
用Python分析《令人心动的offer2》的13万条弹幕,网友们都在吐槽什么?
前言
大家好,我是kuls。
今天推荐给大家一篇文章!
综艺,是我们劳累了一天的放松方式,也是我们饭后的谈资。看着自己喜欢的综艺,时光足够美。而《令人心动的offer》,就是一个不错的综艺选择。
《令人心动的offer》目前为止已经播出了两季,第一季在豆瓣为8.3分,共有5万余人评分,第二季目前评分低于第一季,评分仅7.1分。
 本文通过爬取《令人心动的offer》第二季13万+弹幕,进行可视化分析和情感分析,完整代码后台回复「offer」即可免费获取。
本文通过爬取《令人心动的offer》第二季13万+弹幕,进行可视化分析和情感分析,完整代码后台回复「offer」即可免费获取。
数据获取
《令人心动的offer》第二季在腾讯视频独家播出,目前已播出四期(含面试篇),本文采取分集爬取。以下以爬取面试篇弹幕为例,并给出完整代码:
#-*- coding = uft-8 -*-
#@Time : 2020/11/30 21:35
#@Author : 公众号 菜J学Python
#@File : tengxun_danmu.py
import requests
import json
import time
import pandas as pd
target_id = "6130942571%26" #面试篇的target_id
vid = "%3Dt0034o74jpr" #面试篇的vid
df = pd.DataFrame()
for page in range(15, 3214, 30): #视频时长共3214秒
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={0}&target_id={1}vid{2}&count=80'.format(page,target_id,vid)
print("正在提取第" + str(page) + "页")
html = requests.get(url,headers = headers)
bs = json.loads(html.text,strict = False) #strict参数解决部分内容json格式解析报错
time.sleep(1)
#遍历获取目标字段
for i in bs['comments']:
content = i['content'] #弹幕
upcount = i['upcount'] #点赞数
user_degree =i['uservip_degree'] #会员等级
timepoint = i['timepoint'] #发布时间
comment_id = i['commentid'] #弹幕id
cache = pd.DataFrame({'弹幕':[content],'会员等级':[user_degree],'发布时间':[timepoint],'弹幕点赞':[upcount],'弹幕id':[comment_id]})
df = pd.concat([df,cache])
df.to_csv('面试篇.csv',encoding = 'utf-8')
分别爬取完成后,将四个弹幕csv文件放入一个文件夹中。 打开面试篇csv文件,预览如下:
打开面试篇csv文件,预览如下: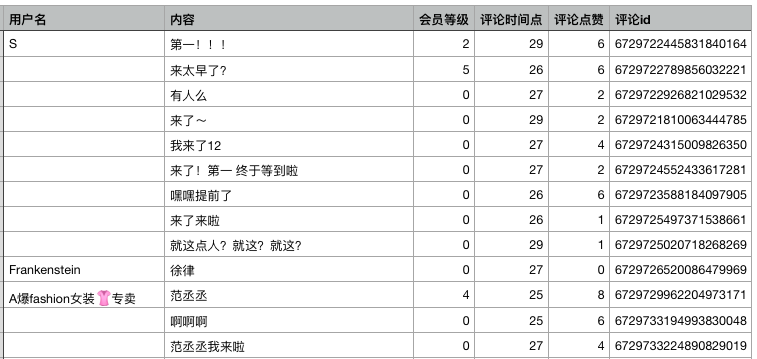
数据清洗
合并弹幕数据
首先,将四个弹幕csv文件进行数据合并,采用concat方法。
import pandas as pd
import numpy as np
df1 = pd.read_csv("/菜J学Python/弹幕/腾讯/令人心动的offer/面试篇.csv")
df1["期数"] = "面试篇"
