
鹅厂练习13年Coding后,我悟了
👉导读
👉目录
01
一直以来,设计(Design)和架构(Architecture)这两个概念让大多数人十分迷惑--什么是设计?什么是架构?二者究竟有什么区别?二者没有区别。一丁点区别都没有!"架构"这个词往往适用于"高层级"的讨论中,这类讨论一般都把"底层"的实现细节排除在外。而"设计"一词,往往用来指代具体的系统底层组织结构和实现的细节。但是,从一个真正的系统架构师的日常工作来看,这些区分是根本不成立的。以给我设计新房子的建筑设计师要做的事情为例。新房子当然是存在着既定架构的,但这个架构具体包含哪些内容呢?首先,它应该包括房屋的形状、外观设计、垂直高度、房间的布局,等等。
但是,如果查看建筑设计师使用的图纸,会发现其中也充斥着大量的设计细节。譬如,我们可以看到每个插座、开关以及每个电灯具体的安装位置,同时也可以看到某个开关与所控制的电灯的具体连接信息;我们也能看到壁炉的具体位置,热水器的大小和位置信息,甚至是污水泵的位置;同时也可以看到关于墙体、屋顶和地基所有非常详细的建造说明。总的来说,架构图里实际上包含了所有的底层设计细节,这些细节信息共同支撑了顶层的架构设计,底层设计信息和顶层架构设计共同组成了整个房屋的架构文档。
软件设计也是如此。底层设计细节和高层架构信息是不可分割的。他们组合在一起,共同定义了整个软件系统,缺一不可。所谓的底层和高层本身就是一系列决策组成的连续体,并没有清晰的分界线。
02
03
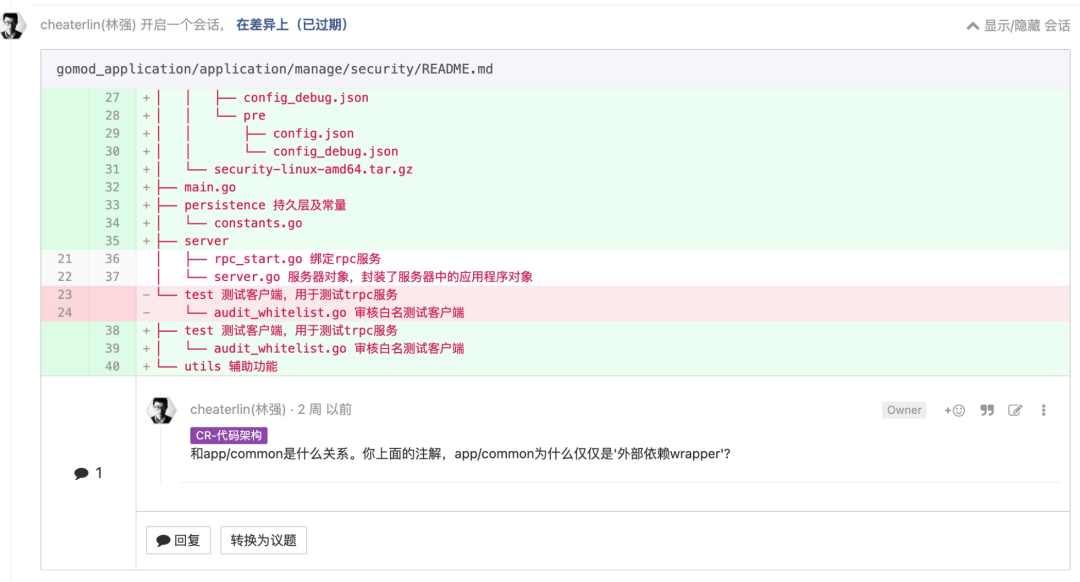
ETC 是一种价值观念,不是一条原则。价值观念是帮助你做决定的: 我应该做这个,还是做那个?当你在软件领域思考时,ETC 是个向导,它能帮助你在不同的路线中选出一条。就像其他一些价值观念一样,你应该让它漂浮在意识思维之下,让它微妙地将你推向正确的方向。
04
05
06
07
* 大铁块的组合
* 将程序运行在云虚拟机中大
* 最后,无可避免的,有些任务又回到了大铁块
08
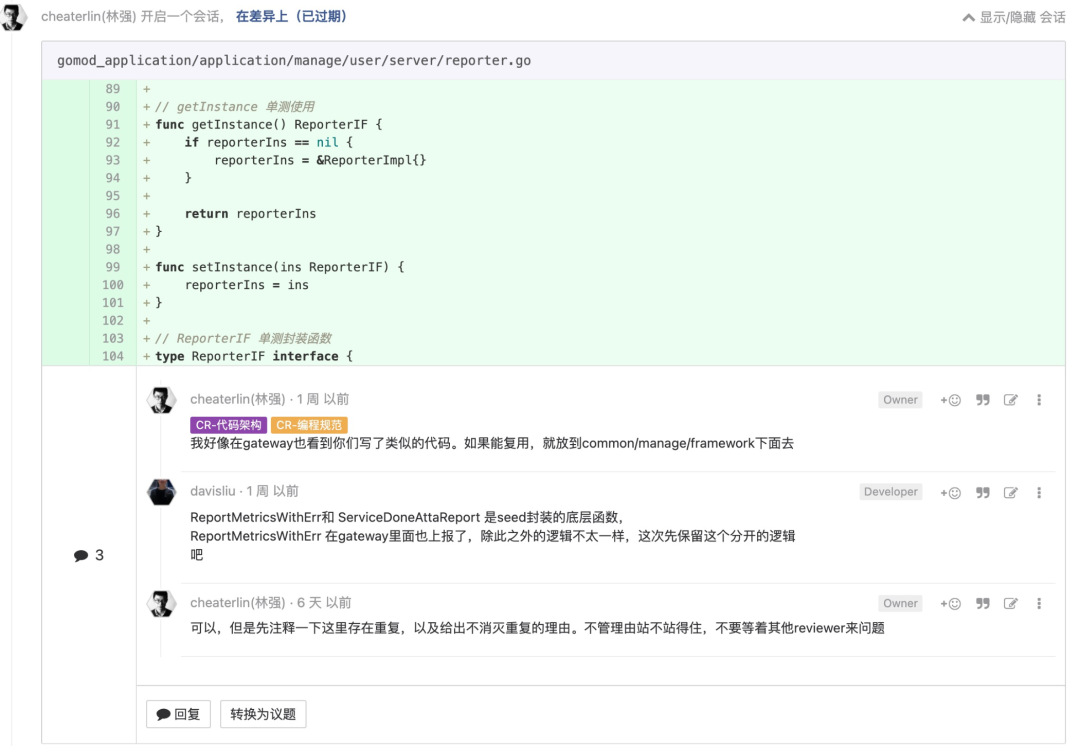
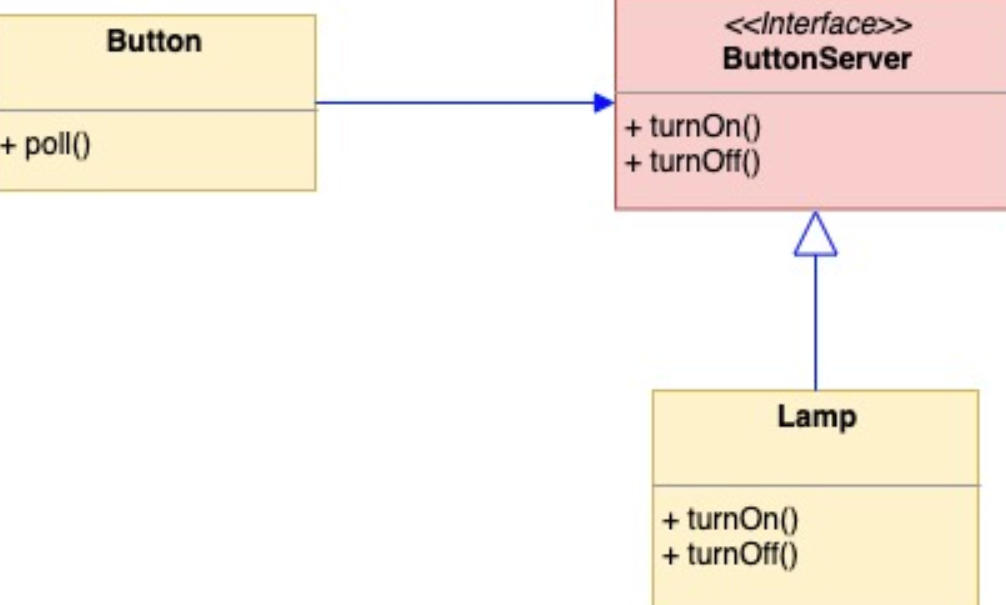
package diptype Botton interface {TurnOn()TurnOff()}type UI struct {botton Botton}func NewUI(b Botton) *UI {return &UI{botton: b}}func (u *UI) Poll() {u.botton.TurnOn()u.botton.TurnOff()u.botton.TurnOn()}
package javaimplimport "fmt"type Lamp struct{}func NewLamp() *Lamp {return &Lamp{}}func (*Lamp) TurnOn() {fmt.Println("turn on java lamp")}func (*Lamp) TurnOff() {fmt.Println("turn off java lamp")}
package pythonimplimport "fmt"type Lamp struct{}func NewLamp() *Lamp {return &Lamp{}}func (*Lamp) TurnOn() {fmt.Println("turn on python lamp")}func (*Lamp) TurnOff() {fmt.Println("turn off python lamp")}
package mainimport ("dip""javaimpl""pythonimpl")func runPoll(b dip.Botton) {ui := NewUI(b)ui.Poll()}func main() {runPoll(pythonimpl.NewLamp())runPoll(javaimpl.NewLamp())}
09
10
11
12
13
func applyDiscount(customer Customer, orderID string, discount float32) {customer.Orders.Find(orderID).GetTotals().ApplyDiscount(discount)}
func applyDiscount(customer Customer, orderID string, discount float32) {customer.FindOrder(orderID).GetTotals().ApplyDiscount(discount)}
func applyDiscount(customer Customer, orderID string, discount float32) {customer.FindOrder(orderID).ApplyDiscount(discount)}
