
干货:ARM架构代码移植实战分享
经历过2个项目的业务代码从X86服务器迁移到aarch64泰山服务器上,以前没有相关经验摸索了好久,踩了很多坑,现在迁移工作也差不多收尾了,Taishan服务器上跑比X86的溜多了。写了一篇代码迁移经验总结,欢迎大家参考。
编程语言简介
按照翻译方式的不同,高级语言通常可以分为两类:一类是编译翻译,一类是解释翻译,分别对应着编译型语言和解释型语言。
1.编译型语言
典型的如C、C++语言,都属于编译型语言,源代码到执行的过程概括如图1-1所示。C/C++编译好的程序是机器指令,由操作系统加载到存储器(一般为内存)后由CPU直接执行。
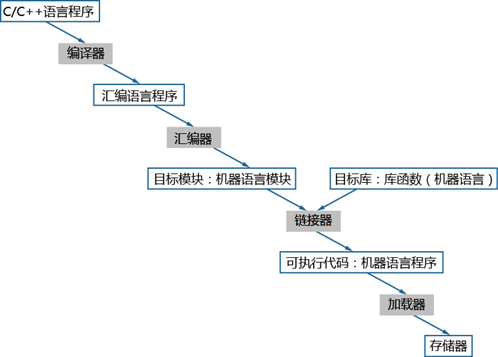
图 编译型语言执行过程
基于编译型语言开发的应用程序,例如C/C++语言应用程序,其编译后得到可执行程序,可执行程序执行时依赖的指令是CPU架构相关的。因此,基于x86架构编译的C/C++语言应用程序,无法直接在TaiShan服务器运行,需要进行移植编译,移植编译过程中遇到的问题可以参考第2、3章提供的方法解决。
2.解释型语言
典型的如Java、Python语言,都属于解释型语言,源代码到执行的过程概括如图1-2所示。Java/Python编译好的程序是平台无关的字节码,由虚拟机解释执行,虚拟机完成平台差异的屏蔽。
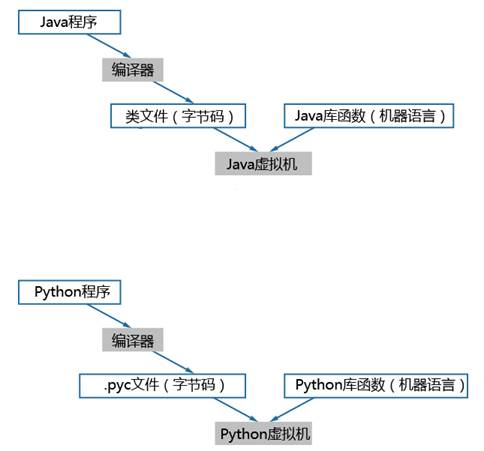
图 解释型语言执行过程
基于解释型语言开发的应用程序,是CPU架构不相关的,例如Java、Python,将这类应用程序移植到TaiShan服务器,无需修改和重新编译,按照与x86一致的方式部署和运行应用程序即可。
Java应用程序jar包内,可能包含基于C/C++语言开发的so库文件,这类so库需要移植编译,移植编译so库遇到的问题可以参考第2、3章提供的方法解决,使用编译得到的so库重新打包jar包。
准备工作
C/C++程序移植需要安装编译器,推荐使用gcc7.3及以上版本(最低不低于4.8.5),下载安装参考链接:
gcc7.3版本下载地址:
http://ftp.gnu.org/gnu/gcc/gcc-7.3.0/
安装步骤参考:https://gcc.gnu.org/install/
移植相关问题处理-编译脚本移植类问题
1.1 -m64编译选项
现象描述
告警信息:gcc:error: unrecognized command line option ‘-m64’
可能原因
-m64是x86 64位应用编译选项,m64选项设置int为32bits及long、指针为64 bits,为AMD的x86 64架构生成代码。在ARM64平台无法支持。
处理步骤
将ARM64平台对应的编译选项设置为-mabi=lp64。
1.2 char数据类型的符号
现象描述
告警信息:warning:comparison is always false due to limitedrange of data type
可能原因
char变量在不同CPU架构下默认符号不一致,在x86架构下为signed char,在ARM64平台为unsigned char,移植时需要指定char变量为signed char。
处理步骤
在编译选项中加入“-fsigned-char”选项,指定ARM64平台下的char为有符号数。
源码修改类问题
2.1 代码中汇编指令需要重写
现象描述
ARM的汇编语言与x86完全不同,需要重写,涉及使用嵌入汇编的代码,都需要针对ARM进行配套修改。
处理步骤
需要重新实现汇编代码段。
示例:
在x86架构下:

在ARM64平台下,使用gcc内置函数实现:

2.2 替换x86 CRC32汇编指令
现象描述
编译错误:unknownmnemonic `crc32q\' -- `crc32q (x3),x2\'或operand 1 should be an integer register -- `crc32b (x1),x0\'
或unrecognizedcommand line option ‘-msse4.2’。
可能原因
x86使用的是crc32b和crc32q汇编指令完成CRC32C校验值计算功能,而ARM64平台使用crc32cb、crc32ch、crc32cw、crc32cx 4个汇编指令完成CRC32C校验值计算功能。
处理步骤
请使用crc32cb、crc32ch、crc32cw、crc32cx取代x86的CRC32系列汇编指令,替换方法如表所示,并在编译时添加编译参数-mcpu=generic+crc。

示例:
在x86下的实现:
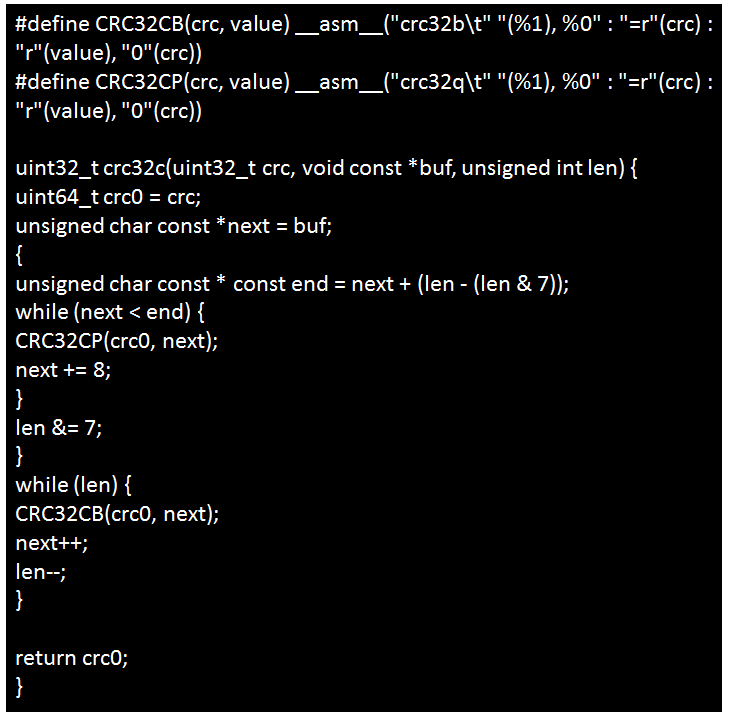
在ARM64平台下的实现:
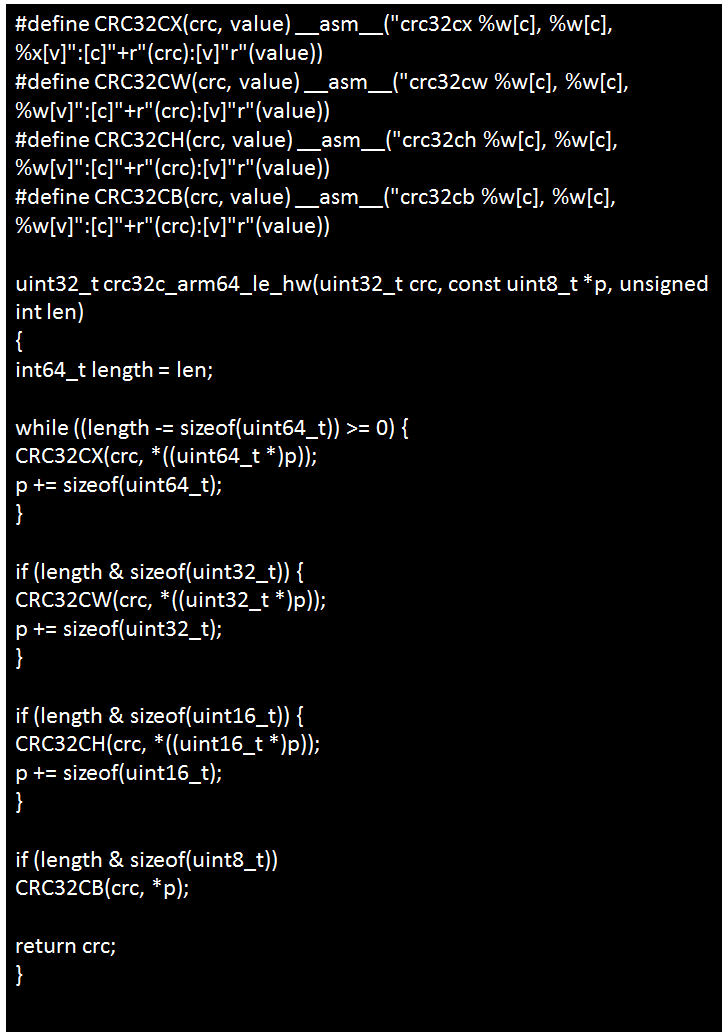
2.3 替换x86 bswap汇编指令
现象描述
编译报错:Error:unknown mnemonic `bswap\' -- `bswap x3\'。
可能原因
bswap是x86的字节序反序指令,需替换为ARM64的rev指令。
处理步骤
x86指令实现的bswap如下:

替换为ARM64指令后如下:

2.4 替换x86 rep汇编指令
现象描述
编译报错:unknownmnemonic `rep` -- `rep`。
可能原因
rep为x86的重复执行指令,需替换为ARM64的rept指令。
处理步骤
替换方法如下:
替换前:

替换后:
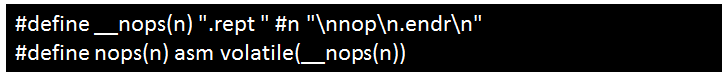
2.5 快速移植内联SSE/SSE2应用
现象描述
部分应用采用了gcc封装的用SSE/SSE2实现的函数,但是gcc目前没有提供对应的ARM64平台版本,需要实现对应函数。
处理步骤
目前已有开源代码实现了部分ARM64平台的函数,代码下载地址:https://github.com/open-estuary/sse2neon.git
使用方法如下:
步骤 1 将下载项目中的SSE2NEON.h文件拷贝到待移植项目中。
步骤 2 在源文件中删除如下代码。

步骤 3 在源代码中包含头文件SSE2NEON.h
----结束
2.6 弱内存序导致程序执行结果和预期不一致
现象描述
弱内存序导致程序执行结果和预期不一致。
可能原因
ARM64平台是弱内存序,原理如下:
1. 同一份数据,在cache里面存在多份,需要CPU之间进行同步。

2. 代码编写顺序和执行顺序可能不一样。

CPU内部是流水线执行,在执行到x=1时,如果x在内存,那么CPU就会等待x导入到cache,在等待的过程中如果y已经在cache中了,那么CPU会执行y=1,这样就导致后面的语句先执行。
对系统的影响
· 影响无锁编程的代码。
· 对于使用信号量机制写的互斥代码,因为信号量函数已经带了内存屏障的指令,所以无影响。
处理步骤
找到使用无锁编程的代码,检查是否用内存屏障指令保证了数据的一致性。
使用内存屏障指令保证对共享数据的访问和预期一致。
示例:

2.7 对结构体中的变量进行原子操作时程序异常coredump
现象描述
程序调用原子操作函数对结构体中的变量进行原子操作,程序coredump,堆栈如下:

可能原因
ARM64平台对变量的原子操作、锁操作等用到了ldaxr、stlxr等指令,这些指令要求变量地址必须按变量长度对齐,否则执行指令会触发异常,导致程序coredump。
一般是因为代码中对结构体进行强制字节对齐,导致变量地址不在对齐位置上,对这些变量进行原子操作、锁操作等会触发问题。
处理步骤
代码中搜索“#pragmapack”关键字(该宏改变了编译器默认的对齐方式),找到使用了字节对齐的结构体,如果结构体中变量会被作为原子操作、自旋锁、互斥锁、信号量、读写锁的输入参数,则需要修改代码保证这些变量按变量长度对齐。
2.8 核数目硬编码
TaiShan服务器相对于x86服务器,CPU核数会有变化,如果模块代码针对处理器core数目硬编码,则会造成无法充分利用系统能力的情况,例如CPU核的利用率差异大或者绑核出现跨numa的情况。
处理步骤
您可以通过搜索代码中的绑核接口(sched_setaffinity)来排查绑核的实现是否存在CPU核数硬编码的情况。
如果存在,则根据TaiShan服务器实际核数进行修改,消除硬编码,可通过接口(sysconf(_SC_NPROCESSORS_CONF))来获取实际核数再进行绑核。
2.9 双精度浮点型转整型时数据溢出,与X86平台表现不一致
现象描述
C/C++双精度浮点型数转整型数据时,如果超出了整型的取值范围,TaiShan平台的表现与x86平台的表现不同。

可能原因
在两个平台下,是两套CPU架构,其中的算数逻辑单元的实现可能会有差异,操作系统、编译器的实现都会有所不同。x86(指令集)中的浮点到整型的转换指令,定义了一个indefinite integer value——“不确定数值”(64bit:0x8000000000000000),大多数情况下x86平台确实都在遵循这个原则,但是在从double向无符号整型转换时,又出现了不同的结果。鲲鹏的处理则非常清晰和简单,在上溢出或下溢出时,保留整型能表示的最大值或最小值,开发者并不会面对不确定或无法预期的结果。
处理步骤
参考如下数据转换的表格,调整代码中的实现:
double数据向long转换:

double数据向unsigned long转换:

double数据向int转换:

double数据向unsigned int转换:

编译优化项
4.1 gcc编译器优化浮点运算精度
现象描述
编译优化选项设置-O2级别及以上时,相同的浮点数乘加运算在x86平台和ARM64平台的运算结果,在小数点后16位存在差异。
可能原因
ARM64平台编译优化选项设置为-O2级别及以上,进行浮点数的乘加运算(a+=b*c),运算结果的精度只能精确到小数点后16位。在配置-O2选项时,gcc使用融合指令fmadd完成乘加运算,而不是fadd和fmul。
fmadd将浮点数的乘法和加法看成不可分的一个操作,不对中间结果进行舍入,从而导致计算结果有所差别。
对系统的影响
编译优化选项设置-O2级别及以上时,浮点乘加运算的性能有提升,但是运算的精度受到影响。
处理步骤
添加编译选项-ffp-contract=off可以关闭该优化。
4.2 增加编译选项匹配Kunpeng处理器架构,提升性能
在编译时增加编译选项指定处理器架构为armv8,使编译器按照Kunpeng处理器的架构和微架构生成可执行程序,提升性能。
处理步骤
编译选项中添加-march=armv8-a。
4.3 增加编译选项匹配Kunpeng处理器流水线,提升性能
如果使用了gcc 9.1以上的版本,在编译时增加编译选项指定使用tsv110流水线,使编译器按照Kunpeng处理器的流水线编排指令执行顺序,充分利用流水线的指令集并行,提升性能。
处理步骤
编译选项中添加 -mtune=tsv110。