
【python】app未注册用户自动筛选
本文目标:手把手教一名零基础员工开发一款python桌面应用程序
项目目标:领导给了两张表,一张是全部员工表,一张是注册用户表,让统计未注册用户的详细清单
前期准备:自学python基本语法,能看懂python语句即可
结果展示:

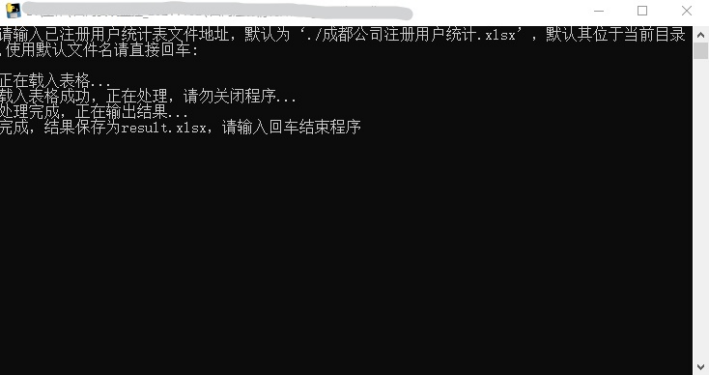
上图为运行结果。
接下来我将从头开始讲解。
一、环境搭建
Python的环境搭建很简单,在官网下载后直接安装即可,网址为:
“https://www.python.org/downloads/windows/”。注意选择版本为3.9,因为后面用到的打包软件不支持3.10。
安装成功后确认一下是否将安装目录添加到环境变量里,若没有添加需要自行添加。接下来安装本项目需要用到的模块pandas,openpyxl,pywin32,pyinstaller,使用pip命令安装即可(pip是python自带的包下载软件),在命令行敲下以下代码:
pip config set global.index-url
https://pypi.tuna.tsinghua.edu.cn/simple
上面这行代码可选择执行,它的作用是修改pip的下载源地址,默认的地址在国外服务器,速度很慢,这里修改为清华大学的开源镜像站。
在CMD命令行窗口依次输入以下代码:
pip install pandas
pip install openpyxl
pyp install pywin32
pip install pyinstaller
如果无法安装,提示pip版本太低,请按照提示,执行“pip install --upgrade pip”来更新pip。
上面安装的4个模块,pandas用于从excel中取数,处理,以及写入excel文档。openpyxl是pandas依赖的一个包,pyinstaller是打包工具,pywin32是pyinstaller在windows平台打包需要依赖的包。
二、数据审查
环境搭建好了,可以开始我们的项目了,首先对数据进行审查。
观察“成都公司全部用户.xlsx”表,其数据格式如下:
彭** | P*******9 | /xx公司/xx部门/ |
曾** | Z*******4 | /xx公司/xx部门/ |
于** | Y*******2 | /xx公司/xx部门/ |
再观察“成都公司注册用户统计.xlsx”表,其数据格式如下:
姓名 | 部门 | 性别 | 企业简称 | 使用状态 |
刘** | /xx公司/xx部门/ | 男 | XX | 已通知 |
王** | /xx公司/xx部门/ | 男 | XX | 已通知 |
黄** | /xx公司/xx部门/ | 男 | XX | 已通知 |
任务目标是从前表中筛选出不在后表中的人,显然仅凭名字是有可能因为同名而出错的,所以要根据名字和部门两个信息来进行筛选。
三、代码编写
了解了数据,确定了方案后就可以开始编程了。
首先导入我们需要的模块:
import pandas as pd然后读取用户输入的文件名(设置默认文件名更方便使用):
filename=input()if len(filename)<1 :filename="./成都公司注册用户统计.xlsx"
获取到文件名后就可以读取文件了:
df_all = pd.read_excel("./成都公司全部用户.xlsx",header=None)df = pd.read_excel(filename,header=None)
这里因为“成都公司全部用户.xlsx”是固定不变的,所以作为资源文件放在项目目录,不需要用户输入文件名。其中df和df_all两个变量是DataFrame类型,和二维数组比较类似,可以很方便的存储表格。pandas.read_excel()函数可以读取excel文档,第一个参数是文件名,参数header设置表格是否有表头,”None”表示没有,设置成0或[0,1,2]这样的值则意味着表格的前几行作为表头。
接下来对获取到的数据进行处理:
df=df.drop(index=0)df_all[3]=df_all[0]+df_all[2]df[2]=df[0]+df[1].apply(lambda x: x.partition("xx公司")[2]+"/")all=[]all=df_all[3].values.tolist()done=[]done=df[2].values.tolist()
将第一张表的第1列和第3列合并,第二张表的第1列和第2列的一部分内容合并,并在尾部补充一个字符“/”使得,两张表的部门格式一致。最后以合并得到的列生成列表,以便后续处理。
使用filter函数筛选出未注册的人员,再转换成列表存储到result变量中:
result=[]result = list(filter(lambda x:x not in done, all))