func applyDiscount(customer Customer, orderID string, discount float32) {total := customer.FindOrder(orderID).GetTotals()customer.FindOrder(orderID).SetTotal(total * discount)}
14
func amount(customer Customer) float32 {return customer.Orders.Last().Totals().Amount}
func amount(totals Totals) float32 {return totals.Amount}
15
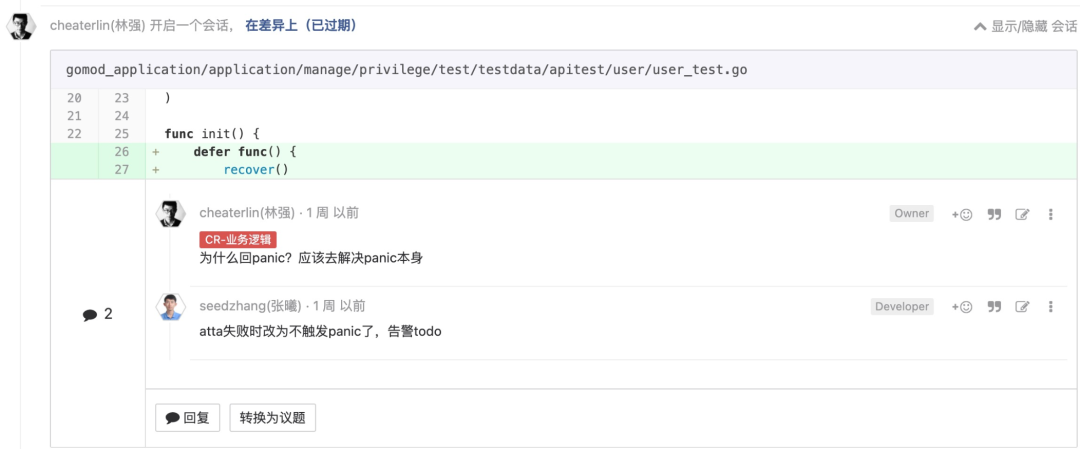
继承就是耦合。不仅子类耦合到父类,以及父类的父类等,而且使用子类的代码也耦合到所有祖先类。有些人认为继承是定义新类型的一种方式。他们喜欢设计图表,会展示出类的层次结构。他们看待问题的方式,与维多利亚时代的绅士科学家们看待自然的方式是一样的,即将自然视为须分解到不同类别的综合体。不幸的是,这些图表很快就会为了表示类之间的细微差别而逐层添加,最终可怕地爬满墙壁。由此增加的复杂性,可能使应用程序更加脆弱,因为变更可能在许多层次之间上下波动。因为一些值得商榷的词义消歧方面的原因,C++在20世纪90年代玷污了多重继承的名声。结果许多当下的 OO 语言都没有提供这种功能。
16
17
18
Exceptions are preferred in modern C++ for the following reasons:* An exception forces calling code to recognize an error condition and handle it. Unhandled exceptions stop program execution.* An exception jumps to the point in the call stack that can handle the error. Intermediate functions can let the exception propagate. They don't have to coordinate with other layers.* The exception stack-unwinding mechanism destroys all objects in scope after an exception is thrown, according to well-defined rules.* An exception enables a clean separation between the code that detects the error and the code that handles the error.
Because most existing C++ code at Google is not prepared to deal with exceptions, it is comparatively difficult to adopt new code that generates exceptions.
19
20
// IrisFriends 拉取好友func IrisFriends(ctx iris.Context, app *app.App) {var rsp sdc.FriendsRspdefer func() {var buf bytes.Buffer_ = (&jsonpb.Marshaler{EmitDefaults: true}).Marshal(&buf, &rsp)_, _ = ctx.Write(buf.Bytes())}()common.AdjustCookie(ctx)if !checkCookie(ctx) {return}// 从cookie中拿到关键的登陆态等有效信息var session common.BaseSessioncommon.GetBaseSessionFromCookie(ctx, &session)// 校验登陆态err := common.CheckLoginSig(session, app.ConfigStore.Get().OIDBCmdSetting.PTLogin)if err != nil {_ = common.ErrorResponse(ctx, errors.PTSigErr, 0, "check login sig error")return}if err = getRelationship(ctx, app.ConfigStore.Get().OIDBCmdSetting, NewAPI(), &rsp); err != nil {// TODO:日志}return}
21
Keep It Simple Stupid!
原则3 组合原则: 设计时考虑拼接组合
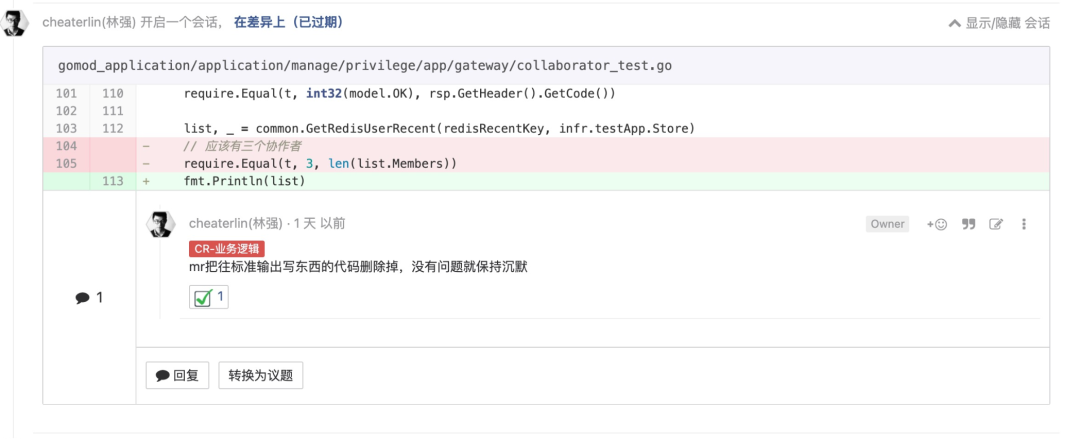
关于 OOP,关于继承,我前面已经说过了。那我们怎么组织自己的模块?对,用组合的方式来达到。linux 操作系统离我们这么近,它是怎么架构起来的?往小里说,我们一个串联一个业务请求的数据集合,如果使用 BaseSession,XXXSession inherit BaseSession 的设计,其实,这个继承树,很难适应层出不穷的变化。但是如果使用组合,就可以拆解出 UserSignature 等等各种可能需要的部件,在需要的时候组合使用,不断添加新的部件而没有对老的继承树的记忆这个心智负担。
// A Request represents an HTTP request received by a server// or to be sent by a client.//// The field semantics differ slightly between client and server// usage. In addition to the notes on the fields below, see the// documentation for Request.Write and RoundTripper.type Request struct {// Method specifies the HTTP method (GET, POST, PUT, etc.).// For client requests, an empty string means GET.//// Go's HTTP client does not support sending a request with// the CONNECT method. See the documentation on Transport for// details.Method string// URL specifies either the URI being requested (for server// requests) or the URL to access (for client requests).//// For server requests, the URL is parsed from the URI// supplied on the Request-Line as stored in RequestURI. For// most requests, fields other than Path and RawQuery will be// empty. (See RFC 7230, Section 5.3)//// For client requests, the URL's Host specifies the server to// connect to, while the Request's Host field optionally// specifies the Host header value to send in the HTTP// request.URL *url.URL// The protocol version for incoming server requests.//// For client requests, these fields are ignored. The HTTP// client code always uses either HTTP/1.1 or HTTP/2.// See the docs on Transport for details.Proto string // "HTTP/1.0"ProtoMajor int // 1ProtoMinor int // 0// Header contains the request header fields either received// by the server or to be sent by the client.//// If a server received a request with header lines,//// Host: example.com// accept-encoding: gzip, deflate// Accept-Language: en-us// fOO: Bar// foo: two//// then//// Header = map[string][]string{// "Accept-Encoding": {"gzip, deflate"},// "Accept-Language": {"en-us"},// "Foo": {"Bar", "two"},// }//// For incoming requests, the Host header is promoted to the// Request.Host field and removed from the Header map.//// HTTP defines that header names are case-insensitive. The// request parser implements this by using CanonicalHeaderKey,// making the first character and any characters following a// hyphen uppercase and the rest lowercase.//// For client requests, certain headers such as Content-Length// and Connection are automatically written when needed and// values in Header may be ignored. See the documentation// for the Request.Write method.Header Header// Body is the request's body.//// For client requests, a nil body means the request has no// body, such as a GET request. The HTTP Client's Transport// is responsible for calling the Close method.//// For server requests, the Request Body is always non-nil// but will return EOF immediately when no body is present.// The Server will close the request body. The ServeHTTP// Handler does not need to.Body io.ReadCloser// GetBody defines an optional func to return a new copy of// Body. It is used for client requests when a redirect requires// reading the body more than once. Use of GetBody still// requires setting Body.//// For server requests, it is unused.GetBody func() (io.ReadCloser, error)// ContentLength records the length of the associated content.// The value -1 indicates that the length is unknown.// Values >= 0 indicate that the given number of bytes may// be read from Body.//// For client requests, a value of 0 with a non-nil Body is// also treated as unknown.ContentLength int64// TransferEncoding lists the transfer encodings from outermost to// innermost. An empty list denotes the "identity" encoding.// TransferEncoding can usually be ignored; chunked encoding is// automatically added and removed as necessary when sending and// receiving requests.TransferEncoding []string// Close indicates whether to close the connection after// replying to this request (for servers) or after sending this// request and reading its response (for clients).//// For server requests, the HTTP server handles this automatically// and this field is not needed by Handlers.//// For client requests, setting this field prevents re-use of// TCP connections between requests to the same hosts, as if// Transport.DisableKeepAlives were set.Close bool// For server requests, Host specifies the host on which the// URL is sought. For HTTP/1 (per RFC 7230, section 5.4), this// is either the value of the "Host" header or the host name// given in the URL itself. For HTTP/2, it is the value of the// ":authority" pseudo-header field.// It may be of the form "host:port". For international domain// names, Host may be in Punycode or Unicode form. Use// golang.org/x/net/idna to convert it to either format if// needed.// To prevent DNS rebinding attacks, server Handlers should// validate that the Host header has a value for which the// Handler considers itself authoritative. The included// ServeMux supports patterns registered to particular host// names and thus protects its registered Handlers.//// For client requests, Host optionally overrides the Host// header to send. If empty, the Request.Write method uses// the value of URL.Host. Host may contain an international// domain name.Host string// Form contains the parsed form data, including both the URL// field's query parameters and the PATCH, POST, or PUT form data.// This field is only available after ParseForm is called.// The HTTP client ignores Form and uses Body instead.Form url.Values// PostForm contains the parsed form data from PATCH, POST// or PUT body parameters.//// This field is only available after ParseForm is called.// The HTTP client ignores PostForm and uses Body instead.PostForm url.Values// MultipartForm is the parsed multipart form, including file uploads.// This field is only available after ParseMultipartForm is called.// The HTTP client ignores MultipartForm and uses Body instead.MultipartForm *multipart.Form// Trailer specifies additional headers that are sent after the request// body.//// For server requests, the Trailer map initially contains only the// trailer keys, with nil values. (The client declares which trailers it// will later send.) While the handler is reading from Body, it must// not reference Trailer. After reading from Body returns EOF, Trailer// can be read again and will contain non-nil values, if they were sent// by the client.//// For client requests, Trailer must be initialized to a map containing// the trailer keys to later send. The values may be nil or their final// values. The ContentLength must be 0 or -1, to send a chunked request.// After the HTTP request is sent the map values can be updated while// the request body is read. Once the body returns EOF, the caller must// not mutate Trailer.