
偷窥了阿里的图像搜索架构,干货分享给你!

进入21世纪以来,伴随着互联网的高速发展,通过图像和视频来进行需求表达越来越成为大家的习惯。
图像搜索与识别算法使得图像视频内容得以结构化和数字化,以便可以在各种检索和分析引擎中被最大限度地挖掘和利用。
阿里巴巴研发出的移动端以图搜图应用——拍立淘,使用户可以通过拍摄照片,在手机淘宝上迅速找到同款及相似商品,是图像搜索与识别领域极具代表性的落地产品。
因为拍立淘,我们可以在不知道商品品牌、名字等信息的情况下搜索到想要的同类品。
那么,拍立淘的架构设计是怎样的?它是如何将图像搜索与识别算法落地应用的呢?
小编从《深度学习图像搜索与识别(全彩)》一书中“偷窥”到它的架构设计,分享给你!
以下内容节选自《深度学习图像搜索与识别(全彩)》一书!

--正文--
作为电商场景的以图搜图 App,拍立淘于2014年首次上线,现已经成为拥有数千万日活用户的应用。随着业务的发展,也逐步建立了稳定的、可扩展的视觉搜索架构。
下图展示了拍立淘的整个图像搜索架构,分为离线和在线处理流程。
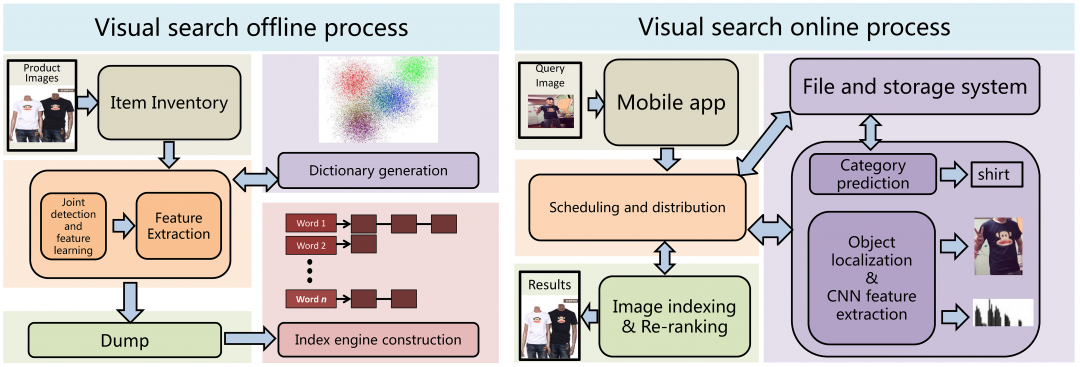
(图1 图像搜索架构)
离线处理主要是指每天生成图像引擎索引的整个过程。
具体过程为,首先构建离线图像选品,通过目标检测在选品图像上提取感兴趣的商品,然后对商品进行特征提取,再通过图像特征构建大规模索引库,并放入图像搜索引擎等待查询。执行完成后,以一定频率更新索引库。
在线处理主要是指用户上传查询图片后,对图像的实时处理到返回最终图像列表的在线步骤。与离线处理相似,给定查询图像后,首先预测其具体的商品类目,然后提取图像目标区域的特征,再基于相似性度量在索引引擎中搜索,最后通过重排序返回搜索结果。
1.图像选品构建
淘宝上有大量不同来源的商品图像,包括商品主图、SKU图、拆箱图等,涵盖了电子商务各个方面的图像。
我们需要从这些海量图像中选择用户相对感兴趣的图像作为宝贝图像进行索引。也就是根据图像附带的类目等属性以及图像质量过滤整个图像库。
由于淘宝上存在太多相同或高度相似的宝贝图像,不过滤会导致最终的搜索结果出现大量相同的商品宝贝,使得用户体验不佳。因此,我们添加了图像选品过滤模块,每天定时选择和删除重复或高度相似的商品图像,并优化索引文件。
2.基于模型和搜索融合的类目预测
考虑到一定的视觉和语义相似性,淘宝类目是基于叶子类目的层次化的类目体系。
