
扩散模型在文本生成领域的应用

新智元报道
来源:知乎
编辑:桃子
【新智元导读】扩散模型在文本生成领域的应用有哪些?本文就3篇论文展开解读。
本文主要讨论以下几篇论文
Structured Denoising Diffusion Models in Discrete State-Spaces(D3PM)
Diffusion-LM Improves Controllable Text Generation
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
Structured Denoising Diffusion Models in Discrete State-Spaces(D3PM)
在近期北大出的一篇综述里看到扩散模型对文本生成的应用的章节里提到了D3PM,就去看了看这篇论文。实质上参考意义非常有限,仅粗读了一遍在此简单记录一下。
D3PM笔者认为最大的亮点在于泛化了扩散过程里的扩散方式。还记得在
大一统视角理解扩散模型
里,笔者复述了扩散模型的变分推导过程,其中推导到最终将得到以下主要优化的损失函数。
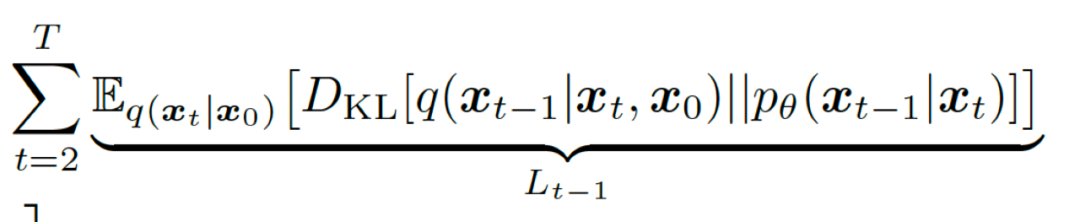 扩散模型里的去噪匹配项
扩散模型里的去噪匹配项
而具体怎么优化该损失函数,主要应用的是扩散模型里每一步加噪都是加高斯噪声的性质,使得最终该函数里的每一项都可求得具体的解析表达式。但应用了高斯分布加噪主要是因为扩散模型主要针对图像或者波形的生成,那么如果要将扩散过程加入到离散的变量里,是否可以用不同的加噪方式?论文指出,主要要满足以下两点:
该加噪方式应使得xt从q(xt|x0)中的采样方便快捷。使得我们能够对以上的去噪匹配项里的L_t-1在任意时间步上方便计算。
同时该加噪方式应使得q(xt-1| xt, x0)有方便计算的解析形式,使得我们计算去噪匹配项的KL散度成为可能。
很明显,高斯噪声完美符合以上两个要求。而作者则提出了对于离散变量的加噪方式。具体的数理推导笔者按下不表,但简单来说就是定义了一系列转移矩阵。其中关于文本生成的转移矩阵的特点在于基于概率在不同时间步将一个离散词转为MASK 字符或者保持不变。

D3PM在文本生成上的扩散过程
笔者看到这里的时候,发现这个形式和笔者之前调研的
非自回归式生成里的CMLM
特别相像。感兴趣的读者可以看看。如果是类似该架构的扩散的话,笔者认为该扩散模型的实现方式在语言质量上仍难谈优秀。CMLM类的非自回归模型,在文本生成质量上的确难以匹敌自回归式的生成模型。在逐渐去噪的过程中逐步确定生成词的方式,实际上和CMLM的做法没有太大本质区别。笔者认为对比CMLM不太可能有质的提升。
