
只需一行代码,就能导入所有的Python库?
今天给大家介绍一个懒人Python库——Pyforest。
使用一行代码,就能导入所有的Python库(本地已经安装的)。
GitHub地址:
https://github.com/8080labs/pyforest
/ 01 / 介绍
Python因为有着成千上万个功能强大的开源库,备受大家的欢迎。
目前,通过PyPl可以导入超过23.5万个Python库,数量庞大。
在大家平常的实践当中,一般都是需要导入多个库或者框架来执行任务。
而且每当新建一个程序文件时,都需要根据自己的需求导入相关的库。
如果是相同类型的任务,比如想做一个数据可视化的小项目,可能会一直使用到某个库。
如此,反复编写同一条import语句,就算是复制粘贴,也会感觉到麻烦,这时Pyforest库就可以上场了。
Pyforest是一个开源的Python库,可以自动导入代码中使用到的Python库。
在进行数据可视化的时候,一般都需要导入多个库,比如pandas、numpy、matplotlib等等。
使用了Pyforest,每个程序文件中就不需要导入相同的Python库,而且也不必使用确切的导入语句。
比如下面这行代码,就可以省略掉。
from sklearn.ensemble import RandomForestClassifier
在你使用import语句导入Pyforest库后,你就可以直接使用所有的Python库。
import pyforest
df = pd.read_csv('test.csv')
print(df)
你使用的任何库都不需要使用import语句导入,Pyforest会为你自动导入。
只有在代码中调用库或创建库的对象后,才会导入库。如果一个库没有被使用或调用,Pyforest将不会导入它。
/ 02 / 使用
安装,使用以下命令安装Pyforest。
pip install pyforest -i https://pypi.tuna.tsinghua.edu.cn/simple
安装成功后,使用import语句导入它。