类目体系不仅涉及技术问题,也涉及关于消费者认知的商业问题。
目前,我们在拍立淘中先预测图像的类目到14个大类目之一,如服饰、鞋、包等,以缩小图像库的搜索空间。可以采用基于模型和基于搜索的方式来进行类目预测(识别)。
对于基于模型的预测模块,我们采用GoogLeNet V1网络结构来权衡高精度和低延迟,使用包含不同商品类目标签的图像集进行训练。
这里使用单标签分类问题的算法(书中第3章介绍过),作为模型训练的输入图像,根据常用设置将每个图像的大小调整为256像素×256像素,随机裁剪为227像素×227像素 ,使用Softmax 损失函数作为分类任务的损失函数。
对于基于搜索的预测模块,我们不直接训练分类模型,而是利用一个特征模型(参考第6章)和一个待检索数据库完成基于搜索的加权KNN分类。
每当用户输入一张待分类图片,基于搜索的分类方法会先对该图片进行特征提取,然后利用该特征在待检索的数据库中,找出与其最相似的K个图片,根据这些图片的类目标签对输入图片进行预测。
具体来说,我们收集了2亿张附带真实类别标签的图像对
为了提高类目预测的准确性,我们将基于模型和基于搜索的结果再一次加权融合。
其中,基于搜索的方法利用了特征的判别能力,纠正了部分混淆的类目,结合分类模型的优势提高了类目预测的精度。总的来说,我们的方法使类目预测的精度提高了2%以上。
接下来主要介绍基于用户点击行为的检测和特征联合学习方法。
在拍立淘图像搜索场景下,主要挑战来自用户和商家图像之间的巨大差异。
商家的图片通常是高质量的,是在受控环境下用高端相机拍摄的。然而,用户的查询图像通常是用手机摄像头拍摄的,并且可能存在光照、模糊和复杂的背景等问题。
为了减少复杂的背景影响,系统需要具备在图像中定位主体目标并提取主体特征的能力。
下图说明了用户在查询图像过程中主体检测对检索结果的重要性。
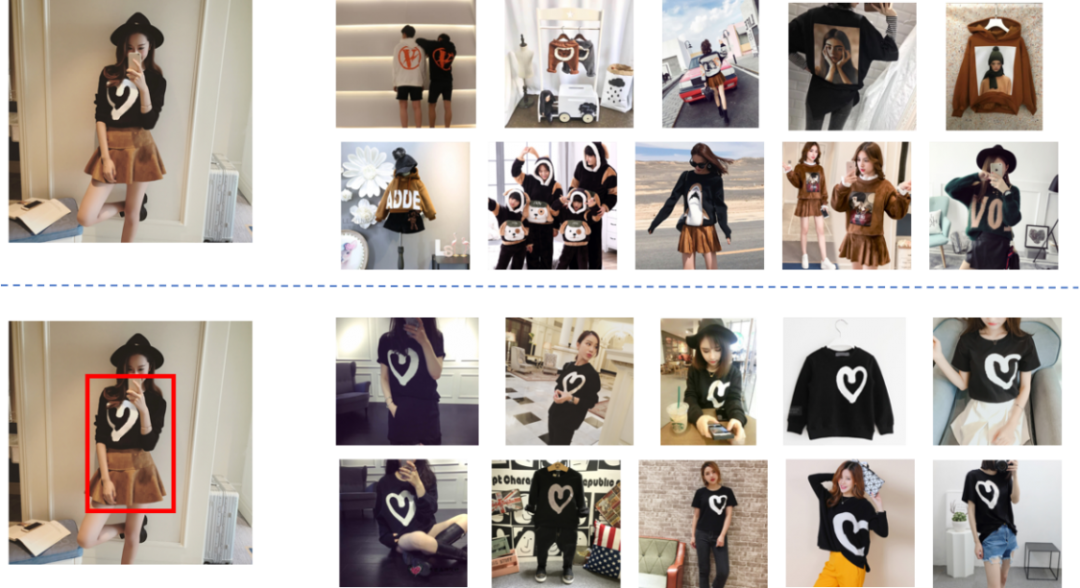
(图2 图中的第一行是没有进行主体检测的检索结果,明显受到了背景干扰;第二行显示了采用主体检测的检索结果,有非常显著的改进效果)
为了在没有背景干扰的情况下使用户实拍图像和商家的索引图像特征保持一致,我们提出了一个基于度量学习的分支网络CNN框架,来联合学习主体检测框和特征表示。
我们最大程度地利用用户点击行为反馈,来挖掘难样本数据。
