
好看视频Android重构——围绕于播放器的重构实践

一、背景介绍

二、好看视频历史回顾——单播放器
ViewPager和上下翻页的RecyclerView(竖划翻页配合使用了PagerSnapHelper)同时移动。mViewPager.addOnPageChangeListener(new ViewPager.OnPageChangeListener() {
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
mVideoView.moveVideoViewByX(positionOffsetPixels);
}
}
mRecyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
@Override
public void onScrolled(RecyclerView recyclerView, int dx, int dy) {
mVideoView.moveVideoViewByY(dy);
}
});
1、业务耦合严重,开发效率低
播放器和业务代码耦合严重,多个核心类代码1万+行,维护成本高,对新人极其不友好。播放器在初始化时就有221个View,各个View之间的隐藏和显示逻辑复杂,函数括号嵌套层次非常深,维护成本极高。Feed列表只承载视频封面图,导致广告/直播等第三方业务既要负责holder的展示,又要独立创建高层级的播放器进行控制,代码复杂度极高。 播放器状态控制复杂紊乱,从Activity、Fragment、ViewPager、RecyclerView、RecyclerViewAdapter、RecyclerViewHolder、每个View都能直接控制全局的单例播放器,生命周期难以追踪,播放相关的bug和用户反馈定位十分困难。
2、性能问题尾大不掉
由于播放器是飘在所有View的最上层,导致某些业务的View如果需要在最顶层,只能放在播放器内部再重新实现一遍。 RecyclerViewHolder中的某些View,既要在holder中又要在播放器的View中,再加上历史的陈旧代码,线上大量出现播放器View初始化时的ANR和卡顿

