
CVPR 2022|极具创意&美感的文字生成方法!支持任意输入
本文简要介绍CVPR 2022录用的论文“Aesthetic Text Logo Synthesis via Content-aware Layout Inferring” 。该论文旨在探究文字标识图像设计过程 中的布局自动生成问题。该论文基于条件式对抗生成网络(conditional-GAN),提出双判别器结构和可微分拼接模块,根据输入文字的视觉和语义信息,推理得到每个字形的布局几何参数,从而合成文字标识图像。该方法可以辅助平面设计和其他与文字相关的视觉任务。该工作相关数据集和代码已经开源(见文末)。
一、研究背景
文字标志(Text Logo)的设计非常依赖于设计师的创意和经验,其中,如何安排每个文字元素的布局是一个核心问题。布局设计需要考虑到很多因素,如字形、文字语义、主题等。如图1所示,不同的文字之间通常不能有形状重叠;中文标识中换行或换列通常在词元(Token)之后;对于要强调语义的文字,通常使用较大的尺寸;斜切和旋转等几何变换可以分别体现力量感和欢乐感等主题。业内现有的方案大多是设计一套易于执行的规则,按照一些预先设定好的模板来设计布局,但是生成的结果往往会比较单调且缺乏创意和美感。针对这个问题,本论文提出了一种内容感知的文字标志图像生成模型,从大量现有的文字Logo中隐式地学习布局设计规则,从而能够对任意输入的字形生成新的Logo。

图1 文字标识图像中常见的布局类型
二、数据集
训练AI模型通常需要大量的数据,然而业内尚不存在针对该任务的数据集。为了解决该问题,本文提出了TextLogo3K数据集,借助腾讯视频平台,收集、标注了3,470张精心挑选的文字Logo图,这些Logo来源于电影、电视剧和动漫的封面图。如图2和图3所示,该数据集对字形进行了像素级别的精准标注,也标注了字形包围框、字符类别。

图2 TextLogo3K中Logo图像的标注
同时,它们在原海报图片中的位置和分割信息也一并提供:

图3 TextLogo3K中海报图像的标注
三、模型设计
3.1 流程框图
本模型的流程框图如下图所示:
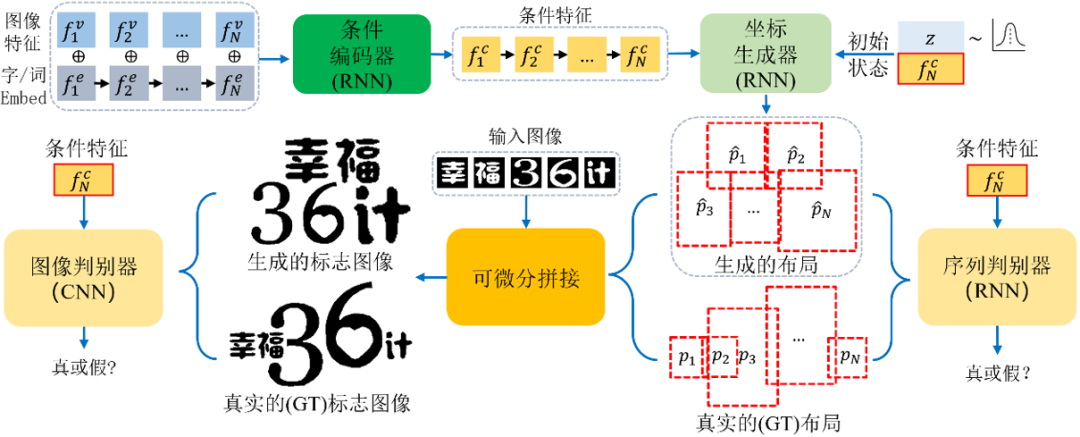
图4 本文模型流程框图
本模型基于Conditional GAN来生成文字Logo,创新性地使用双判别器结构(序列判别器和图像判别器),对字形的轨迹序列和整体Logo图像分别做判别;同时借助可微分拼接(Differentiable Composition),构建位置坐标到Logo图像的可微分渲染过程。其主要的流程包括:
首先利用输入元素的双模态的特征(即字形视觉特征和文本语义特征),将其编码成条件特征。
坐标生成器采用条件特征和一个随机噪声作为输入, 为每个字符预测位置坐标,即字形外接框的中心点坐标,宽和高。
每个字符的位置坐标形成一条轨迹序列,故采用一个序列判别器去根据条件对序列和做真假判别。注意到本任务中坐标值是连续的,保证了序列判别器可以传播梯度。
通过可微分拼接,合并每个字形得到的Logo图像。
引入图像判别器,作为序列判别器的补充,目的是进一步捕捉到标志图像的细节信息,保证不同的字形之间不会有较大的重叠,字形间距合理等。
网络的整体优化目标函数如下:
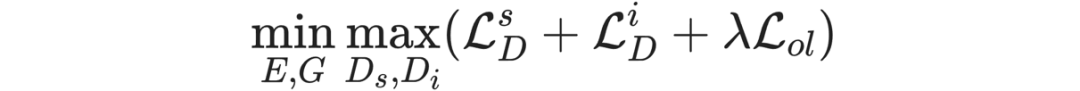
其中,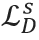 是序列判别器损失,
是序列判别器损失,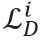 是图像判别器损失,
是图像判别器损失,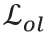 是显式的字形重叠损失(详情见论文)。E代表条件编码器,G代表坐标生成器,