通过用户点击图像构造有效的三元组,使得能够在不需要进一步对边界框进行标注的情况下,联合学习到对象的检测框和特征表示。
1.三元组挖掘
书中的第6章介绍过用三元组损失函数来学习特征的相似度度量。
在我们的场景中,给定一个输入图像
这意味着需要拉近查询图像
因此,这里采用三元组排序损失函数:
其中,L2表示两个向量之间的L2标准化距离,
这里的主要问题是如何挖掘较难的三元组样本。
一种简单的选择是从与查询图像相同的类目中选择正样本图像,从其他类目中选择负样本图像。但是,负样本图像与查询图像相比,存在较大的视觉差异,导致训练过程中三元组排序损失函数很容易为零,没有贡献任何损失。
因此,我们采用用户点击数据来挖掘较难的三元组样本,如下图所示。
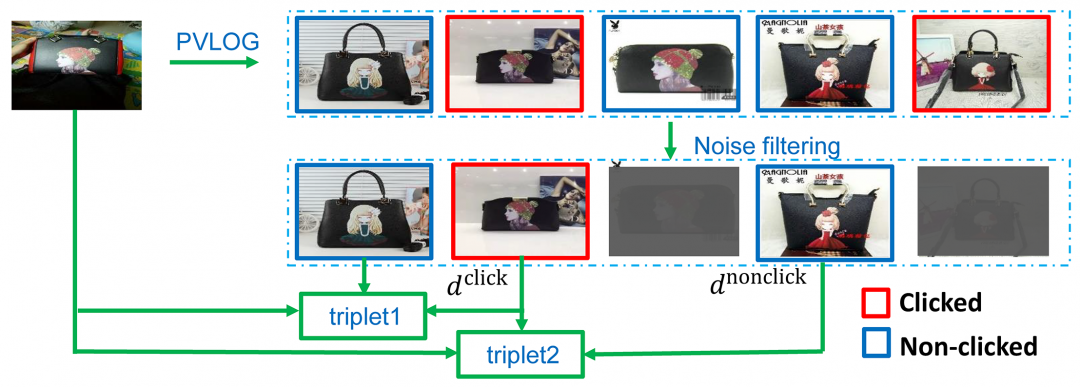
(图3 使用用户点击数据来挖掘三元组样本示意图)
在图像检索场景下,很大一部分用户会在返回列表中点击同款的商品图像,这意味着点击的图像
然而,未点击的图像仍然可能是与查询图像具有同款宝贝的图像,因为当许多同款的宝贝图像被返回时,用户只会点击结果中的一个或两个。所以要过滤未点击且与查询图像具有同款宝贝的图像,查询图像
其中,
同样,为了得到更精确的正样本,我们采用了类似的方法来过滤正样本图像。
为了扩展小批量中的所有可用三元组数据来增加更多训练数据,我们在小批量中获取的三元组之间共享所有负样本图像。
通过共享负样本,可以在进入损失层之前生成
其中,改进的损失函数是针对同一查询图像的所有三元组样本计算平均损失,这样可以最大程度地减少噪声三元组的影响。
通过查询图像层面的三元组损失函数,学习CNN 特征,从而将用户的实拍图像和商家的高质量图像映射到同一特征空间,使得不同来源的图像能够更可靠地匹配。
2.Deep ranking框架
如何处理图像中的背景噪声并检测出主体对象?
参考书中第4章关于检测的介绍,一种直接的方法是部署现成的主体检测算法,如Faster R-CNN或SSD。
然而,这种方法时延较长而且需要大量边界框的标注。
这里,我们提出两个分支的联合网络模型来同时学习检测和特征表示,下图所示是分支网络模型结构。
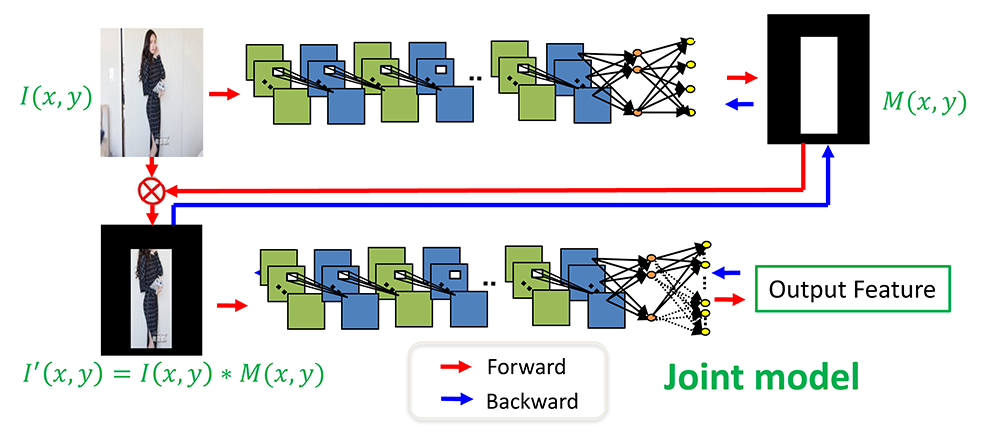
(图4 两个分支的深度联合网络模型,用于主体检测和特征学习。上面是主体检测分支,下面是特征学习分支)
如何学习这个联合模型的参数呢?