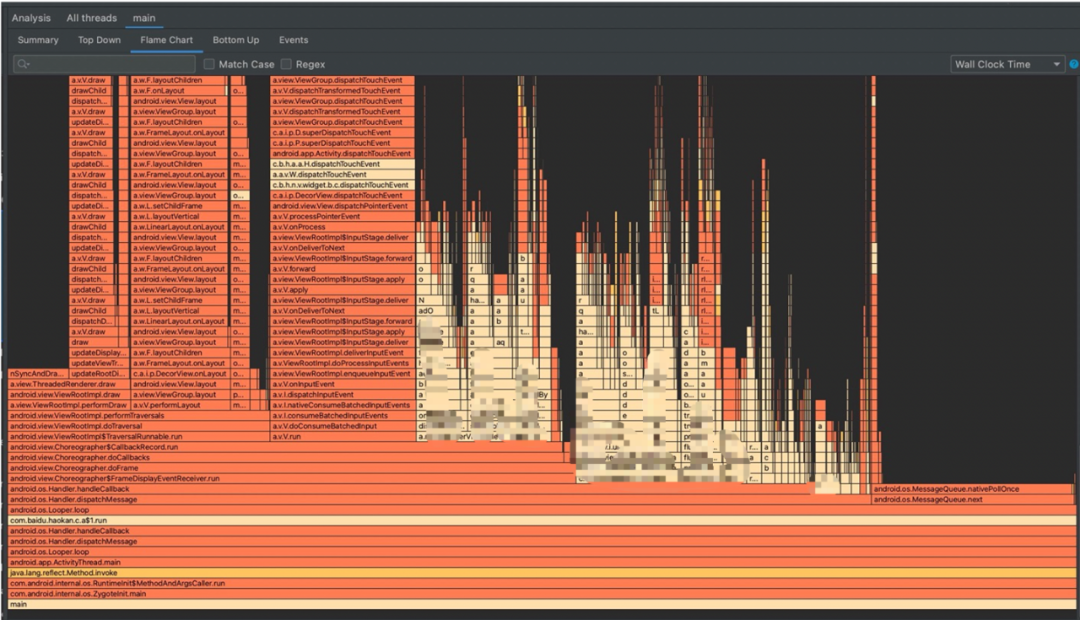
Feed列表滑动需要同步播放器进行卡尺滑动(包括播放器复位等),导致启播速度人为劣化。 低级别组件需要持有Activity级别的句柄,非常容易产生内存泄漏。 无法直接获取Activity句柄的业务,大量通过EventBus分发消息和控制逻辑,导致播放控制混乱(EventBus事件混乱和组件生命周期事件冲突等)。EventBus不仅加剧了内存泄漏的风险,还导致一些列的性能问题。
三、好看视频重构项目——多播放器
在holder内实现播放器状态自洽管理,直播/广告等业务仅在holder就可以实现自身业务(包括播放控制等),减少无用逻辑,降低代码耦合。 通过LifecycleLite分发播放相关事件,降低对EventBus的依赖,降低组件间耦合和内存泄漏风险。 利用自定义PageSnapHelper等组件,集中优化Feed列表启播/预加载等核心播放体验。
重构前后的掉帧率对比:
轻微掉帧次数/10分钟 | 严重掉帧次数/10分钟 | |
重构前 | 350 | 77 |
重构后 | 150 | 18 |
关于起播时间的优化
1、关于播放器创建的时机
onBindViewHolder准备页面和数据,所以可以在RecyclerViewHolder的onBind时就初始化下一个待播放视频的播放器。@Override
public void onBindViewHolder(@NonNull RecyclerView.ViewHolder holder, int position) {
if (holder instanceof ImmersiveBaseHolder) {
((ImmersiveBaseHolder) holder).onBind(getData(position), position);
holder.createPlayer();
}
}
2、关于播放器开始播放(start)的时机
RecyclerView的onScrollStateChanged中判断列表滑动的状态,当RecyclerView滑动停止时再起播,并结束上一个视频的播放。mRecyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
@Override
public void onScrollStateChanged(RecyclerView recyclerView, int newState) {
if (newState == SCROLL_STATE_SETTLING) {
currentHolder.player.prepareAysnc();
lastHolder.player.stopAndRelease();
}
}
});
PagerSnapHelper会计算要跳转的视频,并根据速度和剩余的滑动距离计算时间,通过SmoothScroller做惯性滚动动画——我们考虑下,如果在松开手指的一刻,换句话说,当我们明确知道了下一个待播放的视频时,就赶紧播放它,会有什么效果?几乎秒播
onInfo的MEDIA_INFO_VIDEO_RENDERING_START回调),大概需要300-500ms,而从手指开屏幕到滑动结束,也接近200-300ms。一般来说,起播速度在200ms左右用户几乎可以认为是”秒开“,所以提前起播对用户体验的提升巨大。// PagerSnapHelper.java
@Override
protected LinearSmoothScroller createSnapScroller(RecyclerView.LayoutManager layoutManager) {
return new LinearSmoothScroller(mRecyclerView.getContext()) {
@Override
protected void onTargetFound(View targetView, RecyclerView.State state, Action action) {
int nextPosition = state.getTargetScrollPosition();
adapter.getHolder(nextPosition).player.start();
adapter.getHolder(currentPosition).player.stopAndRelease();
}
}
}
// 重点在 onTargetFound 此时已经成功定位被选择的holder
onBindViewHolder中创建播放器后,立即prepare播放器,但不调用start。此类优化需要对播放器的生命周期掌握极其熟练,处理不当很容易导致多个视频同时播放或者其他的隐藏bug,需要格外小心。3、更早的起播
attachToWindow中关于新架构的整体收益
四、浅谈播放器预加载
1、关于预加载的文件大小问题
$pip install qtfaststart
$qtfaststart -l 曾经的你.mp4
ftyp (32 bytes)
moov (6891 bytes)
free (8 bytes)
mdat (3244183 bytes)
$ffprobe 曾经的你.mp4 -show_frames | grep -E 'pict_type|coded_picture_number|pkt_size'
pkt_size=28604
pict_type=I
coded_picture_number=0
pkt_size=145
pkt_size=479
pkt_size=568
pict_type=B
coded_picture_number=3
pkt_size=476
pkt_size=531
pkt_size=1224
pict_type=B
coded_picture_number=2
pkt_size=703
2、关于预加载的时机问题
3、关于预加载库AndroidVideoCache
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
Any Problem in computer science can be sovled by another layer of indircetion.
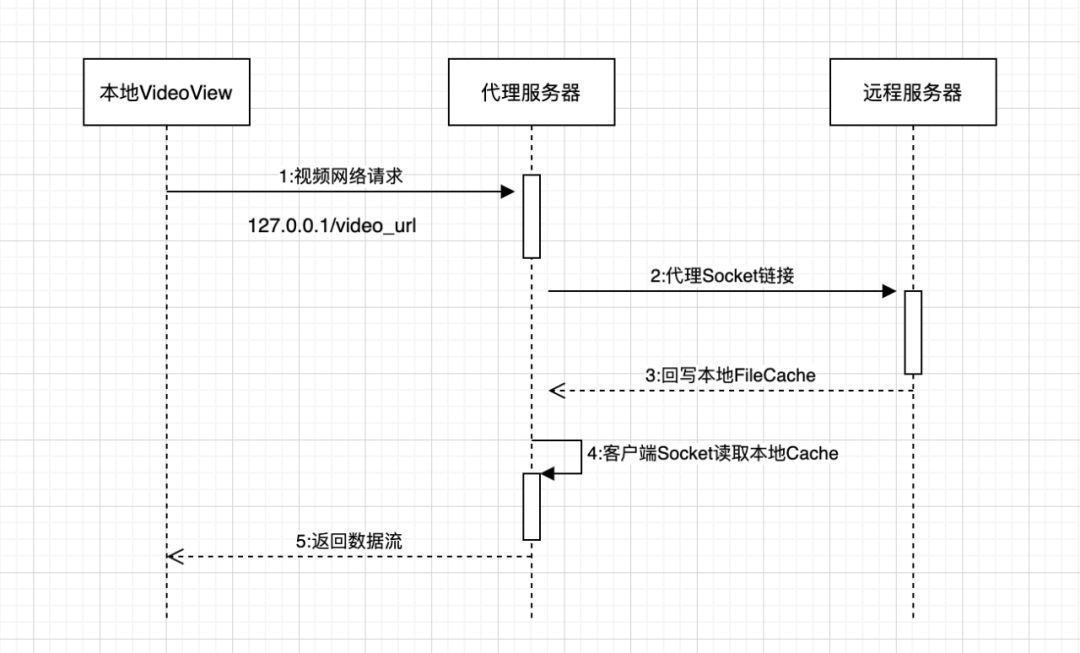
// in HttpProxyCacheServer.java
static final int PRELOAD_CACHE_SIZE = 300 * 1024;
public void preload(Context context, String url, int preloadSize) {
socketProcessor.submit(new PreloadProcessorRunnable(url, preloadSize));
}
private final class PreloadProcessorRunnable implements Runnable {
private final String url;
private int preloadSize = PRELOAD_CACHE_SIZE;
public PreloadProcessorRunnable(String url, int preloadSize) {
this.url = url;
this.preloadSize = preloadSize;
}
@Override
public void run() {
processPreload(url, preloadSize);
}
}
private void processPreload(String url, int preloadSize) {
try {
HttpProxyCacheServerClients clients = getClients(url);
clients.processPreload(preloadSize);
clientsMap.remove(url);
} catch (ProxyCacheException | IOException e) {
e.printStackTrace();
}
}
public void stopPreload(String url) {
try {
HttpProxyCacheServerClients clients = getClientsWithoutNew(url);
if(clients != null) {
clients.shutdown();
}
} catch (ProxyCacheException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
// HttpProxyCacheServerClients.java
public void processPreload(int preloadSize) throws ProxyCacheException, IOException {
startProcessRequest();
try {
clientsCount.incrementAndGet();
proxyCache.processPreload(preloadSize);
} finally {
finishProcessRequest();
ProxyLogUtil.d(TAG, "processPreload finishProcessRequest");
}
}
// HttpProxyCache.java
public void processPreload(int preloadSize) throws IOException, ProxyCacheException {
long cacheAvailable = cache.available();
if (cacheAvailable < preloadSize) {
byte[] buffer = new byte[DEFAULT_BUFFER_SIZE];
int readBytes;
long offset = cacheAvailable;
while ((readBytes = read(buffer, offset, buffer.length)) != -1) {
offset += readBytes;
if (offset > preloadSize) break;
}
ProxyLogUtil.d(TAG, "preloaded url = " + source.getUrl() + ", offset = " + offset + ", preloadSize = " + preloadSize);
}
}
// 仅供学习使用,不适用生产环境
五、浅谈播放器卡顿