df2 = pd.read_csv("/菜J学Python/弹幕/腾讯/令人心动的offer/第1期.csv")
df2["期数"] = "第1期"
df3 = pd.read_csv("/菜J学Python/弹幕/腾讯/令人心动的offer/第2期.csv")
df3["期数"] = "第2期"
df4 = pd.read_csv("/菜J学Python/弹幕/腾讯/令人心动的offer/第3期.csv")
df4["期数"] = "第3期"
df = pd.concat([df1,df2,df3,df4])
预览下合并后的数据:
df.sample(10)
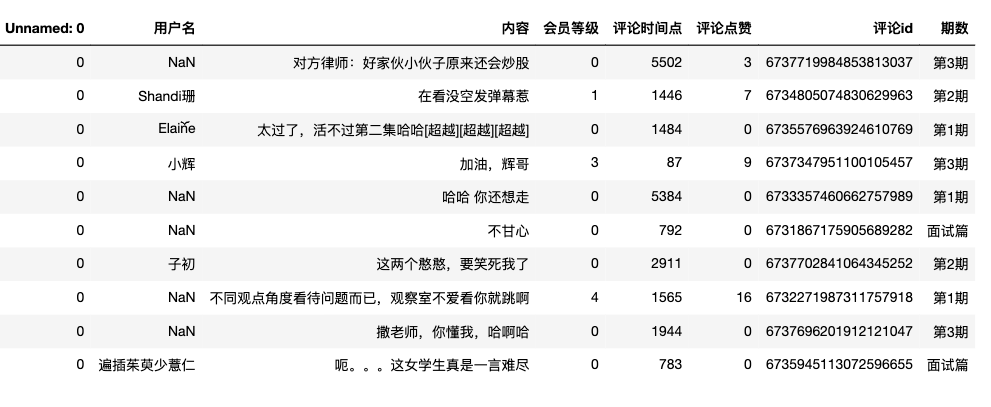
查看数据信息
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 133627 entries, 0 to 34923
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 133627 non-null int64
1 用户名 49040 non-null object
2 内容 133626 non-null object
3 会员等级 133627 non-null int64
4 评论时间点 133627 non-null int64
5 评论点赞 133627 non-null int64
6 评论id 133627 non-null int64
7 期数 133627 non-null object
dtypes: int64(5), object(3)
memory usage: 9.2+ MB
发现数据存在以下几个问题:1.字段名称可调整(个人洁癖)2.Unnamed字段多余
3.用户名字段有缺失值,可填充
4.内容和评论时间点字段类型需要调整
5.评论id对分析无意义,可删除
重命名字段
df = df.rename(columns={'用户名':'用户昵称','内容':'弹幕内容','评论时间点':'发送时间','评论点赞':'弹幕点赞','期数':'所属期数'})
过滤字段
#选择需要分析的字段
df = df[["用户昵称","弹幕内容","会员等级","发送时间","弹幕点赞","所属期数"]]
缺失值处理
df["用户昵称"] = df["用户昵称"].fillna("无名氏")
发送时间处理
发送时间字段是秒数,需要改成时间,这里自定义一个time_change函数进行处理。
def time_change(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
ss_time = "%d:%02d:%02d" % (h, m, s)
print(ss_time)
return ss_time
time_change(seconds=8888)
将time_change函数应用于发送时间字段:
df["发送时间"] = df["发送时间"].apply(time_change)
设置为需要的时间格式:
df['发送时间'] = pd.to_datetime(df['发送时间'])
df['发送时间'] = df['发送时间'].apply(lambda x : x.strftime('%H:%M:%S'))
弹幕内容处理
将object数据类型更改为str:
df["弹幕内容"] = df["弹幕内容"].astype("str")
机械压缩去重:
#定义机械压缩函数
def yasuo(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k k = k + i
st = st[:j] + st[k:]
return st
yasuo(st="菜J学Python真的真的真的很菜很菜")
