
【数学笔记】PCA数据降维
点击蓝字 关注我们
最近几天开始看华为杯的论文,第一篇关于无线智能传播的模型就有太多的东西看不懂,其中涉及到很多有关数据特征工程的一些算法,为此我查阅了不少的资料,一点点搞吧,权当做个记录。
PCA即主成分分析,是用一个超平面对所有样本进行恰当表达的方法,思想是将n维特征映射到k维上(k
这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。由于它具有降维去噪的强大作用,通常在数据挖掘中起到很重要的作用。
PCA基本数学原理
数据的向量表示及降维问题
下面先来看一个高中就学过的向量运算:内积。两个维数相同的向量的内积被定义为:

内积运算将两个向量映射为一个实数。
下面我们分析内积的几何意义。
假设A和B是两个n维向量,我们知道n维向量可以等价表示为n维空间中的一条从原点发射的有向线段。

我们将内积表示为另一种我们熟悉的形式:

假设B的模为1
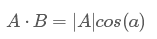
设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度!
基
向量(x,y)实际上表示线性组合:

此处(1,0)和(0,1)叫做二维空间中的一组基。
所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。
我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。
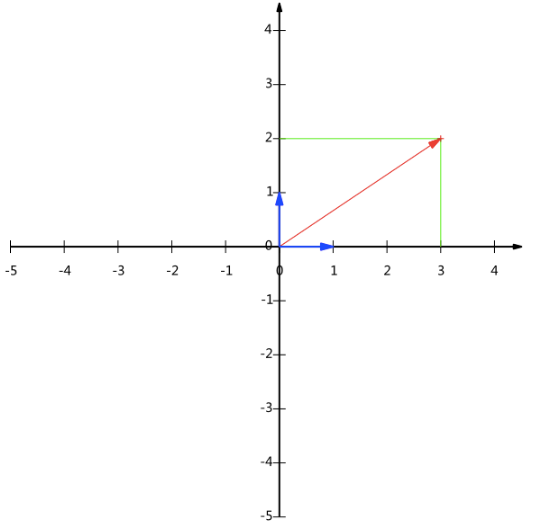
现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为

下图给出了新的基以及(3,2)在新基上坐标值的示意图:
基变换的矩阵表示
下面我们找一种简便的方式来表示基变换。

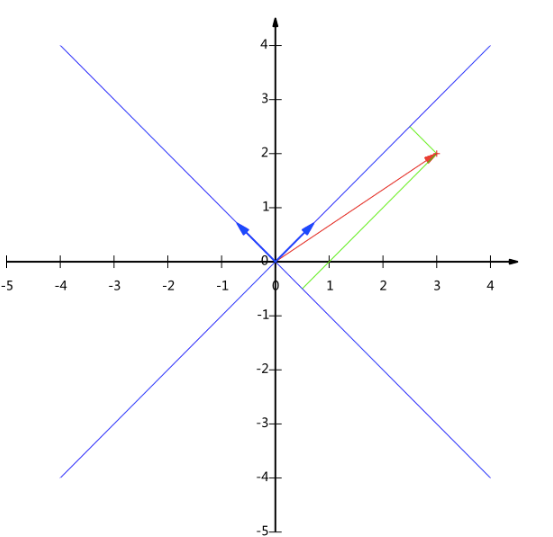
例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
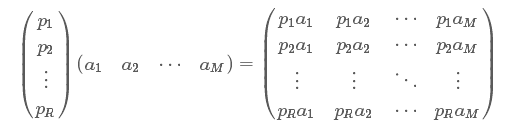
协方差矩阵及优化目标
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
我们以一个具体的例子展开。
假设我们的数据由五条记录组成,将它们表示成矩阵形式:

