
烂大街的Spring循环依赖该如何回答?
什么是循环依赖?
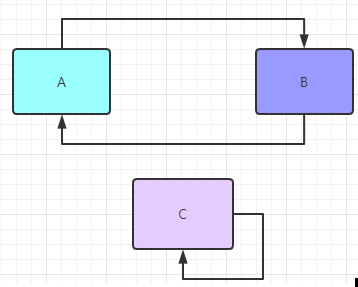 从字面上来理解就是
从字面上来理解就是A依赖B的同时B也依赖了A,就像上面这样,或者C依赖与自己本身。体现到代码层次就是这个样子
@Component
public class A {
// A中注入了B
@Autowired
private B b;
}
---
@Component
public class A {
// A中注入了B
@Autowired
private B b;
}
---
// 自己依赖自己
@Component
public class C {
// C中注入了C
@Autowired
private C c;
}
虽然体现形式不一样,但是实际上都是循环依赖的问题。
什么情况下循环依赖可以被处理?
Spring解决循环依赖是有前置条件的
出现循环依赖的Bean必须要是
单例(singleton),如果依赖prototype则完全不会有此需求。依赖注入的方式
不能全是构造器注入的方式(只能解决setter方法的循环依赖,这是错误的)
1. AB 均采用setter方法注入 结果OK