现在,你可以直接使用相关的Python库,无需编写import导入。
先以jupiter notebook为例,我们没有导入pandas、seaborn和matplotlib库,但是我们可以通过导入Pyforest库直接使用它们。
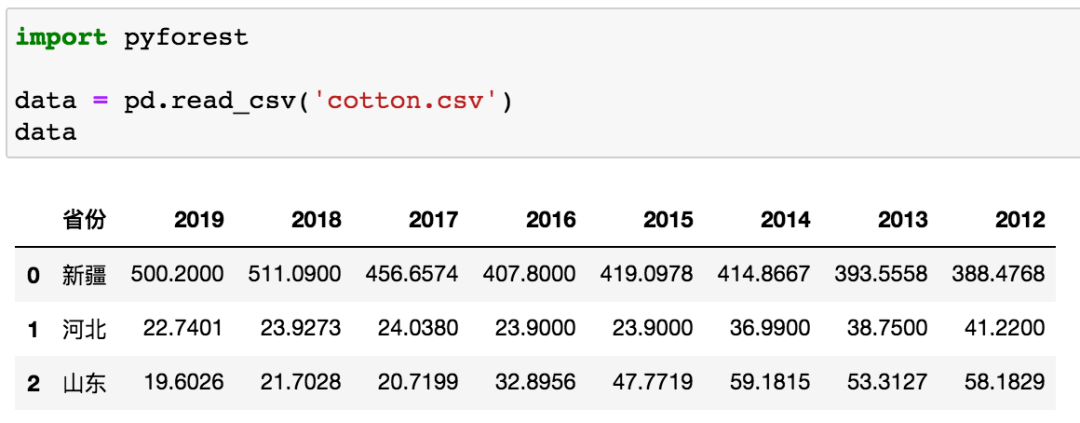
读取数据,这个是国内棉花产量排行前三的省份,新疆全国第一(数据来源:国家统计局)。
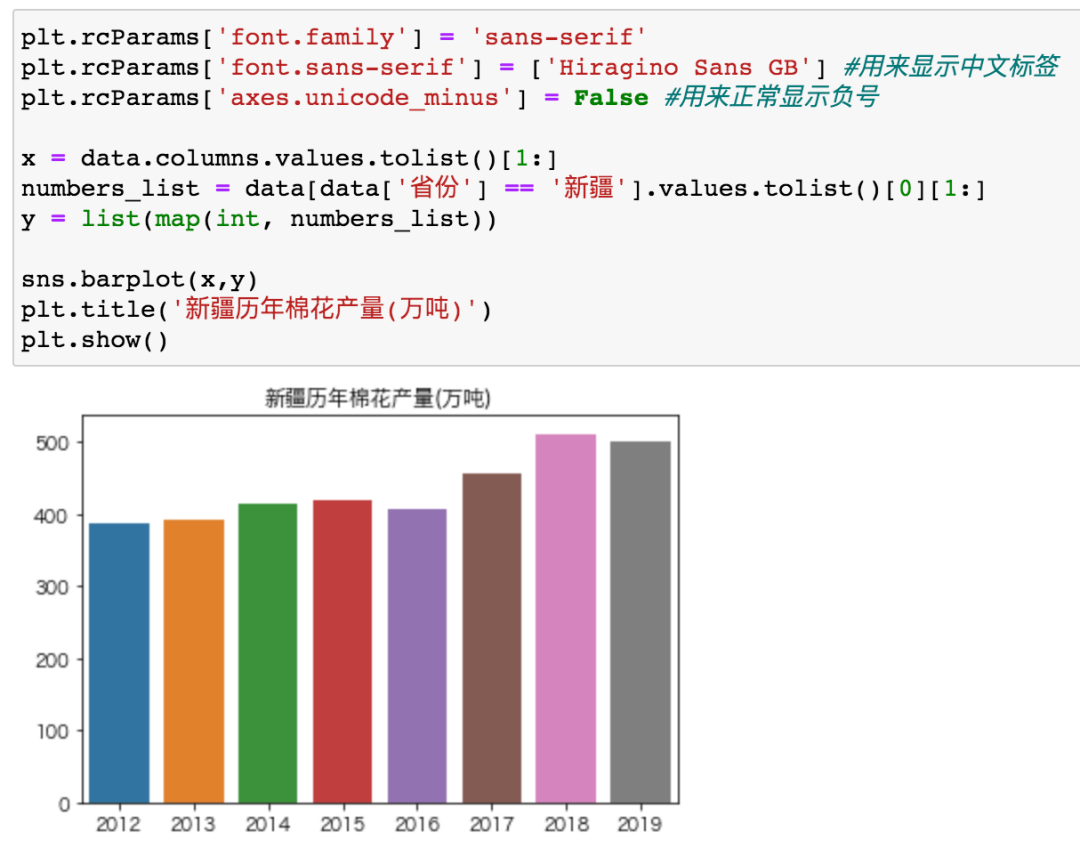
那么Pyforest可以导入所有库吗?
目前这个包包含了大部分流行的Python库,比如
pandas as pd
NumPy as np
matplotlob.pyplot as plt
seaborn as sns
除了这些库之外,它还提供了一些辅助的Python库,如os、tqdm、re等。
如果你想查看库列表,可以使用dir(pyforest)进行查看,内置的是68个库。
import pyforest
print(len(dir(pyforest)))
for i in dir(pyforest):
print(i)
-------------------------
68
GradientBoostingClassifier
GradientBoostingRegressor
LazyImport
OneHotEncoder
Path
RandomForestClassifier
RandomForestRegressor
SparkContext
TSNE
TfidfVectorizer
...
如果没有的话,可以进行自定义添加,在主目录中的文件写入import语句。
示例如下。
vim ~/.pyforest/user_imports.py
添加语句,此处便能在代码中使用requests这个库。
# Add your imports here, line by line
# e.g
# import pandas as pd
# from pathlib import Path
# import re
import requests as req