为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0(这样做的道理和好处后面会看到)。

五条数据在平面直角坐标系内的样子:
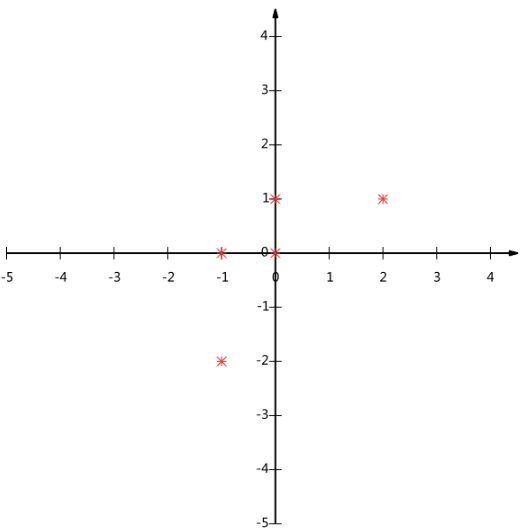
现在问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
通过以上对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
数学方法描述
方差
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
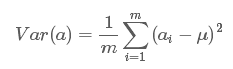
由于上面我们已经将每个字段的均值都化为0了,因此方差可以直接用每个元素的平方和除以元素个数表示:

协方差
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则:

当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
协方差矩阵
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
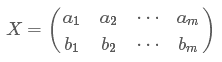
然后我们用X乘以X的转置,并乘上系数1/m:
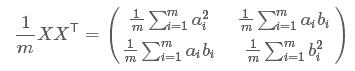
奇迹出现了!这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的。
协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
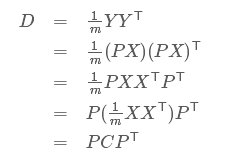
我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。换句话说,优化目标变成了寻找一个矩阵P,满足
一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,

则对协方差矩阵C有如下结论:

我们发现我们已经找到了需要的矩阵P:
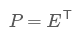
总结一下PCA的算法步骤:

sklearn中PCA注释
与上述推导不同,在sklearn中,通过SVD计算协方差矩阵的特征值与特征向量。
导入:
from sklearn.decomposition import PCAPCA代码参数:
PCA( n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None,)
我也不全明白,主要对几个常用的参数做一个注解:
n_components:接受参数类型为int, float or ‘mle’,
PCA算法中所要保留的主成分个数,也即保留下来的特征个数,
如果 n_components = 1,将把原始数据降到一维;
如果赋值为string,如n_components=‘mle’,将自动选取特征个数,使得满足所要求的方差百分比;
如果没有赋值,默认为None,特征个数不会改变(特征数据本身会改变)
whiten:数据在经过 PCA 白化以后,其协方差矩阵是一个单位矩阵,即各维度变得不相关,且每个维度方差都是 1。默认为False
属性:
explained_variance_ratio_:返回所保留各个特征的方差百分比,如果n_components没有赋值,则所有特征都会返回一个数值且解释方差之和等于1
n_components_:返回所保留的特征个数
方法:
fit(X):用数据X来训练PCA模型
fit_transform(X):用X来训练PCA模型,同时返回降维后的数据
newX=pca.fit_transform(X),newX就是降维后的数据。
inverse_transform(X):将降维后的数据转换成原始数据,X=pca.inverse_transform(newX)
transform(X):将数据X转换成降维后的数据。当模型训练好后,对于新输入的数据,都可以用transform方法来降维。
使用sklearn实现PCA降维
> import numpy as np> from sklearn.decomposition import PCA> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])> pca = PCA(n_components=2)> pca.fit(X)PCA(n_components=2)> print(pca.explained_variance_ratio_)[0.9924... 0.0075...]
参考来源:
http://blog.codinglabs.org/articles/pca-tutorial.html
https://blog.csdn.net/program_developer/article/details/80632779
https://blog.csdn.net/happyxghero/article/details/92846614
https://blog.csdn.net/kobeyu652453/article/details/107058229?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522161287299616780261913125%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fall.%252522%25257D&request_id=161287299616780261913125&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-5-107058229.pc_search_result_cache&utm_term=sklearn+%25E4%25B8%25ADPCA%25E6%25BA%2590%25E7%25A0%2581%25E5%2588%2586%25E6%259E%2590
https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html?highlight=pca#sklearn.decomposition.PCA

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述