是显式的字形重叠损失(详情见论文)。E代表条件编码器,G代表坐标生成器, 分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
3.2 可微分拼接
在获得预测的几何参数之后,需要进一步将每个字形图像按照这些几何参数拼接成一个文字Logo。更重要的是,这个拼接过程必须是可微分的,以让整个模型可以端到端地被优化。为了达成这个目的,本文设计了一个基于STN(Spatial Transform Networks)变种的可微分拼接方法。在原始的STN中,仿射变换参数是使用神经网络直接直接预测。本文方法先预测得到了目标字形位置坐标,于是先建立原坐标到目标坐标的映射关系(下图左),手动解出仿射变换的参数(下图右)。通过这种方式,既可以保证目标字形的位置坐标在画布的范围之内,又可以利用STN的可微分采样算法。

图5 显式求解仿射变换参数
通常来说,在文字Logo中不同字形之间不会有重叠(有一些故意的设计除外),因此不需要考虑每个字形之间的图层关系。如图6所示,将每个字形变换的图像直接进行加法操作,即可得到Logo图像,结合上述步骤,可微分拼接的整体过程都是可微分的。
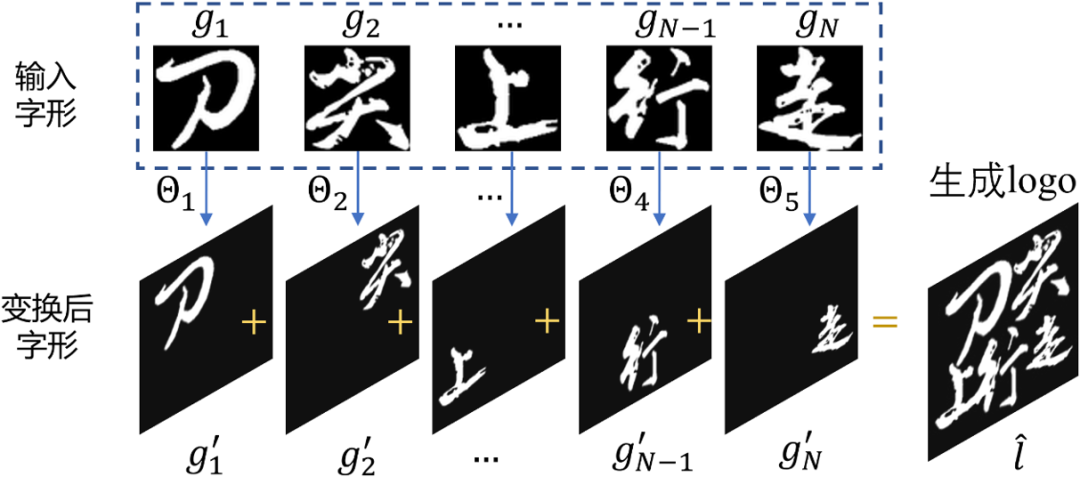
图6 根据求解参数合成Logo图像
3.3 双判别器结构
字符的放置轨迹应该既符合人们的阅读习惯,又呈现出多样的风格。然而,这两个特性不容易被图像生成模型中常用的卷积神经网络(CNNs)所捕获到。为了解决这个问题,本文设计了一个双判别器的模块,包括一个序列判别器和一个图像判别器。序列判别器以条件特征作为初始状态,将几何参数的序列作为输入,去分析这个放置轨迹的合理性。
四、实验
4.1 布局生成结果展示
如图7和图8所示,本模型可以生成英文Logo图,也可以生成中文Logo。

图7 本模型在英文数据集上结果

图8 本模型在中文数据集上结果
其中,“Ours”所在列表示本模型生成结果,“GT”表示设计师设计的结果。本模型生成的布局具有丰富的多样性:在英文结果里:(1)使用多行风格的布局,如“Welcome TO OUR HOMe”;(2)使用尺度变换起强调作用,如“POSTER HOUSE CAKE 8”中的数字“8”;(3)比较和谐的平移效果,如“Be
Kind”。在中文结果里:(1)根据具体字形安排布局,如“B+侦探”中,将“+”号巧妙地安排到“B”右下角和“侦”左下角之间;(2)根据语义进行换行,如“神探包青天”和“春风十里不如你”。
4.2 与其他方法对比
本文与2D图形布局生成工作LayoutGAN[1]和LayoutNet[2]进行了对比,这两种方法没有考虑到空间布局上的序列信息,以及输入元素的自身本文语义信息,所以不能很好地处理该任务。如图9所示,本模型生成了更好的结果。

图9 与现有方法对比
4.3 布局风格分析
通过主成分分析方法(PCA),对隐空间噪声z进行了可视化实验,结果展示在图10中。结果发现,(1)垂直的布局(B2, C2, H2, E3)倾向于落在平面的左边;(2)水平的布局(A1-E1, H1, G2)倾向于落在平面的中间和上方;(3)多行的布局(A2, D2, E2, F2)倾向于落在平面的右下方;(4)不规则的布局(F1,G1)倾向落在平面的边缘。隐空间噪声z和输入文本的长度变量是正交的。该可视化方法可以引导设计师探索布局风格的隐空间,帮助他们挑选喜欢的风格。
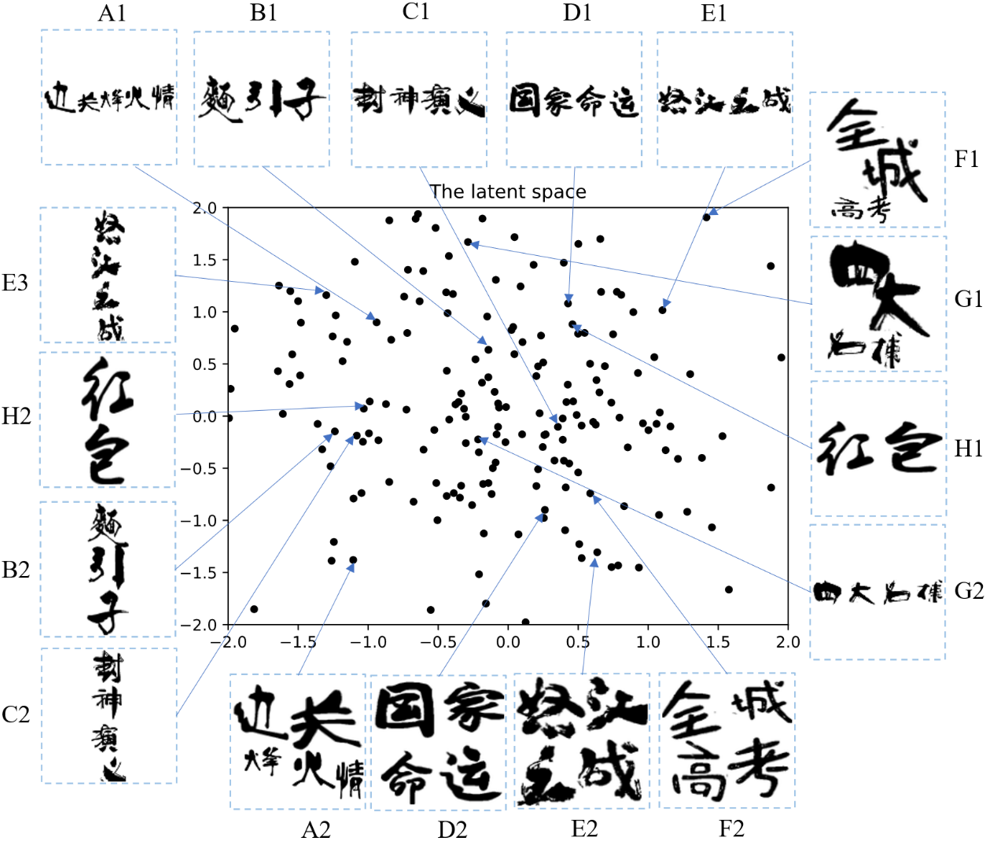
图10 隐空间噪声z的可视化结果
4.4 主观评价
本文开展了一项用户调查,用于收集用户对于本模型生成结果的主观评价,用户群体包括27个专业设计师和52个其他职业者。使用了20对测试图片(模型生成和人工设计的),让用户(1)选择哪个是AI生成的:下表中的“准确率”表示用户挑出本模型结果的概率,越低越好;(2)选择自己更倾向于哪个:下表中的“选择率”表示用户选择本模型结果的概率,越高越好;(3)给AI生成的质量打分(1-5):体现为下表中的“生成质量”,越高越好。从结果可以看出本模型取得了不错的效果,平均准确率接近50%,平均选择率40%。我们也观察到设计师群体更容易鉴别出AI结果,对质量要求也更苛刻,说明本工作还有进一步提升的空间。

4.5 Logo图生成系统
受字体生成模型和纹理迁移模型的启发,本文也建立了一个全自动的文字Logo图生成系统。该系统首先根据用户输入的文本和主题生成对应的字体,接着,将合成的字形图像和文本送到本文提出的布局生成网络中,得到字形摆放的布局,最后使用纹理迁移模型得到修饰后的Logo图像。图11展示了一些合成的样例,证明了本系统的有效性。

五、结论
本文提出了一种用于合成文字Logo图的布局生成模型。该模型创新性地提出了一个双判别器的模块,用于同时评估字符的放置轨迹和渲染后文字Logo图的细节信息。同时,本文提出一种可微分拼接的方法,构建了布局参数到文字Logo的可微分渲染过程。本文构建了一个大规模的数据集TextLogo3K,并实施大量实验来验证模型的有效性,该数据同样可以应用于其他任务,如文本检测与识别、艺术字体生成、纹理特效迁移等。
六、相关资源
论文:
https://arxiv.org/abs/2204.02701
https://github.com/yizhiwang96/TextLogoLayout
参考文献
[1] Li, Jianan, et
al. LayoutGAN: Generating Graphic Layouts with Wireframe
Discriminators.International Conference on Learning Representations.
2018.
[2] Zheng, Xinru, et
al. Content-aware generative modeling of graphic design layouts.ACM
Transactions on Graphics (TOG). 2019.
原文作者:Yizhi Wang, Guo Pu, Wenhan Luo, Yexin Wang, Pengfei Xiong, Hongwen Kang, Zhouhui Lian
撰稿:王逸之
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。