#调用机械压缩函数
df["弹幕内容"] = df["弹幕内容"].apply(yasuo)
特殊字符过滤:
df['弹幕内容'] = df['弹幕内容'].str.extract(r"([\u4e00-\u9fa5]+)") #提取中文内容
df = df.dropna() #纯表情弹幕直接删除
清洗后数据预览如下: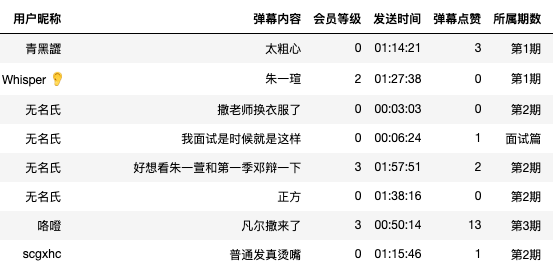
数据分析
各期弹幕数量对比
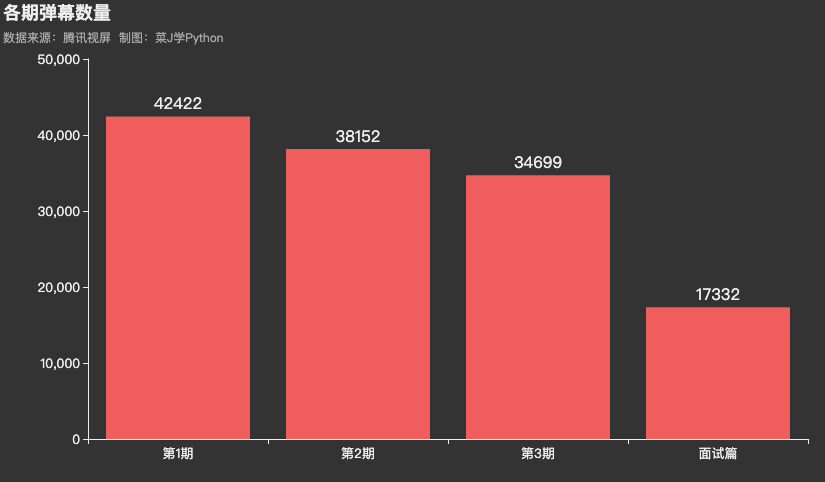
《令人心动的offer》第二季已播出四期(含面试篇),第1期:规则升级,实习生面临高压考核弹幕数量最多,达到42422个,面试篇:实习生面试遭灵魂拷问弹幕数量最少,仅为17332个。
import pyecharts.options as opts
from pyecharts.charts import *
from pyecharts.globals import ThemeType
df7 = df["所属期数"].value_counts()
print(df7.index.to_list())
print(df7.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df7.index.to_list())
.add_yaxis("",df7.to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="各期弹幕数量",subtitle="数据来源:腾讯视屏 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
)
c.render_notebook()
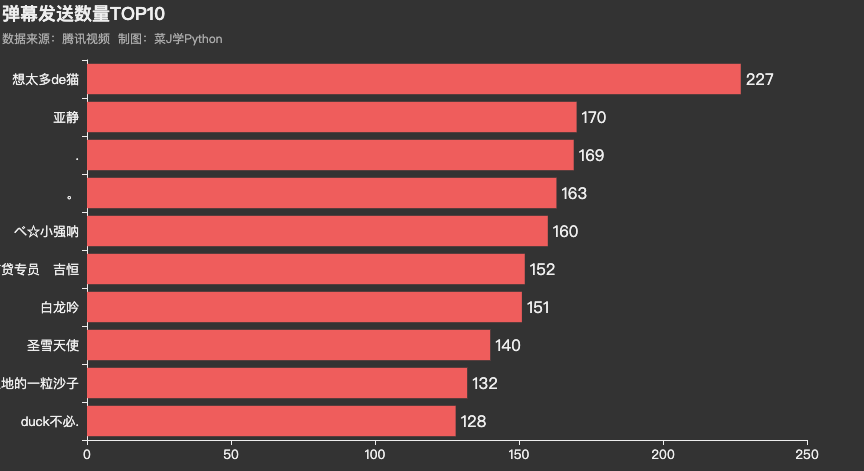
谁是弹幕发射机
用户昵称为想太多de猫几期下来共发射弹幕227个,遥遥领先其他弹幕党,名副其实的弹幕发射机。
df8 = df["用户昵称"].value_counts()[1:11]
df8 = df8.sort_values(ascending=True)
df8 = df8.tail(10)
print(df8.index.to_list())
print(df8.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df8.index.to_list())
.add_yaxis("",df8.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="弹幕发送数量TOP10",subtitle="数据来源:腾讯视频 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
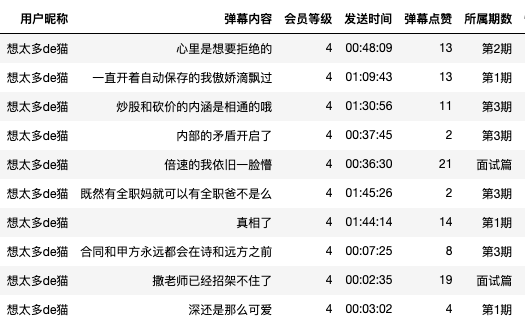
 随机抽取想太多de猫弹幕信息,发现其对《令人心动的offer》第二季爱的深沉。弹幕内容透露出其观看视频还是相当之认真,几乎每个弹幕都获得了一定的点赞。
随机抽取想太多de猫弹幕信息,发现其对《令人心动的offer》第二季爱的深沉。弹幕内容透露出其观看视频还是相当之认真,几乎每个弹幕都获得了一定的点赞。
df[df["用户昵称"]=="想太多de猫"].sample(10)
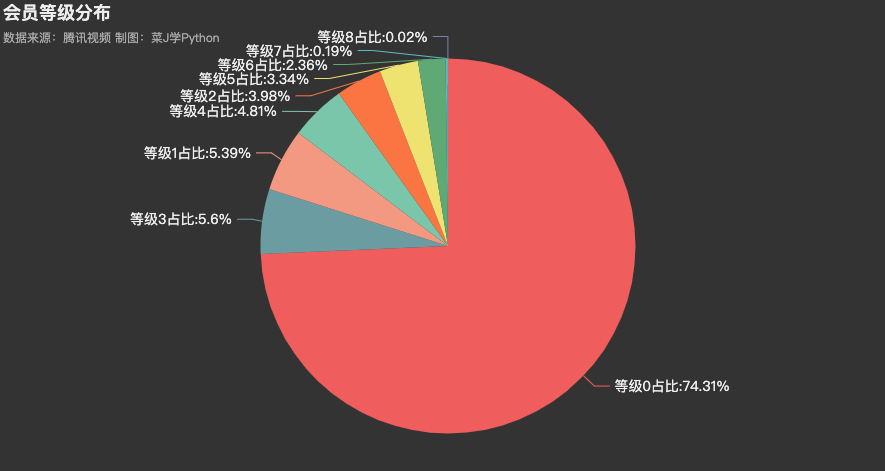
会员等级分布
在观看《令人心动的offer》第二季的观众中,高达74.31%的用户和J哥一样不是腾讯视频的会员,占比第二的会员等级3占5.6%,共计7419人,占比第三的会员等级1占5.39%,共计7153人。
df2 = df["会员等级"].astype("str").value_counts()
print(df2)
df2 = df2.sort_values(ascending=False)
regions = df2.index.to_list()
values = df2.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add("", list(zip(regions,values)))
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False),title_opts=opts.TitleOpts(title="会员等级分布",subtitle="数据来源:腾讯视频\t制图:菜J学Python",pos_top="0.5%",pos_left = 'left'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="等级{b}占比:{d}%",font_size=14))
)
c.render_notebook()
弹幕在讨论些什么
通过对13+弹幕制作词云图,我们发现,弹幕中出现频率较高的词汇有「丁辉、律师、喜欢、加油、徐律、干饭、撒老师」等。丁辉作为8个实习生里本科学校最差、年龄最大的成员,从一开始就被观众所热议。徐律作为第1季的带教导师,其雷厉风行又知性温柔的风范,早已赢得广大观众的喜爱。干饭作为最近非常热门的网络词汇,出现在热播综艺中也不足为奇。而撒老师作为这一季的搞笑担当和凡尔赛担当,也被广大观众所热议。
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("/菜J学Python/offer/stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['撒老师', '范丞丞','第一季']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['好像', '真的','感觉']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=df['弹幕内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=100,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-square',
size=653,
#palette='matplotlib.Inferno_9',
output_name='./offer.png')
Image(filename='./offer.png')

大家如何评论8个实习生
我们首先看下8位实习生的照片:

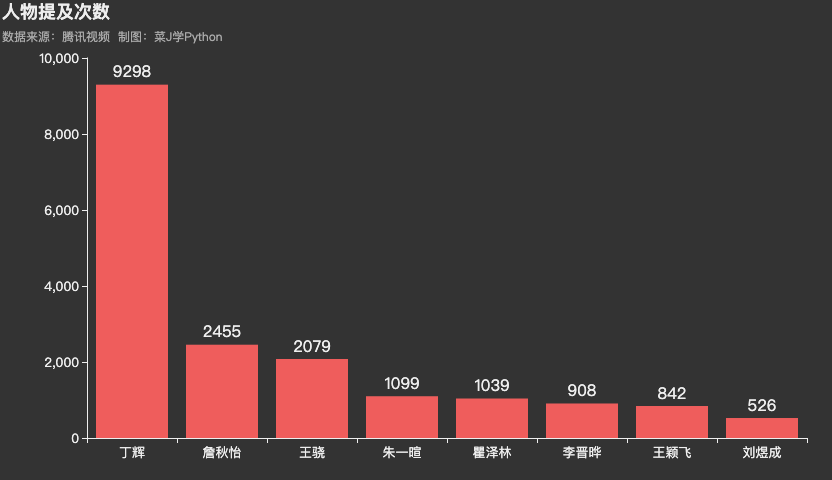
在所有弹幕中,丁辉被观众提及次数远超过另外7个实习生,共计9298次,其次是詹秋怡,被观众提及2455次,刘煜成被观众提及最少,仅有526次。
df8 = df["人物提及"].value_counts()[1:11]
print(df8.index.to_list())
print(df8.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df8.index.to_list())
.add_yaxis("",df8.to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="人物提及次数",subtitle="数据来源:腾讯视频 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
)
c.render_notebook()