~
~
"~/.pyforest/user_imports.py" 7L, 129C
这回我们在PyCharm中来实验一下。
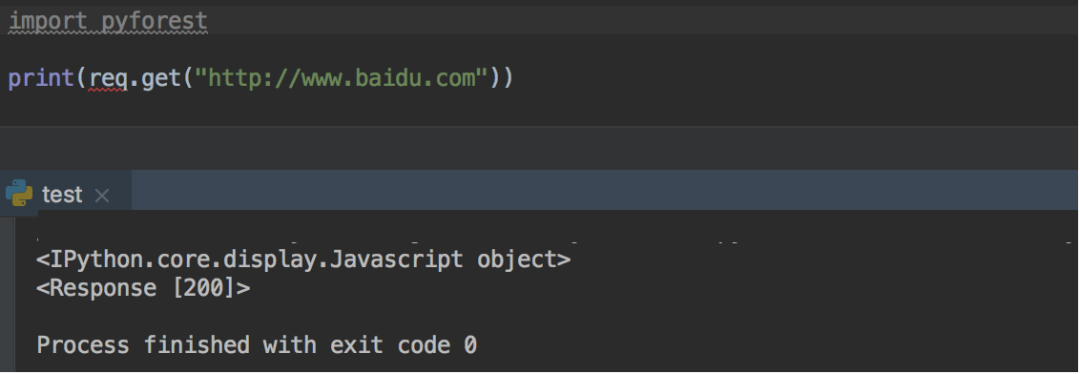
发现PyCharm的自动补全的功能失效了,看来这个库还是比较适合jupyter notebook(自动补全代码还可以使用)。
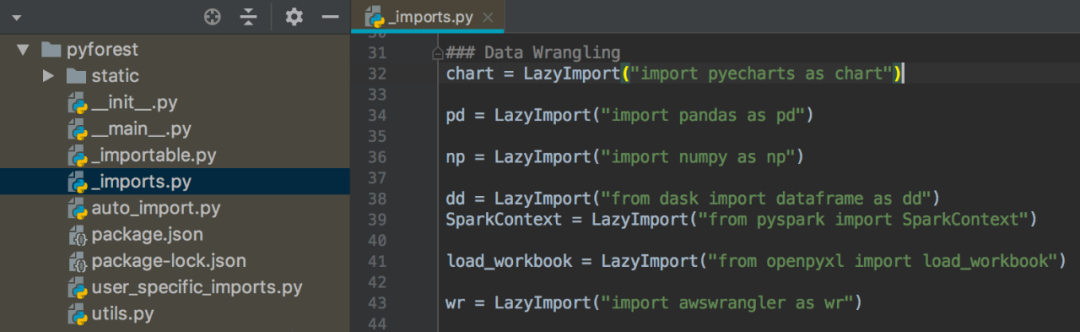
除了上面这个地方可以自定义添加,还可以在库的_import.py文件中添加。
此处以Pyechars为例,缩写为chart。
可视化代码如下。
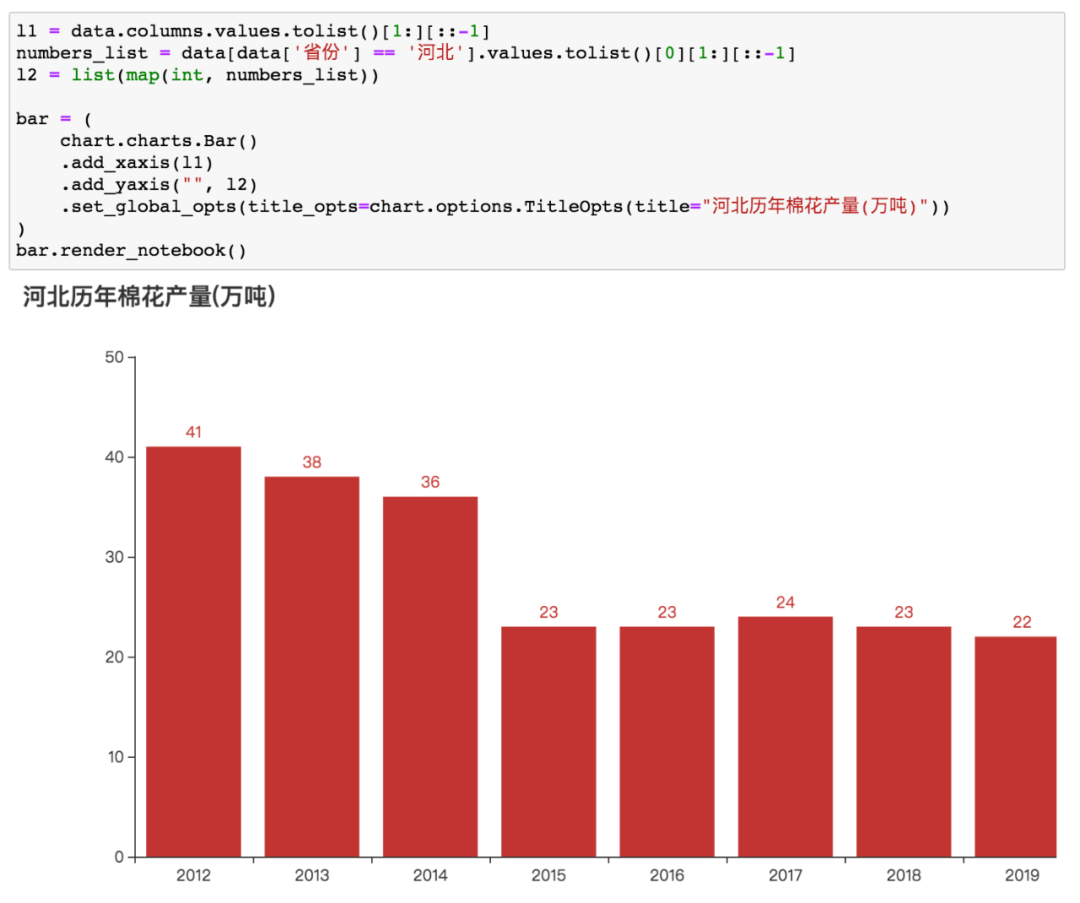
新疆棉花产量年年上升,其它省份年年下降...
最后Pyforest还提供了一些函数来了解库的使用情况。
# 返回已导入并且正在使用的库列表
print(pyforest.active_imports())
--------------------------------
['import pandas as pd', 'import requests as req', 'import pyg2plot']
# 返回pyforest中所有Python库的列表
print(pyforest.lazy_imports())
--------------------------------
['import glob', 'import numpy as np', 'import matplotlib.pyplot as plt'...]
只有代码中有使用到的库,程序才会import进去,否则不会导入的哦!
/ 03 / 总结
使用Pyforest库有时候确实是可以节省一些时间,不过也是有弊端存在的。
比如调试的时候(大型项目),可能会很痛苦,不知道是哪里来的库。
所以建议大家,在一些独立的脚本程序中使用,效果应该还是不错的。
加入知识星球【我们谈论数据科学】
400+小伙伴一起学习!
· 推荐阅读 ·