2. AB 均采用属性Autowired注入 结果ok
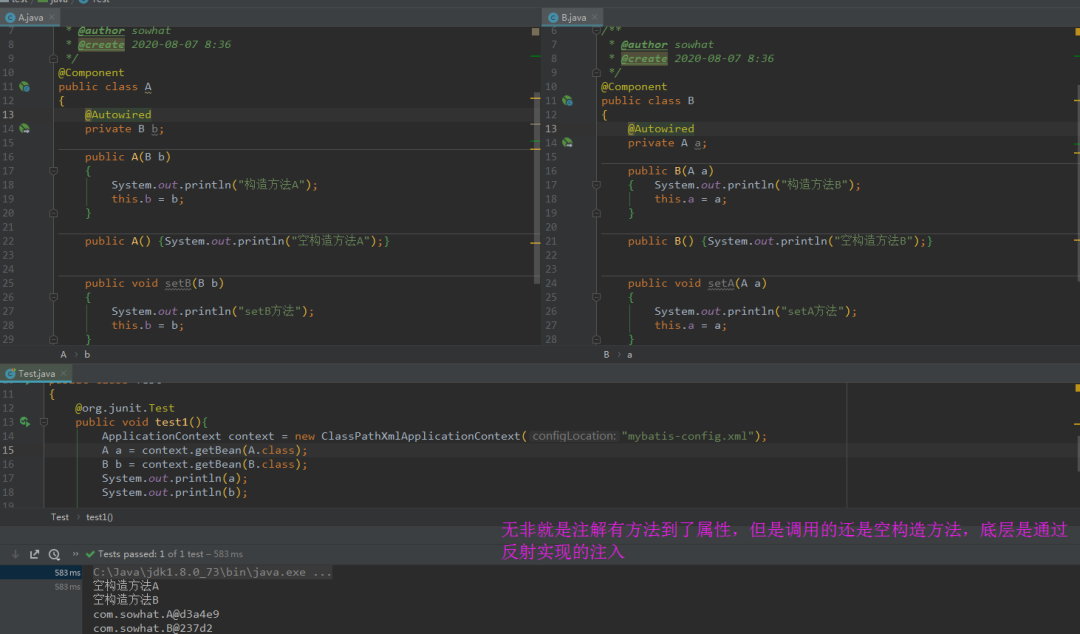
3. AB均采用构造器方法注入 出现循环依赖

4. A中注入B的方式为setter方法,B中注入A的方式为构造器

5. A中注入B的方式为构造器,B中注入A的方式为setter方法。

结论
| 依赖情况 | 依赖注入方式 | 是否解决 |
|---|---|---|
| AB相互依赖(循环依赖) | 均采用setter方法注入 | 是 |
| AB相互依赖(循环依赖) | 均采用属性自动注入 | 是 |
| AB相互依赖(循环依赖) | 均采用构造器注入 | 否 |
| AB相互依赖(循环依赖) | A中注入B的方式为setter方法,B中注入A的方式为构造器 | 是 |
| AB相互依赖(循环依赖) | B中注入A的方式为setter方法,A中注入B的方式为构造器,Spring在创建Bean时默认会根据自然排序进行创建,A会先于B进行创建 | 否 |
从上面的测试结果我们可以看到,不是只有在setter方法注入的情况下循环依赖才能被解决,即使存在构造器注入的场景下,循环依赖依然被可以被正常处理掉。
Spring循环依赖的通俗说
Spring bean 的创建,其本质上还是一个对象的创建,既然是对象,一定要明白一点就是,一个完整的对象包含两部分:当前对象实例化和对象属性的实例化。在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。这个过程可以按照如下方式进行理解: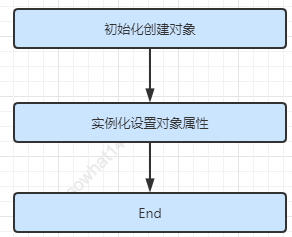 大致绘制依赖流程图如下:
大致绘制依赖流程图如下: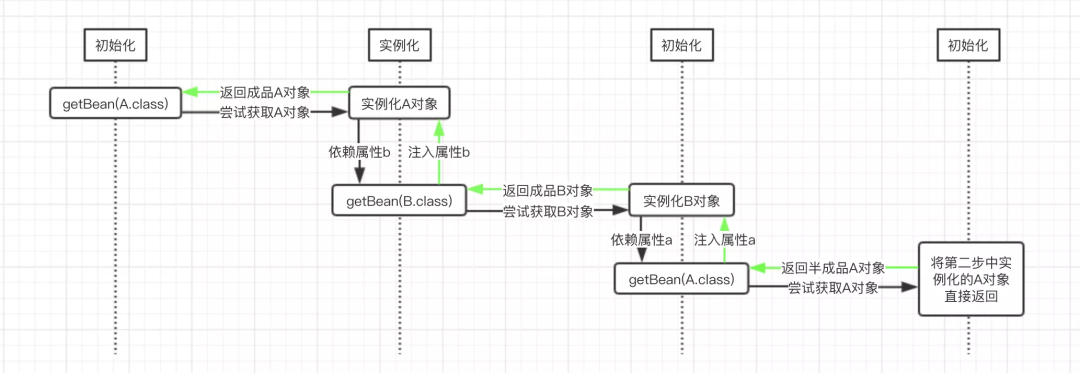 图中getBean()表示调用Spring的
图中getBean()表示调用Spring的ApplicationContext.getBean()方法,而该方法中的参数,则表示我们要尝试获取的目标对象。图中的黑色箭头表示一开始的方法调用走向,走到最后,返回了Spring中缓存的A对象之后,表示递归调用返回了,此时使用绿色箭头表示。从图中我们可以很清楚的看到,B对象的a属性是在第三步中注入的半成品A对象,而A对象的b属性是在第二步中注入的成品B对象,此时半成品的A对象也就变成了成品的A对象,因为其属性已经设置完成了。
到这里,Spring整个解决循环依赖问题的实现思路已经比较清楚了。对于整体过程只要理解两点:
Spring是通过递归的方式获取目标bean及其所依赖的bean的; Spring实例化一个bean的时候,是分两步进行的,首先实例化目标bean,然后为其注入属性。
结合这两点,也就是说,Spring在实例化一个bean的时候,是首先递归的实例化其所依赖的所有bean,直到某个bean没有依赖其他bean,此时就会将该实例返回,然后反递归的将获取到的bean设置为各个上层bean的属性的。
Spring循环依赖进阶
一个对象一般创建过程有3部分组成:
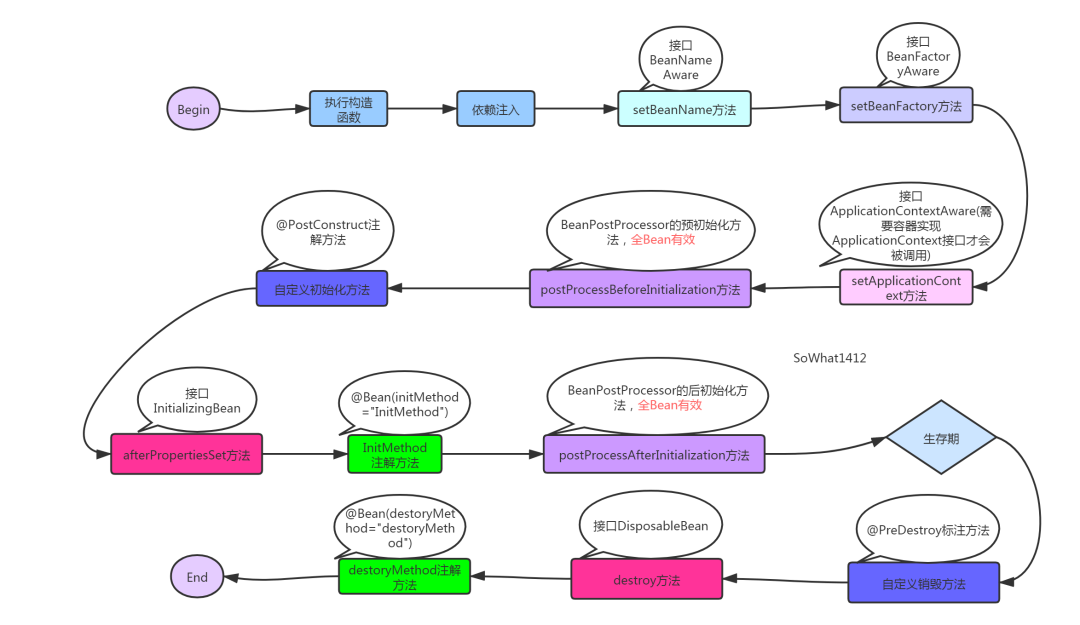
实例化:简单理解就是new了一个对象 属性注入:为实例化中new出来的对象填充属性 初始化:执行aware接口中的方法,初始化方法,完成AOP代理
Spring是通过「三级缓存」来解决上述问题的:
singletonObjects:一级缓存 存储的是所有创建好了的单例BeanearlySingletonObjects:完成实例化,但是还未进行属性注入及初始化的对象singletonFactories:提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象
