
Pandas用的6不6,来试试这道题就能看出来
导读
近日,在实际工作中遇到了这样一道数据处理的实际问题,凭借自己LeetCode200+算法题和Pandas熟练运用一年的功底,很快就完成了。特此小结,以资后鉴!
题目描述:给定一组用户的多次行为起止时间表,由于相邻行为之间可能存在交叉(即后一行为的开始时间可能早于前一行为的结束时间),所以需根据用户ID对其相应的起止时间信息进行合并处理。不失一般性,模拟示例数据如下:
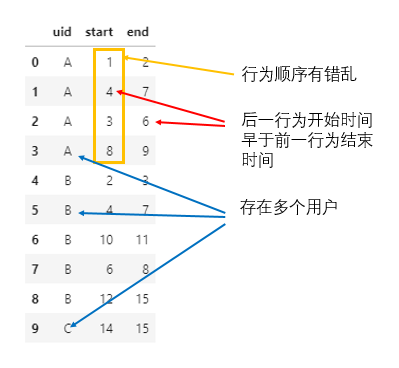
在上述示例数据中,用户A和用户B的多组行为间,均存在一定的起止时间交叉,例如用户A的两个行为起止时间分别为[3, 6]和[4, 7](同时,这里的两组行为开始时间先后顺序还是错的),存在交叉,所以可合并为[3, 7];类似地,用户B的两个行为起止时间分别为[4, 7]和[6, 8],也可合并为[4, 8]。
为完成以上这一小需求,实际上可拆解为两个小问题:
给定同一用户的多组行为起始时间,根据起止时间的大小完成区间合并问题。实际上,这是LeetCode的一道原题
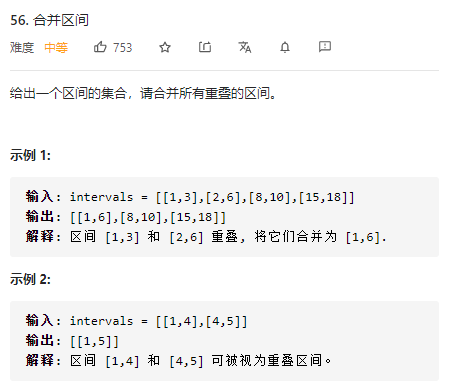
图片源自LeetCode56题截图
在完成单个用户区间合并的基础上,如何处理多用户的区间合并以及最后结果的拼接问题。用Pandas的思维来讲,自然就是groupby的过程:split—aggregate(range combine)—union
1def range_combine(starts, ends):
2 # 在starts有序的前提下,完成区间合并
3 combines = []
4 for start, end in zip(starts, ends):
5 if not combines or start > combines[-1][1]:
6 combines.append([start, end])
7 else:
8 combines[-1][1] = max(combines[-1][1], end)
9 return combines
10# 测试样例
11starts = [1, 3, 4, 8]
12ends = [2, 6, 7, 9]
13range_combine(starts, ends)
14# 输出 [[1, 2], [3, 7], [8, 9]]

进而,可以完成各用户多个行为起止区间分裂成多行的过程,具体实现如下:
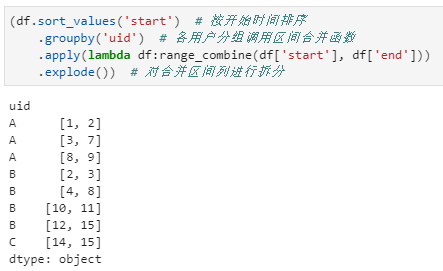

一个现实需求,对应多个数据处理小技巧,这真是实践出真知啊!
相关阅读:
评论