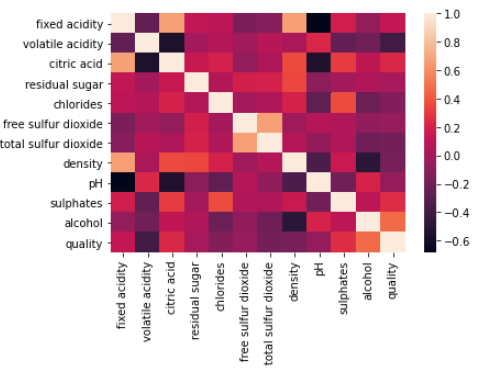
correlations = wq_dataset.corr()['quality'].drop('quality')print(correlations)

sns.heatmap(wq_dataset.corr())plt.show()
x = wq_dataset[features]y = wq_dataset['quality'][‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=3)print('Traning data shape:', x_train.shape)print('Testing data shape:', x_test.shape)Traning data shape: (1199, 8)Testing data shape: (400, 8)
from sklearn.decomposition import PCApca_wins = PCA(n_components=2)principalComponents_wins = pca_wins.fit_transform(x)
pcs_wins_df = pd.DataFrame(data = principalComponents_wins, columns = ['principal component 1', 'principal component 2'])pcs_wins_df.head()
print('Explained variation per principal component: {}'.format(pca_wins.explained_variance_ratio_))Explained variation per principal component: [0.99615166 0.00278501]
逻辑回归
随机森林
KNN
朴素贝叶斯
原文标题:
Dimensionality Reduction a Descry for Data Scientist
原文链接:
https://www.analyticsvidhya.com/blog/2021/04/dimensionality-reduction-a-descry-for-data-scientist/
译者简介

王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织