
面试|十分钟聊透Spark(附录综合案例)
Spark是一个快速的大数据处理引擎,在实际的生产环境中,应用十分广泛。目前,Spark仍然是大数据开发非常重要的一个工具,所以在面试的过程中,Spark也会是被重点考察的对象。对于初学者而言,面对繁多的Spark相关概念,一时会难以厘清头绪,对于使用Spark开发的同学而言,有时候也会对这些概念感到模糊。本文主要梳理了几个关于Spark的比较重要的几个概念,在面试的过程中如果被问到Spark相关的问题,具体可以从以下几个方面展开即可,希望对你有所帮助。本文主要包括以下内容:
运行架构 运行流程 执行模式 驱动程序 共享变量 宽依赖窄依赖 持久化 分区 综合实践案例
组成
Spark栈包括SQL和DataFrames,MLlib机器学习, GraphX和SparkStreaming。用户可以在同一个应用程序中无缝组合使用这些库。
架构
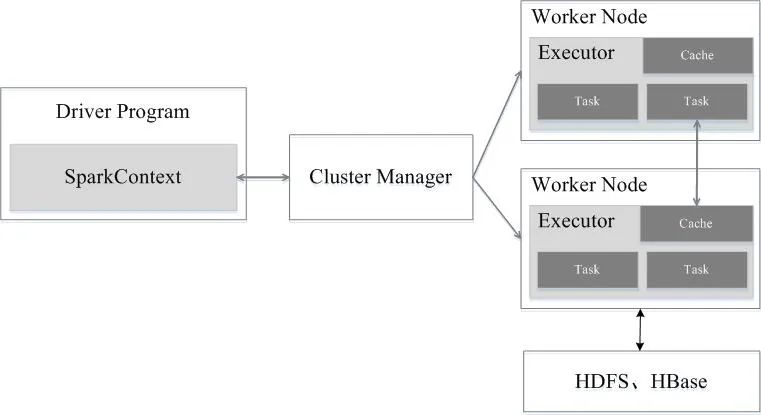
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
运行流程
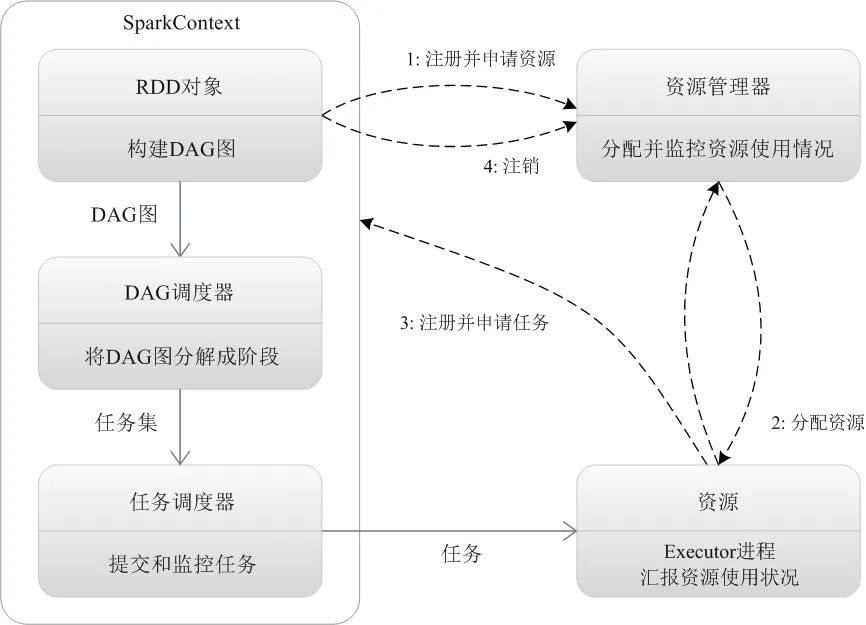
当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源; 资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上; SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor; 任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
MapReduce VS Spark
与Spark相比,MapReduce具有以下缺点:
表达能力有限 磁盘IO开销大 延迟高 任务之间的衔接涉及IO开销 在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
与MapReduce相比,Spark具有以下优点:具体包括两个方面
一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销; 二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
驱动程序(Driver)和Executor
运行main函数的驱动程序进程位于集群中的一个节点上,负责三件事:
维护有关 Spark 应用程序的信息。
响应用户的程序或输入。
跨Executor分析、分配和调度作业。
驱动程序进程是绝对必要的——它是 Spark 应用程序的核心,并在应用程序的生命周期内维护所有相关信息。
Executor负责实际执行驱动程序分配给他们的任务。这意味着每个Executor只负责两件事:
执行驱动程序分配给它的代码。
向Driver节点汇报该Executor的计算状态
分区
为了让每个 executor 并行执行工作,Spark 将数据分解成称为partitions 的块。分区是位于集群中一台物理机器上的行的集合。Dataframe 的分区表示数据在执行期间如何在机器集群中物理分布。
如果你有一个分区,即使你有数千个Executor,Spark 的并行度也只有一个。如果你有很多分区但只有一个执行器,Spark 仍然只有一个并行度,因为只有一个计算资源。
执行模式:Client VS Cluster VS Local
执行模式能够在运行应用程序时确定Driver和Executor的物理位置。
有三种模式可供选择:
集群模式(Cluster)。
客户端模式(Client)。
本地模式(Local)。
集群模式 可能是运行 Spark 应用程序最常见的方式。在集群模式下,用户将预编译的代码提交给集群管理器。除了启动Executor之外,集群管理器会在集群内的工作节点(work)上启动驱动程序(Driver)进程。这意味着集群管理器负责管理与 Spark 应用程序相关的所有进程。
客户端模式 与集群模式几乎相同,只是 Spark 驱动程序保留在提交应用程序的客户端节点上。这意味着客户端机器负责维护 Spark driver 进程,集群管理器维护 executor 进程。通常将这个节点称之为网关节点。
本地模式可以被认为是在你的计算机上运行一个程序,spark 会在同一个 JVM 中运行驱动程序和执行程序。
RDD VS DataFrame VS DataSet
RDD
一个RDD是一个分布式对象集合,其本质是一个只读的、分区的记录集合。每个RDD可以分成多个分区,不同的分区保存在不同的集群节点上(具体如下图所示)。RDD是一种高度受限的共享内存模型,即RDD是只读的分区记录集合,所以也就不能对其进行修改。只能通过两种方式创建RDD,一种是基于物理存储的数据创建RDD,另一种是通过在其他RDD上作用转换操作(transformation,比如map、filter、join等)得到新的RDD。
基于内存
RDD是位于内存中的对象集合。RDD可以存储在内存、磁盘或者内存加磁盘中,但是,Spark之所以速度快,是基于这样一个事实:数据存储在内存中,并且每个算子不会从磁盘上提取数据。
分区
分区是对逻辑数据集划分成不同的独立部分,分区是分布式系统性能优化的一种技术手段,可以减少网络流量传输,将相同的key的元素分布在相同的分区中可以减少shuffle带来的影响。RDD被分成了多个分区,这些分区分布在集群中的不同节点。
强类型
RDD中的数据是强类型的,当创建RDD的时候,所有的元素都是相同的类型,该类型依赖于数据集的数据类型。
懒加载
Spark的转换操作是懒加载模式,这就意味着只有在执行了action(比如count、collect等)操作之后,才会去执行一些列的算子操作。
不可修改
RDD一旦被创建,就不能被修改。只能从一个RDD转换成另外一个RDD。
并行化
RDD是可以被并行操作的,由于RDD是分区的,每个分区分布在不同的机器上,所以每个分区可以被并行操作。
持久化
由于RDD是懒加载的,只有action操作才会导致RDD的转换操作被执行,进而创建出相对应的RDD。对于一些被重复使用的RDD,可以对其进行持久化操作(比如将其保存在内存或磁盘中,Spark支持多种持久化策略),从而提高计算效率。
DataFrame
DataFrame代表一个不可变的分布式数据集合,其核心目的是让开发者面对数据处理时,只关心要做什么,而不用关心怎么去做,将一些优化的工作交由Spark框架本身去处理。DataFrame是具有Schema信息的,也就是说可以被看做具有字段名称和类型的数据,类似于关系型数据库中的表,但是底层做了很多的优化。创建了DataFrame之后,就可以使用SQL进行数据处理。
用户可以从多种数据源中构造DataFrame,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API支持Scala,Java,Python和R,在Scala和Java中,row类型的DataSet代表DataFrame,即Dataset[Row]等同于DataFrame。
DataSet
DataSet是Spark 1.6中添加的新接口,是DataFrame的扩展,它具有RDD的优点(强类型输入,支持强大的lambda函数)以及Spark SQL的优化执行引擎的优点。可以通过JVM对象构建DataSet,然后使用函数转换(map,flatMap,filter)。值得注意的是,Dataset API在Scala和 Java中可用,Python不支持Dataset API。
另外,DataSet API可以减少内存的使用,由于Spark框架知道DataSet的数据结构,因此在持久化DataSet时可以节省很多的内存空间。
共享变量
Spark提供了两种类型的共享变量:广播变量和累加器。广播变量(Broadcast variables)是一个只读的变量,并且在每个节点都保存一份副本,而不需要在集群中发送数据。累加器(Accumulators)可以将所有任务的数据累加到一个共享结果中。
广播变量
广播变量允许用户在集群中共享一个不可变的值,该共享的、不可变的值被持计划到集群的每台节点上。通常在需要将一份小数据集(比如维表)复制到集群中的每台节点时使用,比如日志分析的应用,web日志通常只包含pageId,而每个page的标题保存在一张表中,如果要分析日志(比如哪些page被访问的最多),则需要将两者join在一起,这时就可以使用广播变量,将该表广播到集群的每个节点。具体如下图所示:
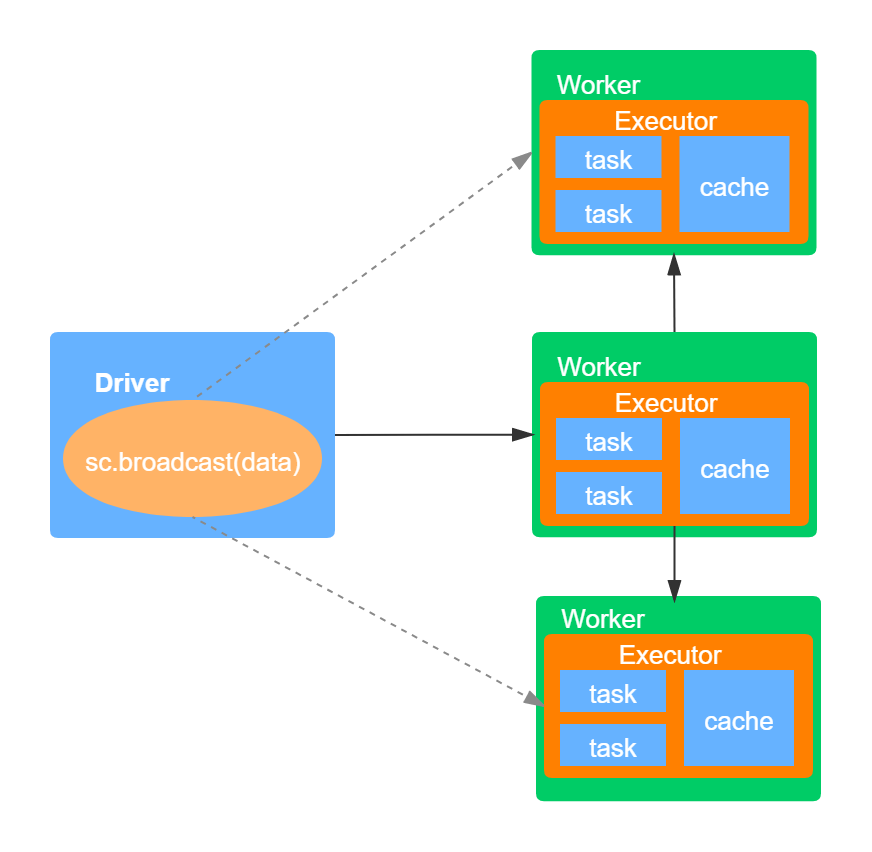
如上图,首先Driver将序列化对象分割成小的数据库,然后将这些数据块存储在Driver节点的BlockManager上。当ececutor中执行具体的task时,每个executor首先尝试从自己所在节点的BlockManager提取数据,如果之前已经提取的该广播变量的值,就直接使用它。如果没有找到,则会向远程的Driver或者其他的Executor中提取广播变量的值,一旦获取该值,就将其存储在自己节点的BlockManager中。这种机制可以避免Driver端向多个executor发送数据而造成的性能瓶颈。
累加器
累加器(Accumulator)是Spark提供的另外一个共享变量,与广播变量不同,累加器是可以被修改的,是可变的。每个transformation会将修改的累加器值传输到Driver节点,累加器可以实现一个累加的功能,类似于一个计数器。Spark本身支持数字类型的累加器,用户也可以自定义累加器的类型。
宽依赖和窄依赖
RDD中不同的操作会使得不同RDD中的分区产不同的依赖,主要有两种依赖:宽依赖和窄依赖。宽依赖是指一个父RDD的一个分区对应一个子RDD的多个分区,窄依赖是指一个父RDD的分区对应与一个子RDD的分区,或者多个父RDD的分区对应一个子RDD分区。
窄依赖会被划分到同一个stage中,这样可以以管道的形式迭代执行。宽依赖所依赖的分区一般有多个,所以需要跨节点传输数据。从容灾方面看,两种依赖的计算结果恢复的方式是不同的,窄依赖只需要恢复父RDD丢失的分区即可,而宽依赖则需要考虑恢复所有父RDD丢失的分区。
DAGScheduler会将Job的RDD划分到不同的stage中,并构建一个stage的依赖关系,即DAG。这样划分的目的是既可以保障没有依赖关系的stage可以并行执行,又可以保证存在依赖关系的stage顺序执行。stage主要分为两种类型,一种是ShuffleMapStage,另一种是ResultStage。其中ShuffleMapStage是属于上游的stage,而ResulStage属于最下游的stage,这意味着上游的stage先执行,最后执行ResultStage。
持久化
方式
在Spark中,RDD采用惰性求值的机制,每次遇到action操作,都会从头开始执行计算。每次调用action操作,都会触发一次从头开始的计算。对于需要被重复使用的RDD,spark支持对其进行持久化,通过调用persist()或者cache()方法即可实现RDD的持计划。通过持久化机制可以避免重复计算带来的开销。值得注意的是,当调用持久化的方法时,只是对该RDD标记为了持久化,需要等到第一次执行action操作之后,才会把计算结果进行持久化。持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
Spark提供的两个持久化方法的主要区别是:cache()方法默认使用的是内存级别,其底层调用的是persist()方法。
持久化级别的选择
Spark提供的持久化存储级别是在内存使用与CPU效率之间做权衡,通常推荐下面的选择方式:
如果内存可以容纳RDD,可以使用默认的持久化级别,即MEMORY_ONLY。这是CPU最有效率的选择,可以使作用在RDD上的算子尽可能第快速执行。
如果内存不够用,可以尝试使用MEMORY_ONLY_SER,使用一个快速的序列化库可以节省很多空间,比如 Kryo 。
tips:在一些shuffle算子中,比如reduceByKey,即便没有显性调用persist方法,Spark也会自动将中间结果进行持久化,这样做的目的是避免在shuffle期间发生故障而造成重新计算整个输入。即便如此,还是推荐对需要被重复使用的RDD进行持久化处理。
coalesce VS repartition
repartition算法对数据进行了shuffle操作,并创建了大小相等的数据分区。coalesce操作合并现有分区以避免shuffle,除此之外coalesce操作仅能用于减少分区,不能用于增加分区。
值得注意的是:使用coalesce在减少分区时,并没有对所有数据进行了移动,仅仅是在原来分区的基础之上进行了合并而已,所以效率较高,但是可能会引起数据倾斜。
综合案例
一种数仓技术架构
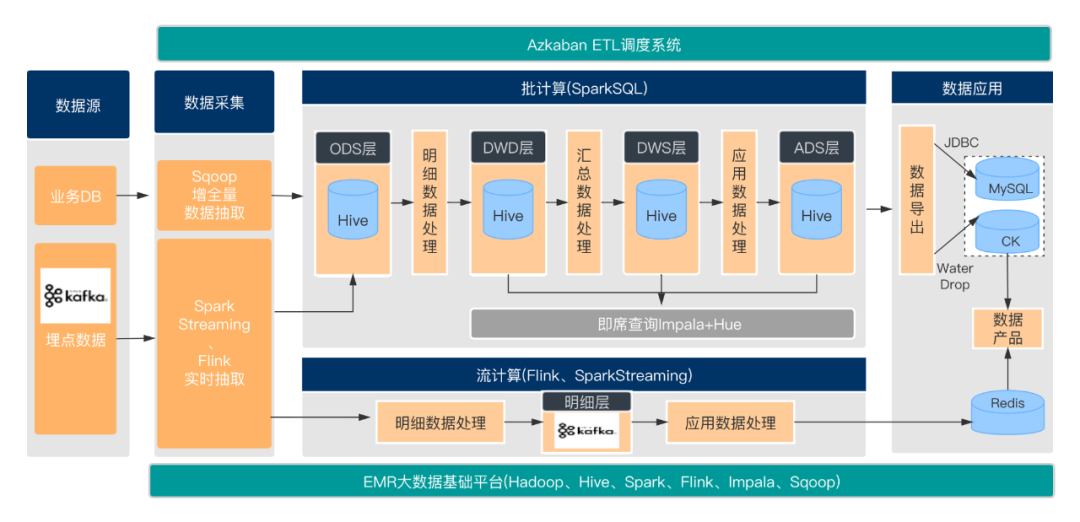
SparkStreaming实时同步
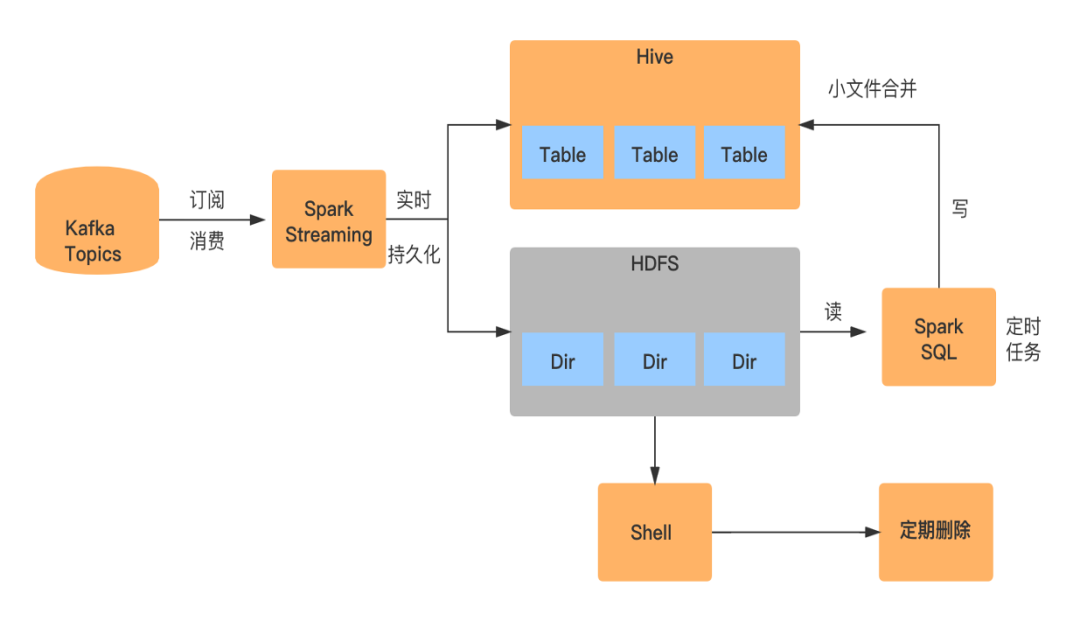
订阅消费:
SparkStreaming消费kafka埋点数据
数据写入:
将解析的数据同时写入HDFS上的某个临时目录下及Hive表对应的分区目录下
小文件合并:
由于是实时数据抽取,所以会生成大量的小文件,小文件的生成取决于SparkStreaming的Batch Interval,比如一分钟一个batch,那么一分钟就会生成一个小文件
基于SparkSQL的批处理
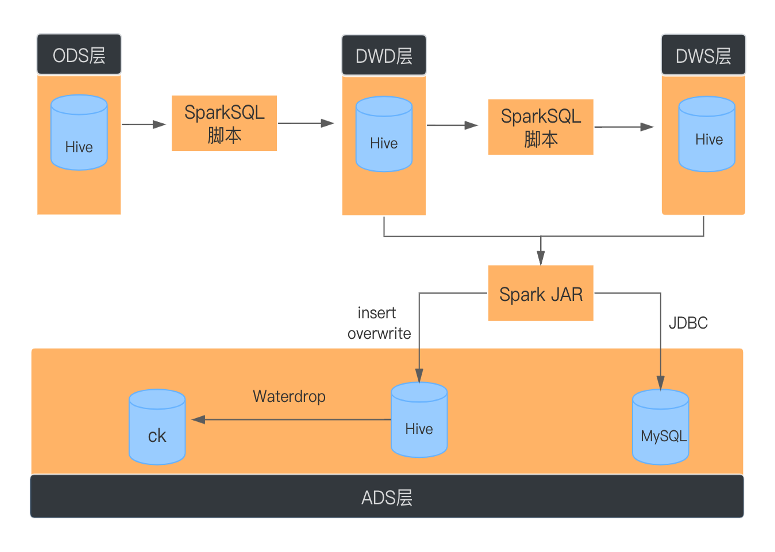
ODS层到DWD层数据去重
SparkStreaming数据输出是At Least Once,可能会存在数据重复。在ODS层到DWD层进行明细数据处理时,需要对数据使用row_number去重。
JDBC写入MySQL
数据量大时,需要对数据进行重分区,并且为DataSet分区级别建立连接,采用批量提交的方式。
使用DISTRIBUTE BY子句避免生成大量小文件
spark.sql.shuffle.partitions的默认值为200,会导致以下问题
对于较小的数据,200是一个过大的选择,由于调度开销,通常会导致处理速度变慢,同时会造成小文件的产生。
对于大数据集,200很小,无法有效利用集群中的资源
使用 DISTRIBUTE BY cast( rand * N as int) 这里的N是指具体最后落地生成多少个文件数。
手动维护offset至HBase
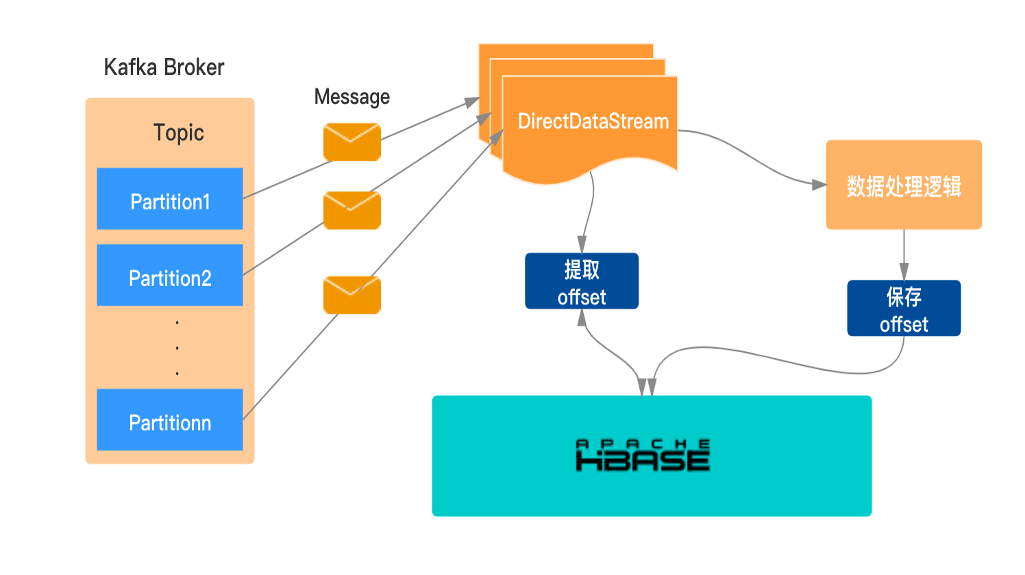
当作业发生故障或重启时,要保障从当前的消费位点去处理数据,单纯的依靠SparkStreaming本身的机制是不太理想,生产环境中通常借助手动管理来维护kafka的offset。
流应用监控告警
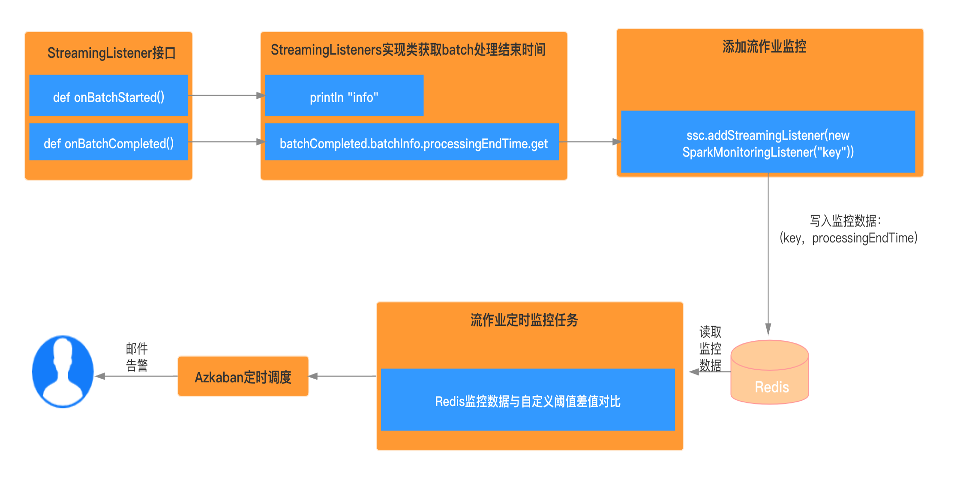
实现StreamingListener 接口,重写onBatchStarted与onBatchCompleted方法
获取batch执行完成之后的时间,写入Redis,数据类型的key为自定义的具体字符串,value是batch处理完的结束时间
加入流作业监控
启动定时任务监控上述步骤写入redis的kv数据,一旦超出给定的阈值,则报错,并发出告警通知
使用Azkaban定时调度该任务