//// Few HTTP clients, servers, or proxies support HTTP trailers.Trailer Header// RemoteAddr allows HTTP servers and other software to record// the network address that sent the request, usually for// logging. This field is not filled in by ReadRequest and// has no defined format. The HTTP server in this package// sets RemoteAddr to an "IP:port" address before invoking a// handler.// This field is ignored by the HTTP client.RemoteAddr string// RequestURI is the unmodified request-target of the// Request-Line (RFC 7230, Section 3.1.1) as sent by the client// to a server. Usually the URL field should be used instead.// It is an error to set this field in an HTTP client request.RequestURI string// TLS allows HTTP servers and other software to record// information about the TLS connection on which the request// was received. This field is not filled in by ReadRequest.// The HTTP server in this package sets the field for// TLS-enabled connections before invoking a handler;// otherwise it leaves the field nil.// This field is ignored by the HTTP client.TLS *tls.ConnectionState// Cancel is an optional channel whose closure indicates that the client// request should be regarded as canceled. Not all implementations of// RoundTripper may support Cancel.//// For server requests, this field is not applicable.//// Deprecated: Set the Request's context with NewRequestWithContext// instead. If a Request's Cancel field and context are both// set, it is undefined whether Cancel is respected.Cancel <-chan struct{}// Response is the redirect response which caused this request// to be created. This field is only populated during client// redirects.Response *Response// ctx is either the client or server context. It should only// be modified via copying the whole Request using WithContext.// It is unexported to prevent people from using Context wrong// and mutating the contexts held by callers of the same request.ctx context.Context}
原则 6 吝啬原则: 除非确无它法, 不要编写庞大的程序
原则 7 透明性原则: 设计要可见,以便审查和调试
原则 10 通俗原则: 接口设计避免标新立异
type Point struct {X float64Y float64}
type Point struct {VerticalOrdinate float64HorizontalOrdinate float64}
原则 11 缄默原则: 如果一个程序没什么好说的,就沉默
原则 12 补救原则: 出现异常时,马上退出并给出足够错误信息
推荐阅读
评论