Diffusion-LM Improves Controllable Text Generation
相比于D3PM,这篇论文的主要创新点在于定义了一个词嵌入的方程统一了扩散过程里离散到连续的状态。我们可以看到D3PM本质上的扩散是在离散序列上做的。但是Diffusion-LM的具体做法是前向时离散的字词首先通过词嵌入转为一系列连续的潜在向量。之后对每个连续向量不断加高斯噪声进行前向扩散。后向时不断去噪并且最终将每个潜在向量量化到一个距离最近的词嵌入上。具体来说前向时从离散的词序列w到x0的过程为:
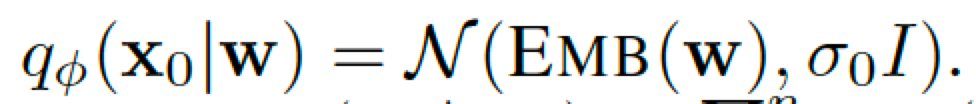 Emb为词嵌入方程,前向为从离散到连续
Emb为词嵌入方程,前向为从离散到连续
反向去噪到x0后,则要对每个潜在向量求一个距离最近的离散词。和生成过程中的解码类似,用softmax即可。
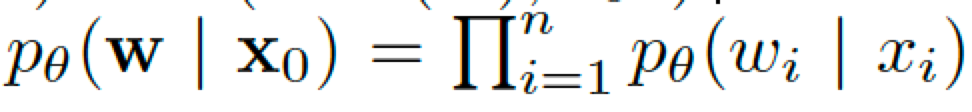 后向为从连续到离散
后向为从连续到离散
在
大一统视角理解扩散模型
里,论文作者解释了扩散模型的不同解读最终可以看做其变分下界里的去噪匹配项里对每一个时间步的潜在向量均值mu_q的不同变形。其具体形式如下:
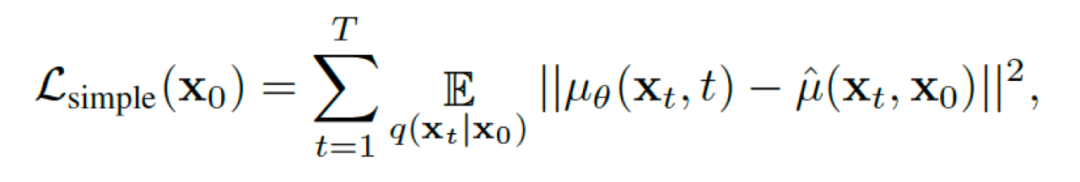 扩散模型的变分下界的最主要优化项的等价形式
扩散模型的变分下界的最主要优化项的等价形式
而在将扩散模型应用到文本生成领域以后,因为多出的词嵌入的关系,作者在该基础上增添了两项词嵌入的优化:
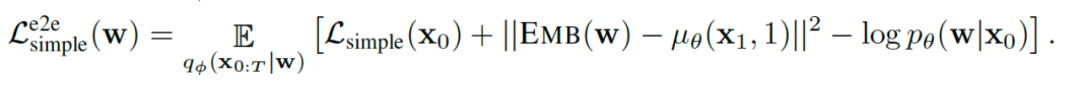 多出的两项都和词嵌入直接相关
多出的两项都和词嵌入直接相关
在
大一统视角理解扩散模型
里,论文作者提到不同的扩散模型对每一时间步的均值的估计可以拆解成三种不同的解法。DDPM里是直接对噪声进行预测,而作者lisa发现如果直接预测噪声会导致最终去噪后的结果不对应任何词嵌入。为了解决这个问题作者改为使用三种解法里的第一种,即直接预测初始输入x0。
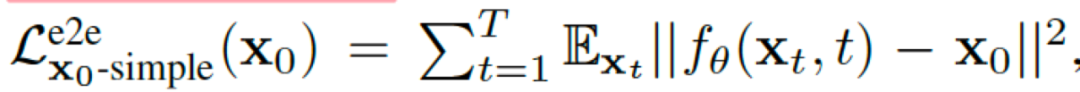 每一步的优化目标其中之一是直接预测初始输入
每一步的优化目标其中之一是直接预测初始输入
基于从连续到离散难以对应的这个观察,作者还进一步提出了在解码做下游推断的时候,用clamp的方法把每一次f_theta预测出的初始输入“夹”到一个对应的词嵌入上后,再继续去噪。并宣称这样可以让预测更准确,减少rounding error。
当然这篇论文主要在讨论条件生成这件事。从论文标题也可以看出。具体在条件生成上,作者用的是SongYang博士的Score-matching的角度用贝叶斯法则做的推导:
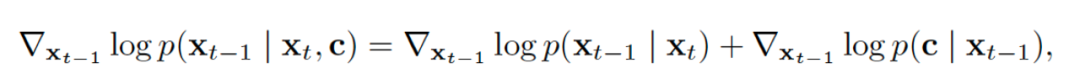 将条件生成拆解为两项
将条件生成拆解为两项
其中第二项是个需要单独训练的分类器,其分类的梯度score用来更新扩散的输出。其中作者每一步扩散的时候都使用了多次梯度更新计算(3次adagrad),为了加速解码作者将扩散步数T由2000步下降为200步。
至此这篇论文的核心要点笔者认为已经梳理完成。但笔者对这篇论文有几点质疑。
作者提到该扩散模型的速度比自回归式的预训练模型慢了7倍。但笔者试跑了一下作者代码发现,用transformer做初始词的误差估计,并且做200次去噪过程。实际生成一个句子在A100显卡上要花4-5分钟,是自回归式生成类似长度的句子所耗时间的数十倍。
作者给的源代码十分混乱,难以阅读和使用。但笔者对于其提到的即在有引导的条件生成上表现良好,又在无引导的开放生成上表现突出持保留态度。该质疑主要来源于笔者在非自回归模型里的一些感性经验。该扩散模型的主要优化目标是每个潜在向量与其词嵌入的预测误差。似乎并没有对句子的整体性有任何的要求。甚至就连P(w|x0)文章采取的建模方式也是每个字词的概率的独立连乘。这样强假设先验下的建模方式对模型能力要求很高。可能在小数据集小领域上可以达到较好效果,但复杂的文本领域恐怕难以建模。笔者按照作者的开源代码所训练出的结果也不理想。但存在笔者简单尝试下误用的可能。
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
笔者自身对使用预训练模型作为基底的VAE生成模型比较熟悉,也一直在思考扩散模型和文本生成的最佳方式是什么。Diffusion-LM在笔者看来仍有几个缺陷,其中比较大的一个是没有显式建模全句的生成质量。这点也是笔者自身想实验的点。另一个是其生成需要预先固定长度再开始去噪生成极大地限制了使用场景。
恰好最近发现了这篇text control with ODE论文。笔者认为在技术路线上,该论文比Diffusion-LM更为自洽和完善。一方面该论文是在VAE里的潜在空间上做扩散,同样是在连续空间上做扩散,该方法避免了Diffusion-LM仍需要训练词嵌入并且引发的一系列优化技巧(包括损失函数的增添项,clamp trick等)。该论文的做法使得扩散过程仅仅在一个低维的连续空间上负责文本性质的控制。而在使得潜在向量具有相应的性质后,再将潜在向量交由解码器去生成文本。这样做有三个好处。一方面,该做法避免了Diffusion-LM的定长生成的限制,另一方面因为文本生成依然交由自回归解码器生成,文本通畅程度也得到了一定保证。最重要的是,类似于stable-diffusion的出圈, diffusion+VAE这种做法相比diffusion-LM快了将近两个数量级!
