
用 Python 筛选收益最优的加密货币

https://github.com/CyberPunkMetalHead/crypto-performance-tracker
coins.txt。在此文本文件中,放入一些您想要分析的币种名称。它们需要包含配对符号,并且每行必须是 1 个货币,不能有逗号:BTCUSDT
ETHUSDT
BNBUSDT
binancedata.py 文件。我们将使用此文件轮询 Binance API 以获取我们需要的金融数据。由于我们使用的是开放端口,因此不需要 API 密钥和密码。# needed for the binance API and websockets
from binance.client import Client
import csv
import os
import time
from datetime import date, datetime
client = Client()
def get_coins():
with open('coins.txt', 'r') as f:
coins = f.readlines()
coins = [coin.strip('\n') for coin in coins]
return coins
def get_historical_data(coin, since, kline_interval):
"""
Args example:
coin = 'BTCUSDT'
since = '1 Jan 2021'
kline_interval = Client.KLINE_INTERVAL_1MINUTE
"""
if os.path.isfile(f'data/{coin}_{since}.csv'):
print('Datafile already exists, loading file...')
else:
print(f'Fetching historical data for {coin}, this may take a few minutes...')
start_time = time.perf_counter()
data = client.get_historical_klines(coin, kline_interval, since)
data = [item[0:5] for item in data]
# field names
fields = ['timstamp', 'high', 'low', 'open', 'close']
# save the data
with open(f'data/{coin}_{since}.csv', 'w', newline='') as f:
# using csv.writer method from CSV package
write = csv.writer(f)
write.writerow(fields)
write.writerows(data)
end_time = time.perf_counter()
# calculate how long it took to produce the file
time_elapsed = round(end_time - start_time)
print(f'Historical data for {coin} saved as {coin}_{since}.csv. Time elapsed: {time_elapsed} seconds')
return f'{coin}_{since}.csv'
coin、since 和 kline_interval。检查函数下方的注释,了解我们将传递给这些参数的正确格式。main.py 文件并安装以下依赖项:
from binancedata import *
import threading
import matplotlib.pyplot as plt
import matplotlib.cbook as cbook
import numpy as np
import pandas as pd
# needed for the binance API and websockets
from binance.client import Client
import csv
import os
import time
from datetime import datetime, date
threads = []
coins = get_coins()
for coin in coins:
t = threading.Thread(target=get_historical_data, args=(coin, '1 Jan 2017', Client.KLINE_INTERVAL_1DAY) ) #'get_historical_data('ETHUSDT', '1 Jan 2021', Client.KLINE_INTERVAL_1MINUTE)
t.start()
threads.append(t)
[thread.join() for thread in threads]
def get_all_filenames():
return [get_historical_data(coin, '1 Jan 2017', Client.KLINE_INTERVAL_1DAY) for coin in coins]
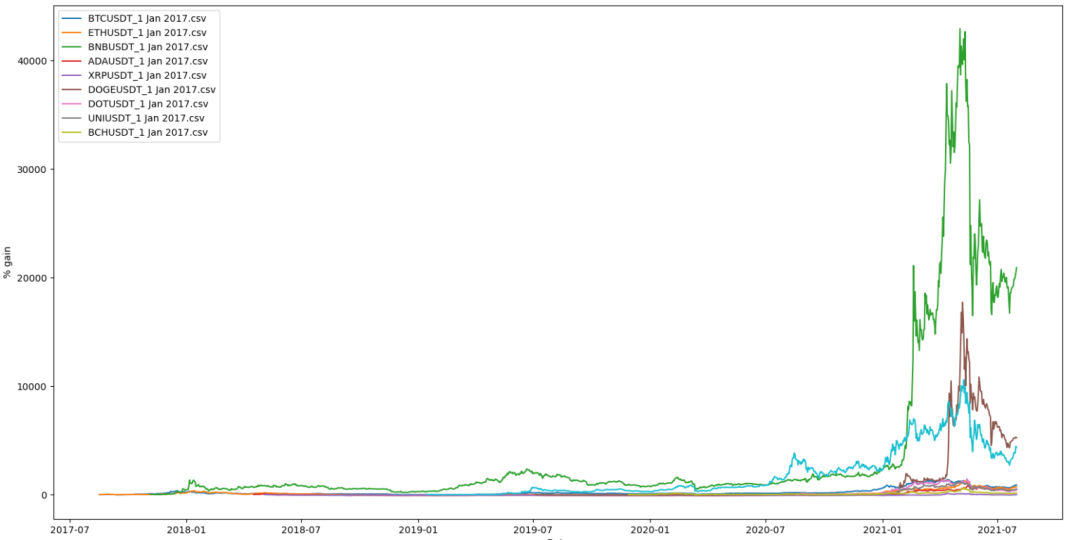
def main():
historical_data = get_all_filenames()
for file in historical_data:
data = pd.read_csv(f'data/{file}')
rolling_percentage = data['close']
rolling_percentage = [(item - rolling_percentage[0]) / rolling_percentage[0]*100 for item in rolling_percentage ]
timestamp = data['timstamp']
timestamp = [datetime.fromtimestamp(item/1000) for item in timestamp]
plt.legend()
plt.plot(timestamp, rolling_percentage, label=file)
plt.xlabel("Date")
plt.ylabel("% gain")
plt.show()
if __name__ == "__main__":
main()
data。大功告成,您现在可以分析您想要的所有代币的历史收益。点赞+留言+转发,就是对我最大的支持啦~
--End--
文章点赞超过100+
我将在个人视频号直播(老表Max)
带大家一起进行项目实战复现
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
点击上方卡片关注公众号,回复:1024 领取最新Python学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 “点赞”就是对博主最大的支持
评论