1 long ijkmp_get_duration(IjkMediaPlayer *mp)
2 {
3 assert(mp);
4 pthread_mutex_lock(&mp->mutex);
5 long retval = ijkmp_get_duration_l(mp);
6 pthread_mutex_unlock(&mp->mutex);
7 return retval;
8 }
addr2line或者ndk-stack定位到有大量崩溃发生在第5行,mp为空指针导致crash。这个不难猜测,既然App没有crash在第3行的assert语句而崩溃在了后面,说明必定发生了在这把锁控制之外的线程问题。一个简单的解决方案是再次加入判空处理,但此方案依然不能完全杜绝crash。static long ijkmp_get_duration_l(IjkMediaPlayer *mp)
{
if (mp == NULL) {
return 0;
}
return ffp_get_duration_l(mp->ffplayer);
}
// NOTICE: 此方案仍存在线程冲突问题
isPlayerReleased,在播放器销毁之前将此变量置为true,后面对播放器的所有操作都要直接忽略;// in https://github.com/bilibili/ijkplayer/blob/master/android/ijkplayer/ijkplayer-java/src/main/java/tv/danmaku/ijk/media/player/IjkMediaPlayer.java
private static class EventHandler extends Handler {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MEDIA_PREPARED:
player.notifyOnPrepared();
return;
case MEDIA_PLAYBACK_COMPLETE:
player.stayAwake(false);
player.notifyOnCompletion();
return;
case MEDIA_BUFFERING_UPDATE:
long bufferPosition = msg.arg1;
if (bufferPosition < 0) {
bufferPosition = 0;
}
...
isPlayerReleased控制,在重新编译播放器内核之后,线上跟播放器相关的crash几乎消失六、架构、性能优化的意义
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
推荐阅读:
觉得不错,点个在看呗~

评论