 分别绘制8个实习生的弹幕词云图,我们发现,还是有很多观众认可「丁辉」的,「加油、喜欢、看好、支持」等词出现频率较高;对于性格较为内向的詹秋怡,观众也非常喜欢,从「漂亮、刘亦菲、好看」等高频词可看出,不少人喜欢她是基于颜值;作为来自顶级学府斯坦福的王骁来说,观众呈现两边倒的局势,有人说「王骁好」,也有人认为他是「凡尔赛」;朱一暄也一样,有人觉得她很「可爱」,也有人「讨厌」她;瞿泽林则被表扬「情商高、可爱」;李晋晔的「帅气」被观众赞不绝口,甚至有很多人认为他很像第1季的人气实习生何运晨;人大毕业的王颖飞也被观众夸赞「好看、漂亮」;高分过司考的刘煜成被观众夸赞「专业知识不错」,由于在第3期中被王骁抢话,受了委屈,观众纷纷表示「心疼」。
分别绘制8个实习生的弹幕词云图,我们发现,还是有很多观众认可「丁辉」的,「加油、喜欢、看好、支持」等词出现频率较高;对于性格较为内向的詹秋怡,观众也非常喜欢,从「漂亮、刘亦菲、好看」等高频词可看出,不少人喜欢她是基于颜值;作为来自顶级学府斯坦福的王骁来说,观众呈现两边倒的局势,有人说「王骁好」,也有人认为他是「凡尔赛」;朱一暄也一样,有人觉得她很「可爱」,也有人「讨厌」她;瞿泽林则被表扬「情商高、可爱」;李晋晔的「帅气」被观众赞不绝口,甚至有很多人认为他很像第1季的人气实习生何运晨;人大毕业的王颖飞也被观众夸赞「好看、漂亮」;高分过司考的刘煜成被观众夸赞「专业知识不错」,由于在第3期中被王骁抢话,受了委屈,观众纷纷表示「心疼」。
情感分析
通过运用百度开源NLP对弹幕内容进行情感分值计算,我们发现,《令人心动的offer》第二季整体情感分值高于0.5,观众表现出较高的积极倾向。会员等级较高的观众越能坚持观看到最后,弹幕点赞量从视频播放开始呈增长趋势,在最后15分钟时骤降。情感分值则表现为视频播放首尾高,中间低。
import paddlehub as hub
#这里使用了百度开源的成熟NLP模型来预测情感倾向
senta = hub.Module(name="senta_bilstm")
texts = df['弹幕内容'].tolist()
input_data = {'text':texts}
res = senta.sentiment_classify(data=input_data)
df['情感分值'] = [x['positive_probs'] for x in res]
#重采样至15分钟
df.index = df['发送时间']
data = df.resample('15min').mean().reset_index()
#给数据表添加调色板
import seaborn as sns
color_map = sns.light_palette('orange', as_cmap=True) #light_palette调色板
data.style.background_gradient(color_map)

c = (
Line(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(data["发送时间"].to_list())
.add_yaxis('情感倾向', list(data["情感分值"].round(2)), is_smooth=True,is_connect_nones=True,areastyle_opts=opts.AreaStyleOpts(opacity=0.5))
.set_global_opts(title_opts=opts.TitleOpts(title="情感倾向",subtitle="数据来源:腾讯视频 \t制图:菜J学Python",pos_left = 'left'))
)
c.render_notebook()

恋习Python 关注恋习Python,Python都好练 好文章,我在看❤️