
开发实践:代码重构的思考
本文来源:http://r6d.cn/bdxny
“特别说明:这个是一个经验丰富的同事(王洋)写的,内容非常好,转发到我的 blog 上了。
”
写代码的一些原则
写代码的一些原则:
命名规范,含义明确。不同含义的变量和方法在词语、大小写、词组上要有有效的区分。 Never repeat yourself。常量、方法块、处理逻辑尽量少做重复,可以抽象出共用代码的最好抽象出来 代码块职责单一,功能原子化。一段代码、一个方法最好只做一件事情,可以是控制某个流程,组装某个信息等,混在一起不利于后续的修改。 开放扩展,关闭修改。稳定的东西尽量沉到下层,变化暴露到上层。这样做的目的是后续维护代码,尽量多添加,少修改。功能原子化也是为了达到这个目的,只有当功能足够小,耦合性足够低的时候,在添加新功能的时候,才可以不去修改老的,而主要通过扩展的方式增加业务 高内聚,低耦合。达到这个目的不简单,一个基本思路就是尽量让代码处理的事情原子化,然后根据相关性的强弱选择不同的聚合方式。以个人的体会来说,方法用来聚合同一个数据的操作,类用来聚合相关性比较强的一组数据或者操作,模块用来聚合概念上有相似性的数据或者操作,层则用来聚合使用方式相同的数据或者操作。
具体的措施
以下是一些具体的措施:
一、命名
常量:所有字母大写,不同单词用下划线隔开,如METHOD_TIME_THREAD; 变量名和方法名:使用小驼峰式命名结构,第一个单词字母小写,后续单词的第一个字母大写,单词直接拼接在一起,如outNo,orderId; 接口名和类名:大驼峰式命名结构,所有单词的第一个字母都大写; 数据库字段、网络请求字段:所有字母小写,单词之间用下划线隔开,如out_no,order_id。
二、常量
对于固定的字符串、整数,尽量使用常量,避免“魔法”字符串和整数(称之为魔法的意思是,可能稍一不注意,东西取错了都不知道) 常量是无状态的,所以常量类和常量的命名上,最好别带太强的业务信息,可以直接使用字面意思命名,否则当别人使用该常量的时候,名字会很奇怪。 常量类尽量集中存放,但不要分的太细。集中放是因为常量算是公共资源,理论上所有代码都要共用,放的越集中就容易让后续开发者发现,不至于重新定义一模一样的常量。不要分的太细也是为了让后续开发者容易识别,如果每个业务都分一套常量,到时候常量类就会迅速膨胀,而且起不到常量的作用
这里举一个例子:
HashMapcontentMap = new HashMap();//放入一个数据的时候是这样的:contentMap.put("orderId",orderId);// 取出数据的时候是这样的:String orderId = contentMap.get("orderId");
这里的“orderId”字符串就称之为魔法字符串,其实很容易写错。而且假如以后这个参数改个名字叫:movieOrderId,那这些字符串就得改很多处,而且不能通过搜索特定字符串一次性替换(因为很多变量名也叫orderId,而且并不见得所有的“orderId”都应该改)。而如果使用常量来代表“orderId”字符串,就在key形成了一致性约束,以后改名字的时候,只需要改常量的内容,put和get操作就自动一致了。这是一个简单的变量“高内聚”
三、删掉未使用代码
当前不用的代码一定要删掉,一是不整洁,二是影响后续rd的判断,不是自己写的删也不合适,用也不合适。 没想好的代码不要写一半放在原地,应该删掉代码,写个todo提示
四、代码布局