filter函数接受一个函数变量作为参数,这个函数必须接受一个参数并返回布尔值,filter依据这个值来筛选all列表中的每一项。
至此,我们得到了我们想要的结果,现在只需要把结果稍微处理一下,然后输出到一个excell表格即可:
formatresult=[] #将结果转换成多列,便于审查unworklist=[] #挑选出不在岗的人for x in result:if x.rfind('不在岗')>0:unworklist.append(x)else:formatresult.append(x.split('/'))df_result=pd.DataFrame(formatresult)df_unwork=pd.DataFrame(unworklist)print("处理完成,正在输出结果...")wr=pd.ExcelWriter("./result.xlsx")df_result.to_excel(wr,"Sheet1")df_unwork.to_excel(wr,"Sheet2")wr.save()wr.close()
这里将之前合并的列以“/”为间隔拆分为多列,便于审查,也顺便把不在岗的人员筛选了出去存入另一张子表。最后使用ExcelWriter将结果分别写入两张子表保存。
四、打包项目
为了使得编写好的python程序在所有windows电脑上都能运行,我们需要把程序打包成exe可执行文件。这就要用到一开始下载的模块pyinstaller。
进入到项目目录,打开CMD命令行窗口,执行命令:
pyinstaller -F igw-uninstaller.py
其中”igw-uninstaller.py”是程序文件名,等待程序执行完毕后会在项目目录里生成两个文件夹“build”和“dist”以及一个“.spec”文件,“build”保存了一些生成过程中的日志文件,“.spec”文件为生成过程中产生的目录文件。“dist”文件夹中保存的则是最终生成的“.exe”文件,默认以程序文件名一致。
将资源文件“成都公司全部用户.xlsx”放到和可执行文件同级目录下,就可以运行程序了,双击运行一下吧!
至此,未注册用户的详细清单全部理出,并存入result.xlsx。
五、后记
本文主要介绍了一个简单的python桌面应用程序实现方式,阅读本文能快速了解一个python程序的设计,开发,与打包发布过程,希望能帮助读者了解python,开发一个python桌面程序也不是那么难嘛!后面有更复杂的应用场景我们还会进行UI的开发。
开源代码:
#app安装统计相关函数from numpy import format_parserimport pandas as pdprint("请保证‘成都公司全部用户.xlsx’文件与本程序位于同一目录,且文件名一致")print("请输入已注册用户统计表文件地址,默认为‘./成都公司注册用户统计.xlsx’,默认其位于当前目录,使用默认文件名请直接回车:")filename=input()if len(filename)<1 :filename="./成都公司注册用户统计.xlsx"print("正在载入表格...")df_all = pd.read_excel("./成都公司全部用户.xlsx",header=None)df = pd.read_excel(filename,header=None)print("载入表格成功,正在处理,请勿关闭程序...")df=df.drop(index=0)df_all[3]=df_all[0]+df_all[2]df[2]=df[0]+df[1].apply(lambda x: x.partition("xx公司")[2]+"/")all=[]all=df_all[3].values.tolist()done=[]done=df[2].values.tolist()#现在我们要得到在all列表里面不在done列表里面的result=[]result = list(filter(lambda x:x not in done, all))formatresult=[] #将结果转换成多列,便于审查unworklist=[] #挑选出不在岗的人for x in result:if x.rfind('不在岗')>0:unworklist.append(x)else:formatresult.append(x.split('/'))df_result=pd.DataFrame(formatresult)df_unwork=pd.DataFrame(unworklist)print("处理完成,正在输出结果...")wr=pd.ExcelWriter("./result.xlsx")df_result.to_excel(wr,"Sheet1")df_unwork.to_excel(wr,"Sheet2")wr.save()wr.close()input("完成,结果保存为result.xlsx,请输入回车结束程序")
往期精彩回顾 本站qq群554839127,加入微信群请扫码: