
在PyTorch中进行双线性采样:原理和代码详解

极市导读
本文记述了PyTorch中双线性插值和双线性采样操作的原理和代码,是一篇很清晰的笔记。>>加入极市CV技术交流群,走在计算机视觉的最前沿
在pytorch中的双线性采样(Bilinear Sample)
FesianXu 2020/09/16 at UESTC
前言
pytorch中对应的函数是torch.nn.functional.grid_sample,本文对该操作的原理和代码例程进行笔记。如有谬误,请联系指正,转载请联系作者并注明出处,谢谢。双线性插值原理
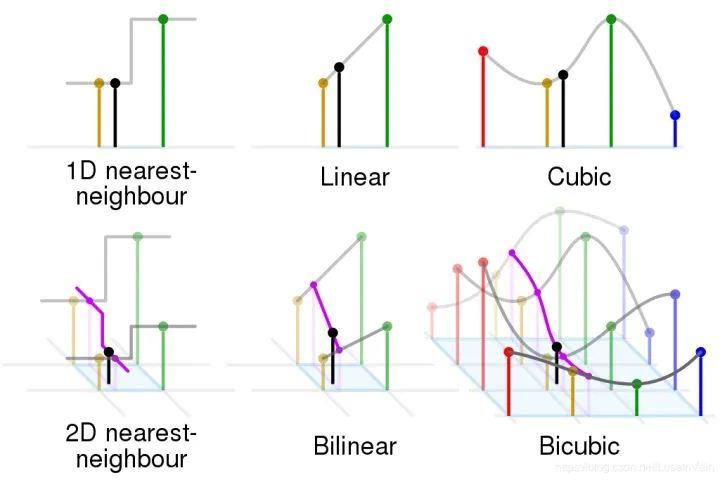
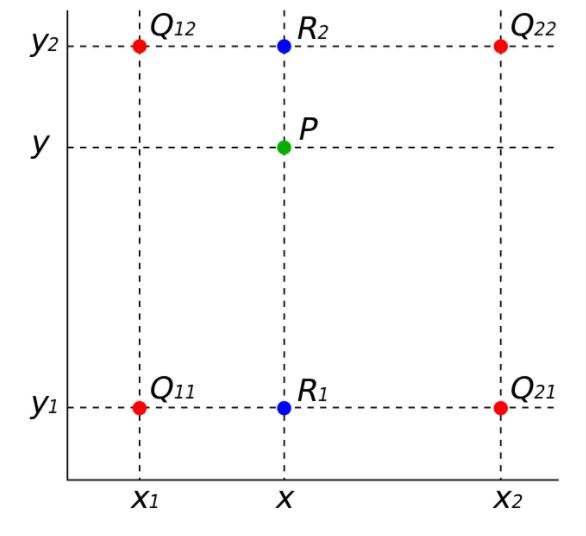
双线性采样以及grid_sample
torch.nn.functional.grid_sample [1],该函数主要输入一个形状为的input张量,输入一个形状为的grid张量,输出一个形状为的output张量。batch批次,我们主要关注后面的维度的代表意义。输入的grid是一个大小的空间位置矩阵,其中每个元素都代表着一个二维空间坐标,该坐标指明了在input上采样的坐标,而输出张量的每个位置output[n,:,h,w]的值,取决于这个输入input和采样坐标的值(通过双线性插值形成)。通过这个函数,可以通过指定原图的不同坐标位置,实现图片的变形(deformation)等,在很多研究中有着广泛地应用[2]。grid的每一个坐标都是归一化到了之间的,我们举一个简单的代码例子,明晰下细节。import torch.nn.functional as F
import torch
inputv = torch.arange(4*4).view(1, 1, 4, 4).float()
print(inputv)
'''
输出尺寸为(1,1,4,4)
输出为:tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
'''
# 生成grid,这个grid大小为(1,8,8,2),空间尺寸而言是原输入图片的两倍。
d = torch.linspace(-1,1, 8)
meshx, meshy = torch.meshgrid((d, d))
grid = torch.stack((meshy, meshx), 2)
grid = grid.unsqueeze(0) # add batch dim
# 进行双线性采样,其中指定align_corners=True保证了输出的整个图片的角边像素与原输入的一致性。
output = F.grid_sample(inputv, grid,align_corners=True)
print(output)
'''
tensor([[[[ 0.0000, 0.4286, 0.8571, 1.2857, 1.7143, 2.1429, 2.5714,
3.0000],
[ 1.7143, 2.1429, 2.5714, 3.0000, 3.4286, 3.8571, 4.2857,
4.7143],
[ 3.4286, 3.8571, 4.2857, 4.7143, 5.1429, 5.5714, 6.0000,
6.4286],
[ 5.1429, 5.5714, 6.0000, 6.4286, 6.8571, 7.2857, 7.7143,
8.1429],
[ 6.8571, 7.2857, 7.7143, 8.1429, 8.5714, 9.0000, 9.4286,
9.8571],
[ 8.5714, 9.0000, 9.4286, 9.8571, 10.2857, 10.7143, 11.1429,
11.5714],
[10.2857, 10.7143, 11.1429, 11.5714, 12.0000, 12.4286, 12.8571,
13.2857],
[12.0000, 12.4286, 12.8571, 13.2857, 13.7143, 14.1429, 14.5714,
15.0000]]]])
'''
grid很简单,单纯只是在x,y两个维度,都把均分为了8份。grid到实际坐标的映射为:grid坐标为的值。我们打印出grid[0,1,1,:],发现这个归一化坐标值为tensor([[-0.7143, -0.7143]]),那么通过反归一化映射,也就是式子(1)后,有实际图片坐标为,这个时候我们发现这个坐标不是整数,因此为了求出这个坐标的像素值,我们要通过之前谈到的双线性插值去估计。input也可以是的5D输入,该输入考虑的是对视频进行处理。本文中只考虑了图片数据,不过原理是类似的,不再赘述。推荐阅读

评论