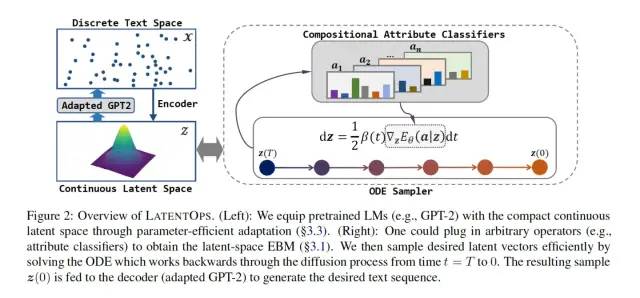
论文的核心流程图
对于扩散的具体流程来说,如果给定一个向量a={a_1, a_2, ..., a_n}为我们所希望拥有的所有性质的值的向量,并且规定f_i 为一个判断潜在向量z是否拥有相关性质a_i的能量模型(Energy-Based-Model)。那么我们可以得到以下表达式:
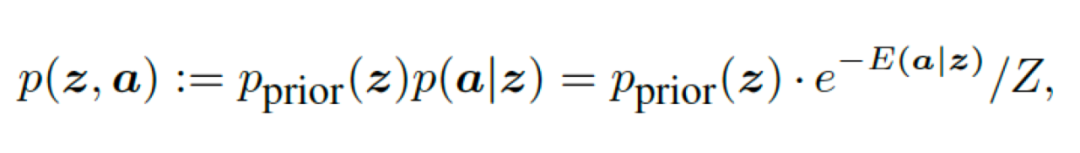 其中假定f_i为输出玻尔兹曼分布的能量模型
其中假定f_i为输出玻尔兹曼分布的能量模型
其中Pprior是VAE的高斯先验分布,而E(a|z)是定义在整个性质向量上的能量函数,其形式可以拆解为每个性质的能量函数的加权和。
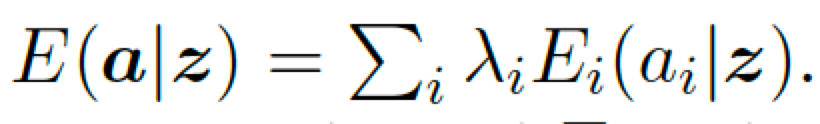 对性质向量的能量函数可以定义为对每个性质的能量函数的加权和
对性质向量的能量函数可以定义为对每个性质的能量函数的加权和
并且每个能量函数都会以以下形式正则化以避免尺度差异。
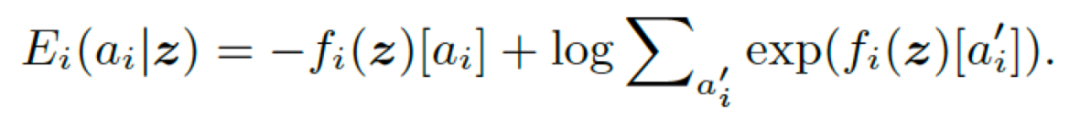 这是负的对数似然函数的表达式(normalized logits)
这是负的对数似然函数的表达式(normalized logits)
注意对于扩散的起点P(T)来说,这是个标准的高斯分布,而扩散的终点P(0)是我们所定义的VAE的高斯先验,也是标准高斯分布。那么实际上我们扩散的每一步Pt(z)都服从标准高斯分布。将P(z), P(a|z)代入我们的ODE采样表达式后我们可以得到以下的ODE表达式
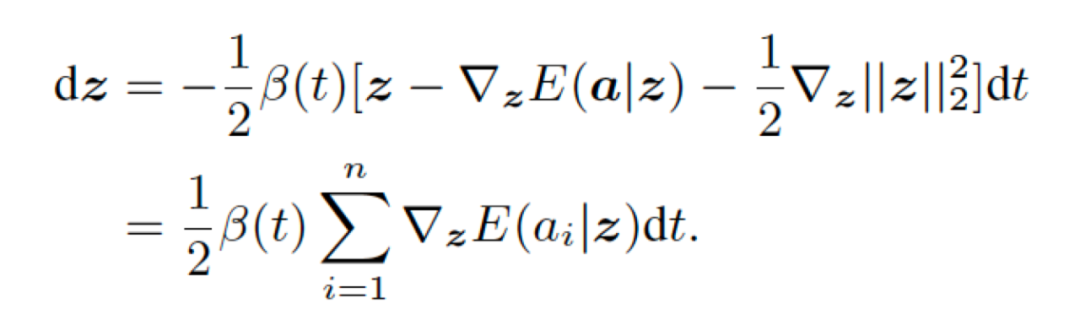 该扩散过程的ODE解
该扩散过程的ODE解
那么整个扩散采样的流程就很确定了。如果是生成新文本类的任务,我们先从高斯先验中采样一个潜在向量Z,然后根据我们定义的能量模型的能量函数求解以上表达式。当然纯高斯先验与VAE的后验不可能完全贴合。所以作者训练了一个单层的GAN来近似VAE的后验网络以采样P(T)。而如果是修改已有句子的话就比较简单,直接通过VAE的encoder得到潜在向量z来作为P(T)。
本论文的主要贡献如上。那么该论文的VAE+Difussion的路线和普通的CVAE相比有什么差异呢:
CVAE 如果需要对某个性质做条件生成(如情感,关键词)需要大量数据对全量模型训练。但VAE+Diffusion不用,只需要固定VAE额外训练一个潜在向量的分类器做扩散引导即可。而在潜在向量上的分类器,首先维度低,参数量少,训练资源相比原预训练模型低几个数量级!并且所需的训练数据也极少(原论文仅使用200条训练)
CVAE难以做到性质聚合,往往需要对不同性质的条件生成单独训练且训练出来的模型难以有效地聚合。但VAE+Diffusion在理论上展现了这种可能(当然是否有效仍需具体观察)。
不过VAE+Diffusion的模式仍存在几个问题笔者觉得会导致条件生成的成功率不高,或者不如论文里“宣称”的那么高:
首先是分类器的准确度是需要考虑的问题。直接用VAE里的潜在向量去做分类而不是BERT的CLS去做分类笔者与笔者的同事做过相关实验。准确率相比CLS分类是有较为明显的下降的。这样的下降必然会影响扩散引导的效果。
其次是解码器生成时的采样策略必然会导致一定的随机性存在。哪怕是笔者自身训练的CVAE,在做特定的条件生成时往往也需要对同一个潜在向量重复采样以保证条件生成满足相关性质。
再次是关于多个条件聚合时,不同性质的条件聚合是否会出现明显的互相干扰,是否需要手动调整各个性质的比重系数也值得考虑。
自身实践
笔者根据论文DELLA
[1]
复现训练了一个由两个Transformer-XL组成的VAE(其中transformer的每一层都会出一个潜在向量Z),根据上篇论文对一个电商正负情感评论的分类数据集做了以下几个步骤:
根据有标签数据集生成一批带标签的Latent-Vec数据
用这些带有特定性质的Latent-Vec训练一个情感二分类器
已知扩散过程的起点(Encoder的输出)和终点(带标签的Latent-vec)用分类器进行Nueral-ODE扩散。
其中笔者发现:
分类器的准确度的确不高,最高只能达到八成左右(分类器的架构没有进行太多探索,只尝试了MLP的一些超参调整)。分类器虽然准确率一般但对性质改变已经足够。
生成的潜在向量确定性比较高,且速度很快。相比于Diffusion-LM需要5分钟左右的扩散时间生成一句话,VAE+diffusion的做法只需要几秒钟。
原句1(负面):呵呵了 这物流速度也是没谁了 同城网购竟然三天了还不到。
改写句1:呵呵了 这物流速度也是没谁了 同城网购居然还可以很不错 哈哈.
原句2(正面): 还不错,等试用一段时间再说
改写句2: 还不行,等试用一段时间再说
原句3(负面): 买错了,自己是荣耀7,悲哀了,不管商家的事,鬼火绿
改写句3:买对了,自己是荣耀7,呵呵,感谢商家的事,快乐了,不管火鬼绿
原句4(负面):一次很差的购物 手机到手后 没仔细检查 晚上检查发现手机背面有划痕联系了客服说换 但是 后面他们打电话说不能更换 反正就是各种各样的借口
改写句4: 一次很漂亮的购物 手机上检查 后手机没受划 具体使用体验可以打电话客服询问 后来她说我不错 而且说都是精心计划 以后说但是一定要注意换三端的电话 感觉没有各种各样的借口
参考资料:
^
DELLA
https://arxiv.org/abs/2207.06130
https://zhuanlan.zhihu.com/p/561233665
本文来自知乎答主
中森,若进行二次转载
,向原作者进行申请。


评论