我们以之前挖掘的
在不需要边界框标注的情况下,主体掩膜通过分支结构以类似注意力的机制被学习出来(参考第3章中的细粒度识别内容)。
总体来说,Deep ranking框架如下图所示。
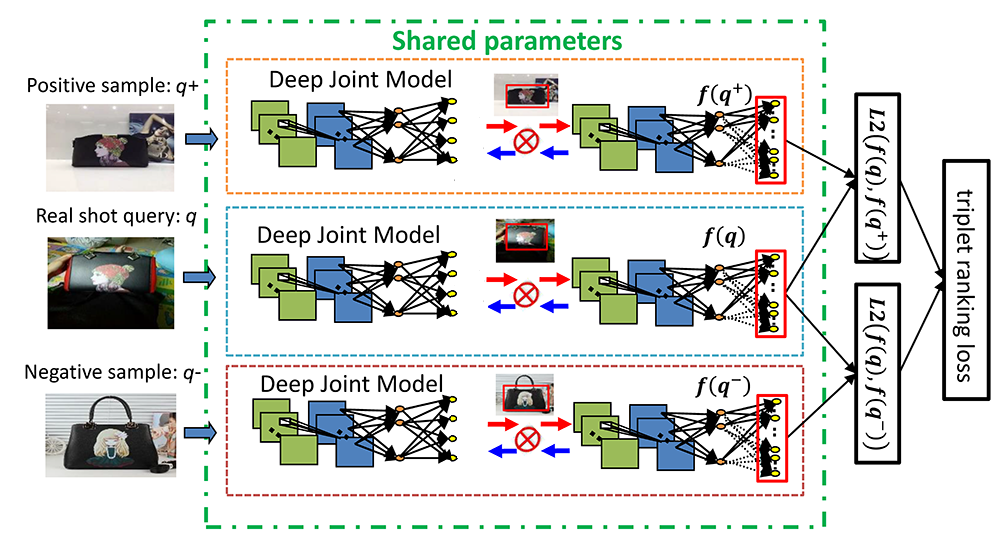
(图5 Deep ranking框架为以
具体做法是,Deep ranking框架下的每个深度联合模型(图4)都共享参数,检测的掩膜函数
主体边界框区域是输入图像
需要注意的是,这里只需要弱监督的用户点击数据,不需要依赖边界框的标注进行训练,这大大降低了人力资源成本,提高了训练效率。
1.10亿级的大规模图像检索引擎
为提高响应速度,我们使用大规模二值引擎进行查询和排序。一个实时稳定的搜索引擎是非常重要的,因为每天都有数以千万计的用户在使用拍立淘的视觉搜索服务。因此,我们采用Multi-shards和Multi-replications引擎架构,如下图所示,它不仅可以快速响应大量用户查询,而且具有很好的可扩展性。
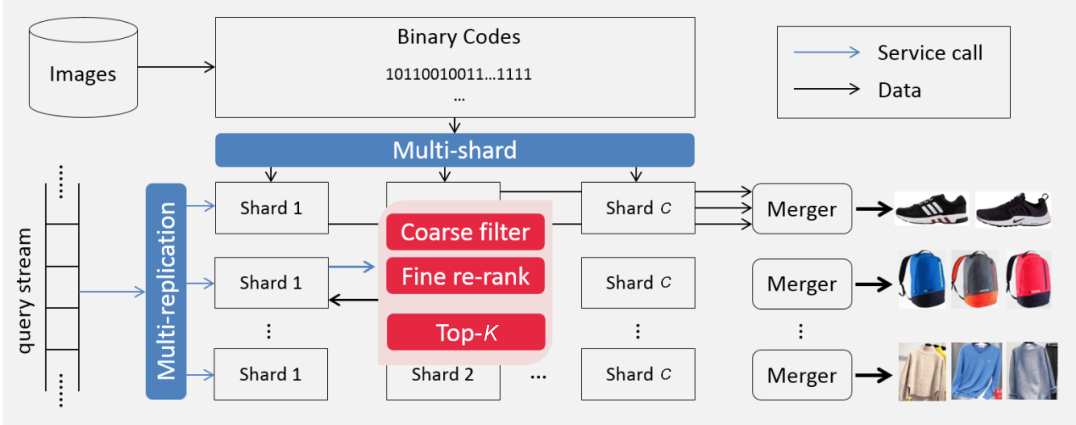
(图6 Multi-shards和Multi-replications引擎架构)
Multi-shards:单机内存无法存储这么多的特征数据,因此特征被存储到多个节点上。对于单次查询,将从每个节点检索出的Top-K结果合并起来,得到最终的结果。
Multi-replications:单个特征数据库无法应对大量的查询流量,特征数据库被复制多份,从而将查询流量分流至不同的服务器集群上,以降低用户的平均查询时间。
在每个节点,使用两种类型的索引:粗筛选和精排序。
粗筛选采用的是一种改进的基于二值特征(CNN 特征二值化)的二值倒排索引(二值引擎的内容可以参考第7章)。以图像ID为关键字、二值特征为值,通过汉明距离计算,可以快速滤除大量不匹配数据。然后,根据返回的图像数据的二进制编码,对最近邻进行精排序。
精排序用于更精确的排序,根据附加元数据(如视觉属性和特征)对粗筛选出的候选项重新排序。
这一过程相对较慢,部分原因是元数据以非二进制形式存储,另一个原因是元数据的存储开销太大,无法将其全部载入内存中,所以缓存命中率是影响性能的关键因素。
通过粗筛选和精排序,可以达到无损精度的召回结果,并大幅提升检索效率。
2.质量感知的结果重排序
对于返回的商品列表,研究发现,即使是精准的同款结果,也不能保证它们是最能激发用户点击和购买的商品,所以最后会根据商品列表里每个商品的价格、好评度、用户画像等其他信息重排序。
考虑到最初的结果是通过表观相似度获得的同款结果,我们会进一步利用语义信息对Top-60的结果进行重新排序,包括使用销量、转化率、点击率、用户画像等。
我们利用GBDT+LR对不同维度的相关描述特征进行集成,将最终得分归一化到[0,1],这既保证了表观相似度,也保证了各维度的语义重要性。
重排序依据质量信息在保持整体表观相似性的同时,对相对质量差的图像进行精炼改善,获得更符合用户意图的商品图像。
▼
至此,拍立淘的整个图像搜索架构的大概设计就基本介绍完了,如果你想了解更多细节,可阅读《深度学习图像搜索与识别(全彩)》一书。
参考文献:
[1] Shaoqing Ren, Kaiming He, Ross B Girshick,et al. Faster R-CNN: Towards Real-Time Object Detection with Region ProposalNetworks. IEEE Transactions on Pattern Analysis and MachineIntelligence(T-PAMI), 2017:1137–1149.
[2] Wei Liu, Dragomir Anguelov, Dumitru Erhan,et al. SSD: Single Shot MultiBox Detector. In European Conference on ComputerVision (ECCV), 2016:21–37.
[3] YanhaoZhang, Pan Pan, Yun Zheng,et al. Visual Search at Alibaba. In Proceedings of the 24th InternationalConference on Knowledge Discovery and Data Mining (SIGKDD), 2018:993-1001
[4] Yushi Jing, David C Liu, Dmitry Kislyuk,et al. Visual Search at Pinterest. In Proceedings of the 21th InternationalConference on Knowledge Discovery and Data Mining (SIGKDD), 2015:1889–1898
[5] Christian Szegedy, Wei Liu, Yangqing Jia,et al. Going deeper with convolutions. In IEEE Conference on Computer Visionand Pattern Recognition(CVPR), 2015:1–9.
[6] Jiang Wang, Yang Song, Thomas Leung, etal. Learning Fine-Grained Image Similarity with Deep Ranking. In IEEEConference on Computer Vision and Pattern Recognition(CVPR), 2014:1386–1393.
[7] OlgaRussakovsky, Jia Deng, Hao Su, et al. ImageNet Large Scale VisualRecognition Challenge. (2014). arXiv:arXiv:1409.0575, 2014.


▊《深度学习图像搜索与识别(全彩)》
潘攀 著
首度剖析基于深度学习的亿级图像检索技术平台
深度分析计算机视觉重要算法原理与应用场景
阐述构建大规划图像搜索平台思路、技巧与落地经验
图像搜索和识别是计算机视觉领域一个非常重要且基础的题目。本书对构成图像搜索和识别系统的各个算法基础模块一一做了介绍,并在最后一章以拍立淘为例说明了各个模块是怎样一起工作的。针对每个算法模块,本书不仅深入浅出地解释了算法的工作原理,还对算法背后的演进机理和不同方法的特点进行了说明,在第2章至第8章最后均提供了经典算法的PyTorch 代码和相关参考资料。
本书既适合图像搜索和识别领域的初学者,也适合在某个单一任务方面有经验但是想扩充知识面的读者。
(京东限时活动,快快扫码抢购吧!)