
CVPR 2022 | 基于GAN生成 艺术文字logo及布局
来源 | 机器之心
下图的每对 logo 中,一个是设计师设计的 logo,另一个是 AI 模型生成的,顺序不确定,你能分辨出哪些是 AI 模型生成的吗?(答案在文末揭晓)


论文: https://arxiv.org/abs/2204.02701
数据集和代码: https://github.com/yizhiwang96/TextLogoLayout
一、数据集


二、模型设计
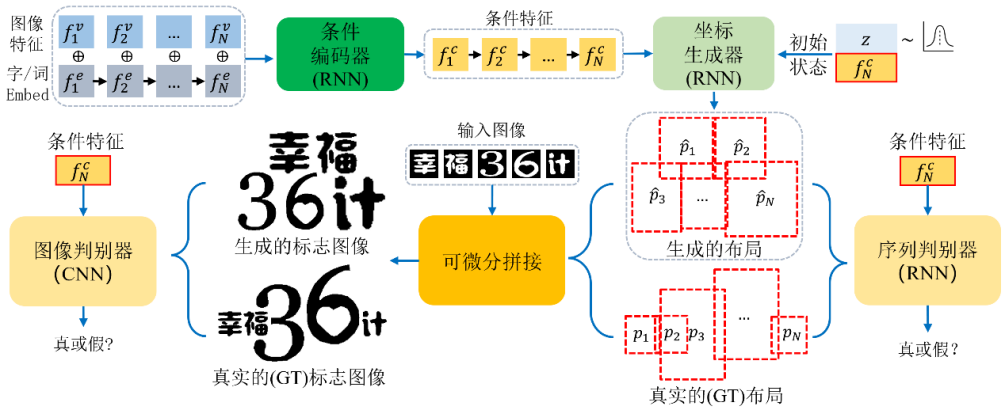
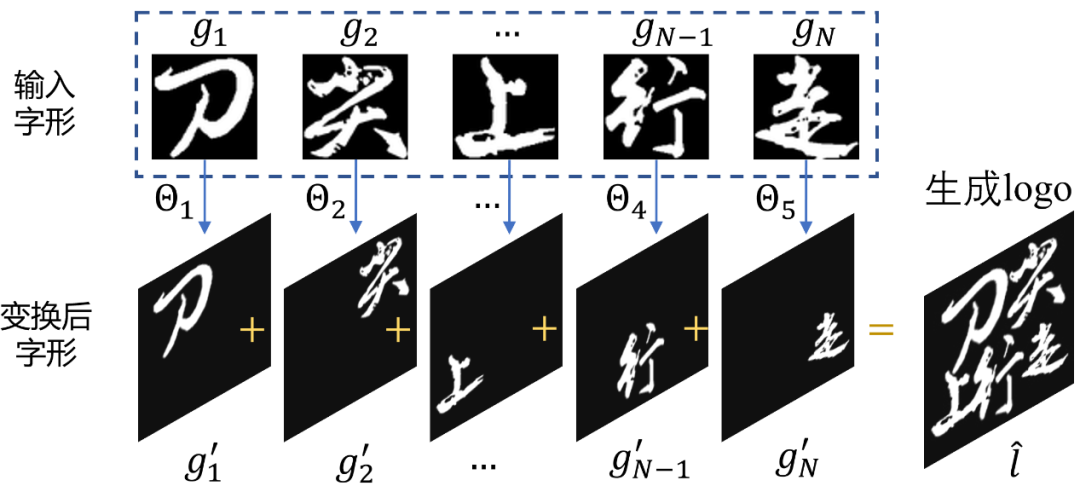
首先利用输入元素的双模态的特征(即字形视觉特征和文本语义特征),将其编码成条件特征。
坐标生成器采用条件特征和一个随机噪声作为输入, 为每个字符预测位置坐标,即字形外接框的中心点坐标,宽和高。
每个字符的位置坐标形成一条轨迹序列,故采用一个序列判别器去根据条件对序列和做真假判别。注意到本任务中坐标值是连续的,保证了序列判别器可以传播梯度。
通过可微分拼接, 合并每个字形得到的 logo 图像。