根据重要程度对变量、方法排个基本次序。人在阅读理解的时候,会遵从类似金字塔的逻辑,所以要让读代码的人先看到重要的,再看次要的。 相关的代码要集中在一起,不相关的代码要用空行隔开,这样便于快速浏览代码的逻辑。 变量顺序:静态常量、成员变量,所有变量按照重要性顺序排列。这样做是因为人的大脑有首因效应,对最先看到的事物记忆最深刻。 方法顺序:构造方法,静态方法、私有成员方法、共有成员方法,也需要按照重要性顺序排列,具体顺序可以合理权衡。理论上,静态方法,多为工具类型的方法,和当前类有强绑定的关系,可以放在靠前的位置,如果没有强绑定的关系,可以考虑抽离到外部类,避免和当前类含糊不清。私有成员方法和共有成员方法需要根据方法的重要性确定其顺序,比如提供重要服务的接口需要放最前,而get、set方法,肯定是要放最后。 方法内代码根据功能分块,例子(不同的功能要隔开,有关系的功能最好集中在一起,用序号标识出流程)
五、注释
重要的系统尽量多加,比如支付、订单这种,改动风险较高,能说明的最好是说明下。多写注释的原因主要在于代码是英文为主,以中文为母语的人常常会将同一个单词理解成不同的含义,比如voucher这种多义词,既可以理解成单据、凭证,也可以理解为代金卷。特别是对于简写和隐形约定,很难做到每个人都理解,所以尽量多写些注释吧 重要流程、算法逻辑、特殊判断一定要加注释, 接口入参、返回值的限定,可能出现的各种情况最好用注释说明
六、日志
日志要分类,最好一个业务一个日志,混在一起会难以统计和排查问题 日志要分级,error,info,debug要分清。error日志就是要认真对待的,出任何问题都要小心谨慎;info日志是打提示信息,比如请求参数、返回内容、重要流程的节点信息等; 日志的重点要清晰,一般模式是:先打印日志的目的(比如异常就说什么异常,提示就说什么参数的提示),然后接上重要的参数信息,参数可用你代码中使用到的参数,这样看到日志后,可以更快速的对应到具体的代码上,方便排查问题。
七、异常和中断处理
尽量统一处理异常和中断,不要到处都是try-catch模块或者if-else的判断返回,一般是在业务接口上统一处理异常,下层逻辑在出现非预期的情况时,尽量抛到上层来统一处理。这里提供一种参考的异常处理和代码中断模式。我们先可以继承RuntimeException,实现一个自己的异常类TransException,由于RuntimeException是可以不捕获的异常,所以当TransException抛出来的时候,从下到上的方法都不需要throw,也不需要try-catch,这样我们就可以在最上层catch住,统一处理异常。 分析上面两个类,异常类包括:错误枚举(包括错误码,错误信息)、详细的错误信息。当我们遇到可掌握的异常时,可以构造一个特定的TransException对象,将特定的错误枚举,具体的异常信息(比如具体的参数异常信息,错误堆栈,可展示的下层业务异常信息等)填到详细信息里边,然后在任意地方throw,由上层统一打印错误信息,组装返回内容,而不用一层一层的return false。 出了未知异常,尽量掌控所有可以掌控的异常。达到这个目的主要有以下做法:1、操作数据前要检查,有问题要细化错误场景;2、try-catch异常尽量精细,不要try-catch太多代码。要么是一个流程,要么是一个数据操作,catch住异常要很清楚的知道这是什么类型的异常,将错误场景细化
八、模块划分
模块划分的目的是为了“高内聚”,把具有相同意义的代码和数据放在一起,一是方便了阅读和查找,二是可以将稳定的代码沉到下层,变化抽象到上层。下图是我们之前商量过的代码分层框架, 不一定要完全按照这种模式来,但可以有意的按照这种思路去把代码分离开。
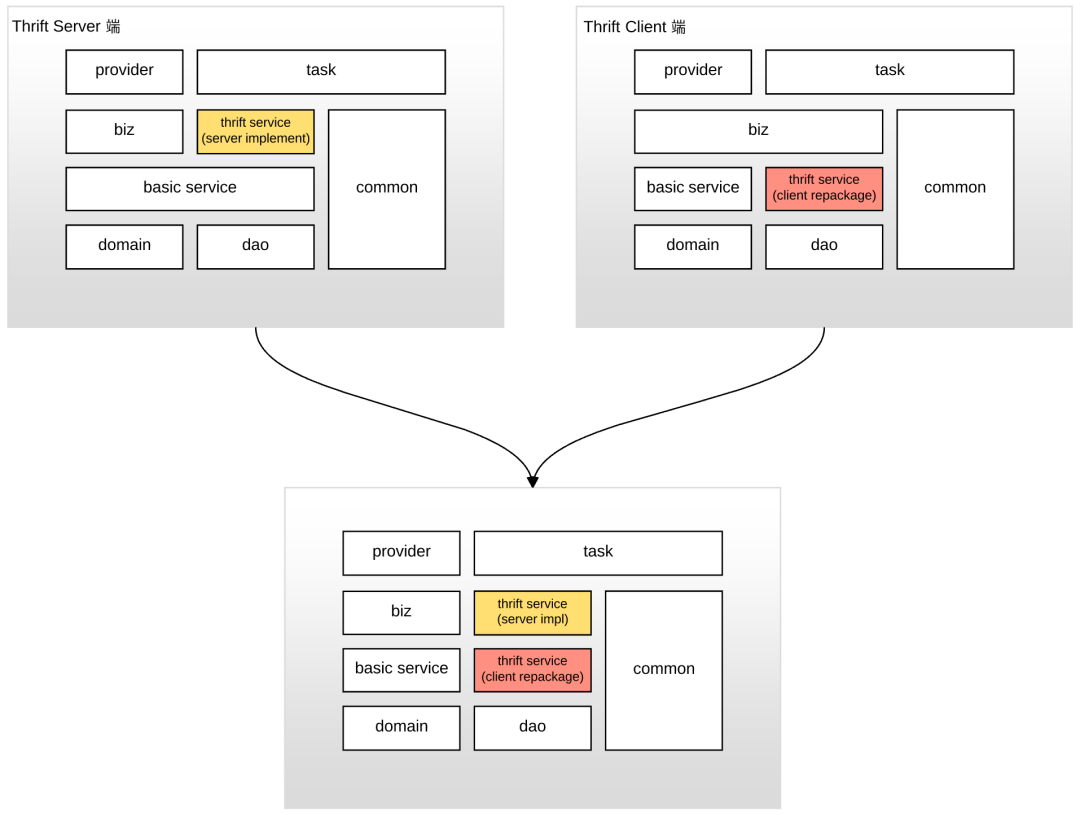
从下到上来说各层代表含义:
domain:主要是领域对象,包括枚举、常量、VO对象,服务之间传递信息所需要的model等等 dao:数据库对应的DO对象,DAO对象等,专门负责处理数据库的东西 service:主要负责提供原子服务,包含外部rpc服务的封装,相对原子的数据处理过程,对dao层的操作等等 thrift service(server impl):thrift server 端,基于 basic service,实现 thrift service,一般需要将 domain model 封装为 thrift model。 thrift service(client repackage):thrift client 端,基于 thrift service,重新封装一层 service,一般包含:thrift model 与 domain model 之间的转换、Thrift Exception 异常转换等。 biz:主要处理各种业务流程,组合service层的原子服务达到某个目的,处理某个业务 provider:不直面客户端的也可以没有这个模块,主要负责接收外部请求,做权限管理(比如验证登陆)、参数校验,然后调用biz层的接口完成做具体业务处理 task:用于处理定时任务、外部调度任务的模块,负责接受任务消息或者调度请求,然后调用biz层的接口完成某件任务 common:主要是一些工具类(时间、MD5工具等等),以及一些对象转换的conventor
这样分模块的目的是为了减少代码的耦合性,把相关的数据和代码抽象的更集中,每当你想用某个常量、枚举、对象的时候,你大致扫一下domain就知道当下有什么东西,不致于针对同一个东西写好几份代码。而对于service来说,站在原子服务的角度来说,因为service足够小,所以增加新业务时,service是可以不修改的,而只需要添加服务就可以,biz层也只需要添加逻辑,组合service的服务就可以达到目的,这样就达到了“开放扩展,关闭修改”的目的,降低修改代码带来的风险。
九、使用模型
处理外部数据时,尽量使用自己的业务模型,除非特别简单的http回应,其它的处理都是应该封装自己的model的。
为什么要把外部数据映射成model呢?
原因一:让看代码的人,知道你当下的业务在处理的过程中,到底和哪些参数相关,他要重点关注哪些参数。如果没有model,直接操作外部数据,就会将这些知识散乱的分布在各处的代码,一旦业务有变化,就不知道加减参数会不会对之前的业务有影响 原因二:转换成model也是为了在一开始就对所需要的参数进行合法性检查,业务能不能做最好在获取参数时,就直接判断,不能走了一些流程后,突然发现参数不可用,然后再中断流程,这样会消耗服务的性能。而转换model也是为了对所有参数进行一次性的合法性检查。 原因三:外部数据映射成model,会在添加或者删除数据时造成一定的约束,对比操作json,添加和删除都较为随意,既不能在类型上进行约束,也不能在对应关系上强制约束,后续开发者为了图省事,写着写着就乱的没法用了。
模型要有业务含义,在传递给服务时,一定要和该服务有很强的业务关系,不要为了简单使用DO,或者参数差不多、但业务不相关的model图省事。对于没有形成强业务绑定的model,经常会因为一个业务的修改,导致当下业务也需要联动的修改。要降低耦合性
避免超级model,做任何业务,都把参数往一个model中塞。这样一是让看代码的人毫无头绪,不知道到底哪些参数和当下业务相关,二是让修改的人很担心,去掉一个参数会不会影响到多个业务。所以尽量避免使用公共model,如果确实参数重合度比较高的,可以考虑model之间的有意义的继承。
多用模型,少用hashmap。hashmap当时它相当于一个自由模型,啥都可以塞,啥都可以取,使用上是方便,但是没有套上任何业务信息,业务越大,修改越多,就会越不可控。每次修改都会造成一些隐患。