
分析《演员请就位2》45万条弹幕,看看大家都在吐槽什么?

导读:今天教大家用Python分析《演员请就位2》的弹幕数据。



弹幕数据获取 数据读入和数据预处理 数据可视化
# 导入库
import os
import jieba
import numpy as np
import pandas as pd
from pyecharts.charts import Bar, Pie, Line, WordCloud, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image # 用于在jupyter lab中显示本地图# 读入数据
data_list = os.listdir('../data/')
df_all = pd.DataFrame()
for i in data_list:
# print(i)
df_one = pd.read_csv(f'../data/{i}', engine='python', encoding='utf-8', index_col=0)
df_all = df_all.append(df_one, ignore_index=False)
df_all.info() <class 'pandas.core.frame.DataFrame'>
Int64Index: 449762 entries, 0 to 44317
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 episodes 449762 non-null object
1 comment_id 449762 non-null int64
2 oper_name 183066 non-null object
3 vip_degree 449762 non-null int64
4 content 449762 non-null object
5 time_point 449762 non-null int64
6 up_count 449762 non-null int64
dtypes: int64(4), object(3)
memory usage: 27.5+ MBdf_all.head()

# 删除弹幕角色
df_all['content'] = df_all['content'].str.replace('(.*?:)', '')
df_all.head() 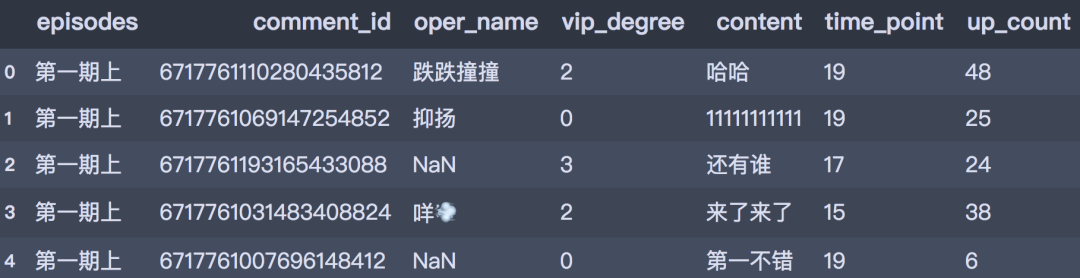
弹幕走势图

df_epinum = df_all['episodes'].value_counts().reset_index()
df_epinum['num'] = [1, 5, 3, 7, 6, 8, 4, 9, 2, 10]
df_epinum = df_epinum.sort_values('num')
df_epinum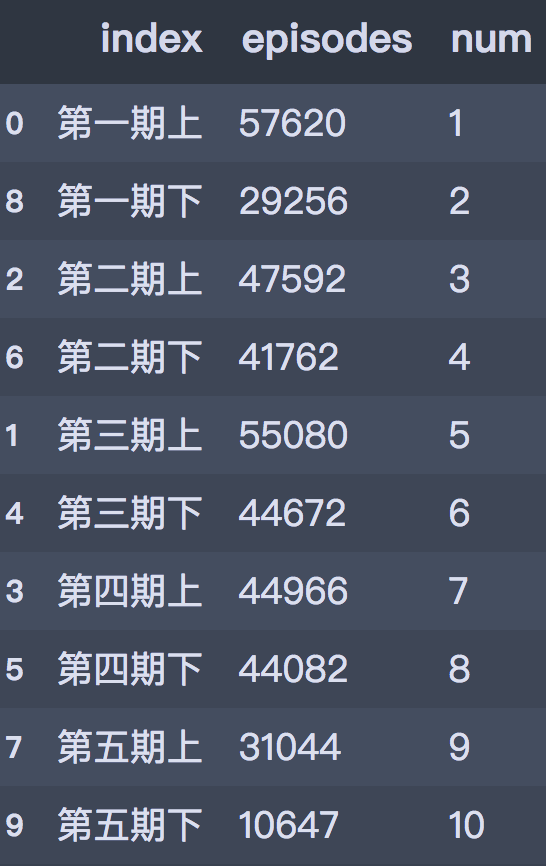
x_data = df_epinum['index'].tolist()
y_data = df_epinum['episodes'].tolist()
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(xaxis_data=x_data)
bar1.add_yaxis('', y_axis=y_data)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='前五期的弹幕数走势图'),
visualmap_opts=opts.VisualMapOpts(max_=60000, is_show=False)
)
bar1.render() 人物弹幕词云






评论