引入图像判别器,作为序列判别器的补充,目的是进一步捕捉到标志图像的细节信息,保证不同的字形之间不会有较大的重叠,字形间距合理等。
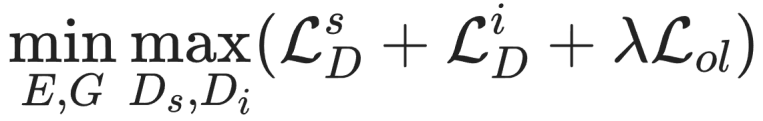
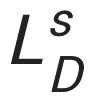 是序列判别器损失,
是序列判别器损失,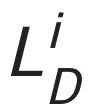 是图像判别器损失,
是图像判别器损失,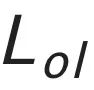 是显式的字形重叠损失(详情见论文)。E 代表条件编码器,G 代表坐标生成器,
是显式的字形重叠损失(详情见论文)。E 代表条件编码器,G 代表坐标生成器, 和
和 分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
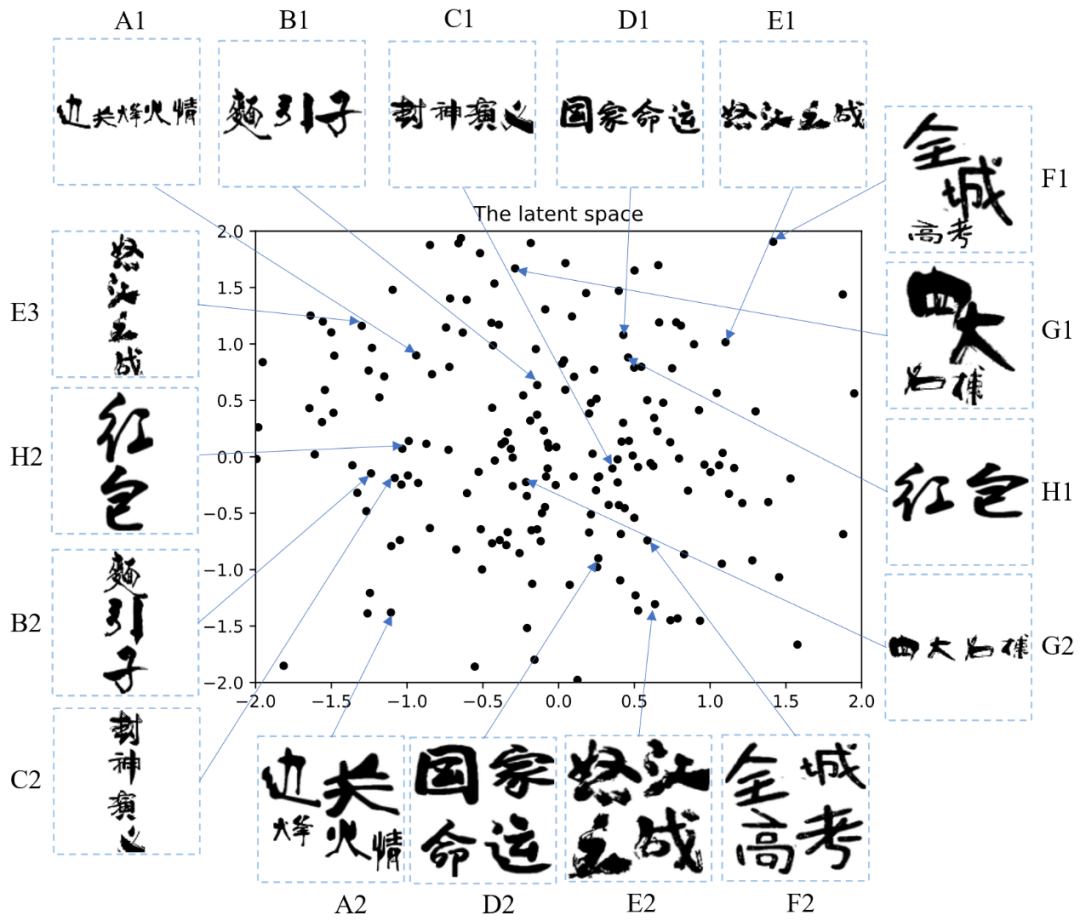
三、实验



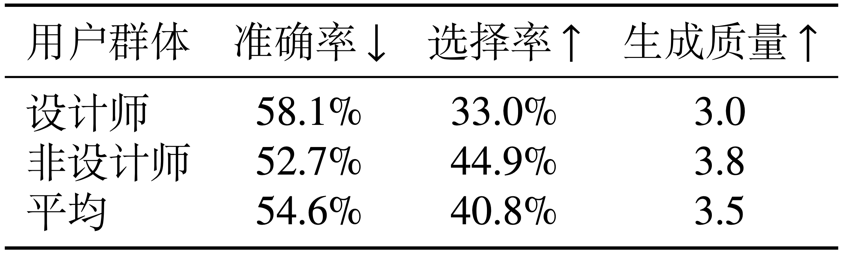

四、结论
评论