
《演员请就位2》弹幕的情感倾向分析

文 | 某某白米饭
来源:Python 技术「ID: pythonall」

最近小编的娱乐公众号被《演员请就位2》刷屏了,这部综艺的从开播开始导演的热搜话题就一直不断,我们用 Python 分析一下这部综艺的视频弹幕看看大家都在吐糟些什么。
弹幕抓取
在腾讯视频打开最新的第 8 期的上下两期,在 Network 面板中搜索【danmu】,找到弹幕的链接 (https://mfm.video.qq.com/danmu?otype=json....)
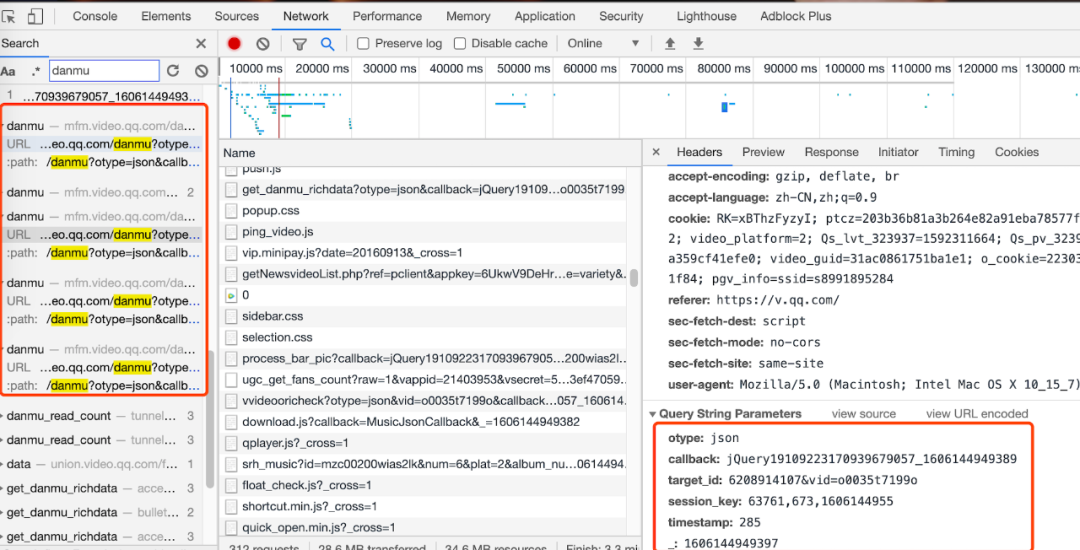
分析其中的请求参数可以发现只有 timestamp 参数在以每次 30 的数字递增,盲猜一波应该是视频每 30 秒获取一次弹幕包,其他的请求参数可以保持不变
import csv
import requests
import json
import time
from pathlib import Path
def danmu():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36'
}
# 弹幕链接,视频长度(秒)
urls = [['https://mfm.video.qq.com/danmu?otype=json&callback=&target_id=6208914107%26vid%3Do0035t7199o&session_key=63761%2C673%2C1606144955×tamp={}&_=1606144949402', 7478],
['https://mfm.video.qq.com/danmu?otype=json&callback=&target_id=6208234802%26vid%3Da00352eyo25&session_key=111028%2C1191%2C1606200649×tamp={}&_=1606200643186', 8610]]
for url in urls:
for page in range(15, url[1], 30):
u = url[0].format(page)
html = requests.get(u, headers=headers)
result = json.loads(html.text, strict=False)
time.sleep(1)
danmu_list = []
# 遍历获取目标字段
for i in result['comments']:
content = i['content'] # 弹幕内容
danmu_list.append([content])
print(content)
csv_write(danmu_list)
def csv_write(tablelist):
tableheader = ['弹幕内容']
csv_file = Path('danmu.csv')
not_file = not csv_file.is_file()
with open('danmu.csv', 'a', newline='', errors='ignore') as f:
writer = csv.writer(f)
if not_file:
writer.writerow(tableheader)
for row in tablelist:
writer.writerow(row)
抓到了 7W+ 的弹幕,文件为 3M 大小

情感分析
抓取到弹幕后,用腾讯云的情感分析 API 分析弹幕的情感倾向是正面的还是负面的亦或是中性情感
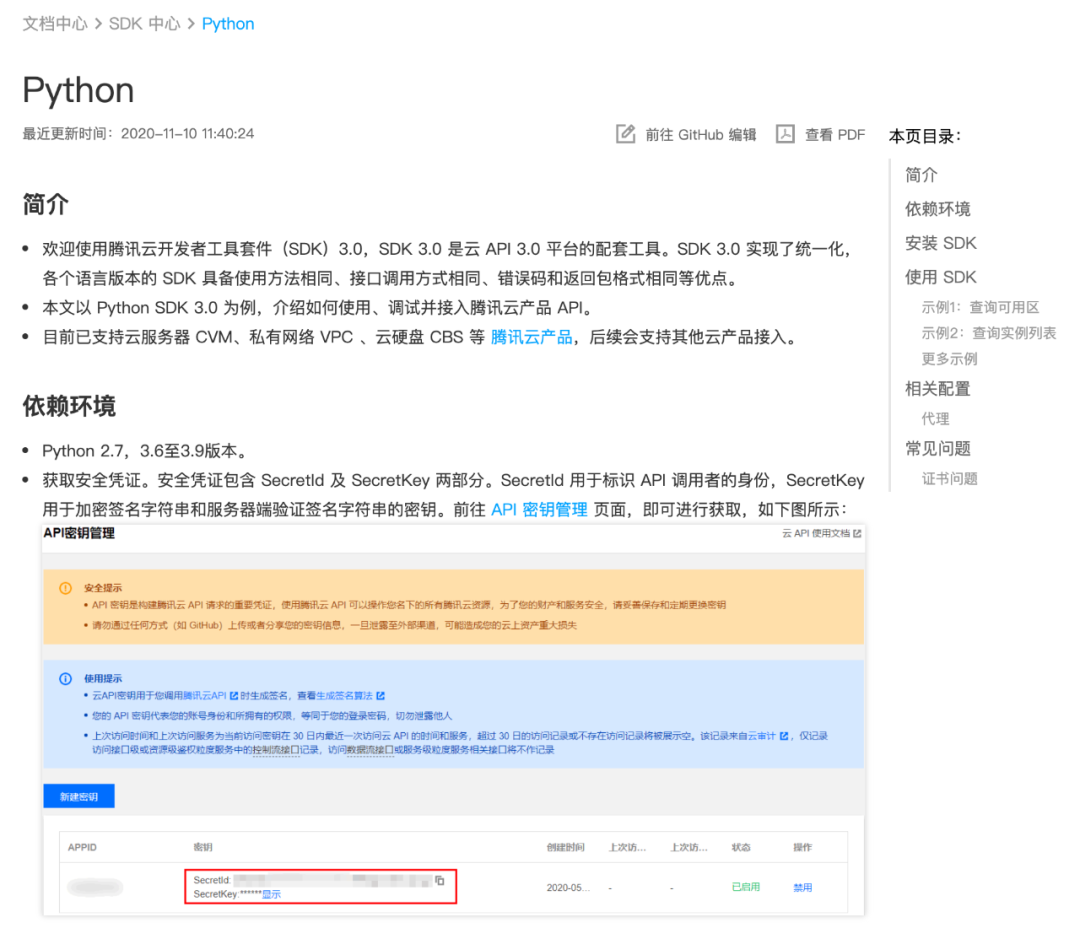
参考腾讯云 https://cloud.tencent.com/document/sdk/Python 页面获取 SecretId 和 SecretKey 安全凭证,用 pip install tencentcloud-sdk-python 安装腾讯云的 SDK,遇到证书错误时用 sudo "/Applications/Python 3.6/Install Certificates.command" 命令安装证书
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.nlp.v20190408 import nlp_client, models
import ssl
ssl._create_default_https_context=ssl._create_unverified_context
def nlp(text):
try:
cred = credential.Credential("xxx", "xxx")
httpProfile = HttpProfile()
httpProfile.endpoint = "nlp.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = nlp_client.NlpClient(cred, "ap-guangzhou", clientProfile)
req = models.SentimentAnalysisRequest()
params = {
"Text": text,
"Mode": "3class"
}
req.from_json_string(json.dumps(params))
resp = client.SentimentAnalysis(req)
sentiment = {'positive': '正面', 'negative': '负面', 'neutral': '中性'}
return sentiment[resp.Sentiment]
except TencentCloudSDKException as err:
print(err)
示例结果

导演好感度
对于频频上热搜的导演们观众对他们的感官是怎么样的,将情感分析结果转换成大家对各个导演评价的百分比,并用 pyecharts 制作成图表
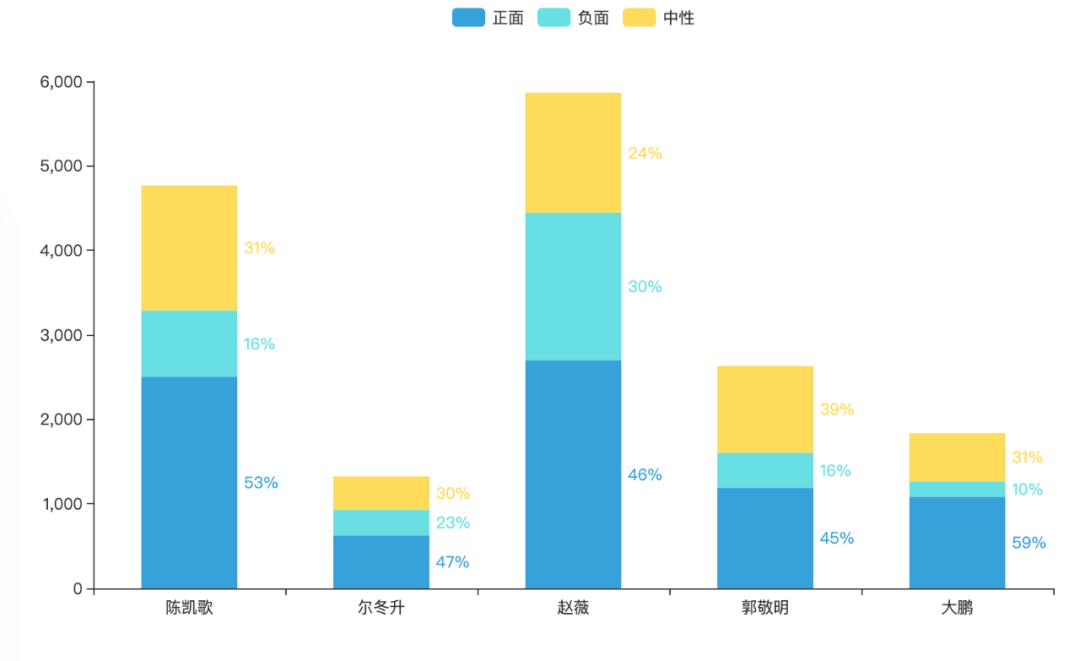
弹幕中对赵薇的负面评价达到 30%,尔冬升、赵薇、郭敬明的正面评价都差不多在 46% 左右,主持人大鹏的正面评价居然是最高的,达到 59%,赵薇的弹幕量最多、陈凯歌弹幕数量是第二个,尔冬升的弹幕量不到 2000
弹幕词云
将弹幕词云化,看看大家都在吐槽写什么

第一眼就看到了的秋裤两个字
def ciyun():
with open('danmu.csv') as f:
with open('ciyun.txt', 'a') as ciyun_file:
csv_reader = csv.reader(f)
for row in csv_reader:
ciyun_file.write(row[0])
# 构建并配置词云对象w
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path="/System/Library/fonts/PingFang.ttc",
collocations=False,
stopwords={'的', '了','啊','我','很','是','好','这','都','不'})
f = open('ciyun.txt', encoding='utf-8')
txt = f.read()
txtlist = jieba.lcut(txt)
result = " ".join(txtlist)
w.generate(result)
w.to_file('演员请就位2.png')
总结
腾讯视频弹幕的抓取比较简单,每隔 30 秒发送一次请求获取弹幕包。有兴趣的朋友可以尝试其他视频网站的弹幕抓取,一起努力进步天天向上。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】