然后接下来说下普通循环依赖跟带AOP的循环依赖。
普通循环依赖图
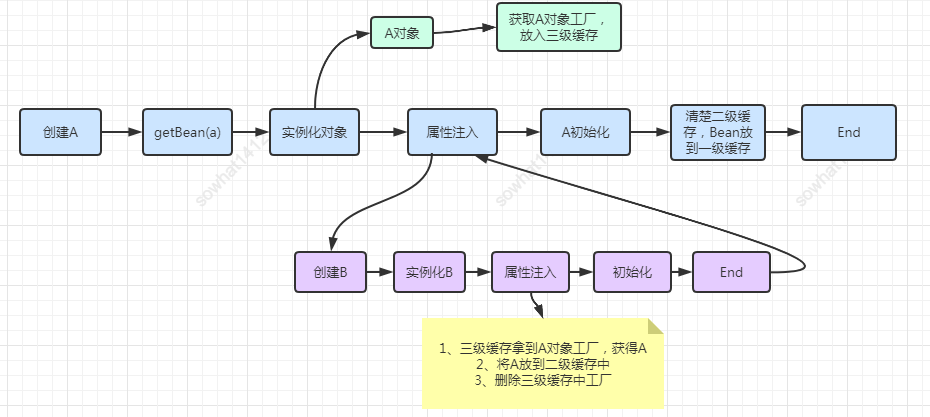 结论:没有进行AOP的Bean间的循环依赖 从上图分析可以看出,这种情况下「三级缓存根本没用」!所以不会存在什么提高了效率的说法
结论:没有进行AOP的Bean间的循环依赖 从上图分析可以看出,这种情况下「三级缓存根本没用」!所以不会存在什么提高了效率的说法
带AOP循环依赖
带AOP的跟不带AOP的其实几乎一样,只是在三级缓存中存放的是函数式接口,在需要调用时直接返回代理对象。三级缓存存在的意义:
❝只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
❞
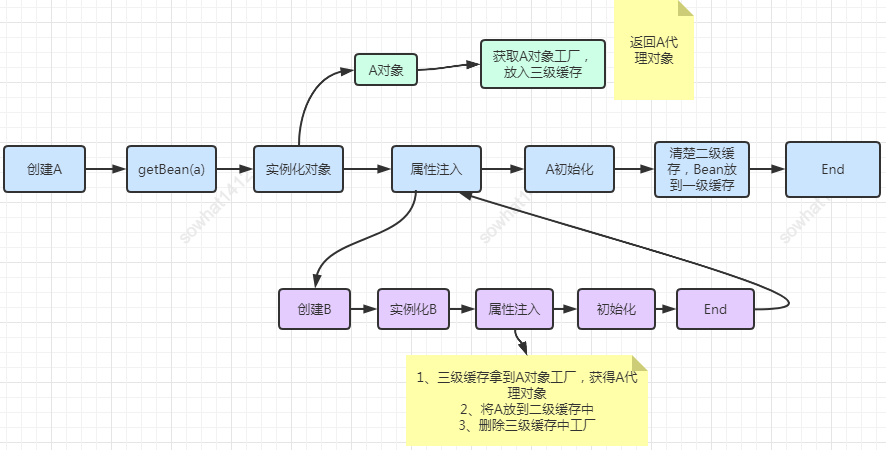
是否可以用二级缓存而不用三级缓存?
❝答案:不可以,违背Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期(看下图)本身就是通过
❞AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的「最后一步完成代理而不是在实例化后就立马完成代理」。
使用了三级缓存的情况下,A、B的创建流程  不使用三级缓存,直接在二级缓存中
不使用三级缓存,直接在二级缓存中 结论:上面两个流程的唯一区别在于为A对象创建代理的时机不同,使用三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。三级缓存是无法提速的!
结论:上面两个流程的唯一区别在于为A对象创建代理的时机不同,使用三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。三级缓存是无法提速的!
回答模板
Spring如何解决循环依赖的
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。
当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。
当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取:
❝第一步:先获取到三级缓存中的工厂;
第二步:调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。
第三步:当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
❞
面试官:为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?
❝答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样
❞违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
跟踪核心大致流程

参考
https://b23.tv/DiU5ut
题外话: 目前小哈正在个人博客(新搭建的网站,域名就是犬小哈的拼音) www.quanxiaoha.com 上更新《Go语言教程》,毕竟Go自带天然的并发优势,后端的同学还是要学一下的,这个教程系列小哈会一直更新下去,目前已经更新到 Go语言的基础语法了,欢迎小伙伴们访问哦~
END
有热门推荐?
1. Spring Boot 无侵入式 实现 API 接口统一 JSON 格式返回
2. Java8 Stream:2 万字 20 个实例,玩转集合的筛选、归约、分组、聚合
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
