
原创 | 支持向量机在金融领域的应用

作者:金一鸣 审校:陈之炎 本文约4400字,建议阅读8分钟 本文选择一个简单直观的应用实战——根据股价基本 历史数据来预测股市涨跌。

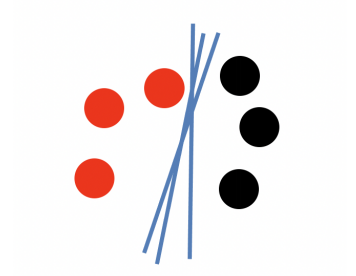
图1.1-1 二分类问题可以有无数条分割线来对其分类
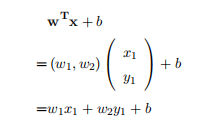
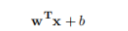 可以理解成一个分类标签,整个式子就是一个分类器了,计算过程如下:
可以理解成一个分类标签,整个式子就是一个分类器了,计算过程如下: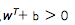 (正样本超平面),同样的黑球(负样本)可以表示成
(正样本超平面),同样的黑球(负样本)可以表示成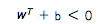 (负样本超平面)。因此该问题的决策函数他就是线性支持向量机):
(负样本超平面)。因此该问题的决策函数他就是线性支持向量机):函数边界:一个数据点到超平面的距离|w • x + b|,所以最小函数边界可以表示为:
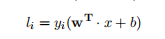 1.1. 3
1.1. 3
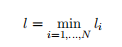 1.1. 4
1.1. 4
几何边界:在函数边界基础上抽象成空间上的概念,可表示空间中点到平面的距离。对法向量w加上规范化的限制,这样即使w和b成倍增加也不会影响超平面在空 间中的改变。所以最小几何边界可表示成:
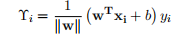 1.1. 5
1.1. 5
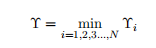 1.1. 6
1.1. 6
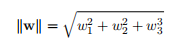
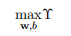
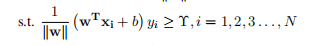 1.1. 7
1.1. 7

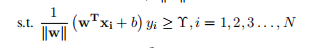 1.1. 8
1.1. 8
 的问题也就是求
的问题也就是求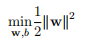 所以式子也可以写成:
所以式子也可以写成:
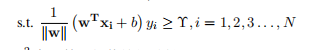 1.1. 9
1.1. 9

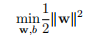
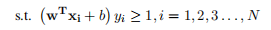 1.1. 10
1.1. 10
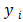 = 1 时,Xi + b>1;当 = —1 时,
= 1 时,Xi + b>1;当 = —1 时,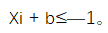
 1.1. 11
1.1. 11
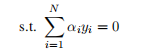
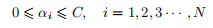


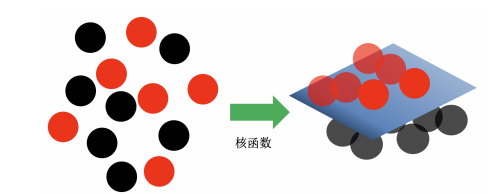
图 1.2-1: 现实中各种分类情况
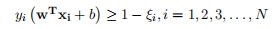 1.2.12
1.2.12
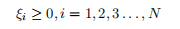
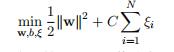 1.2.13
1.2.13
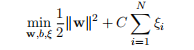
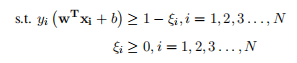 1.2.14
1.2.14
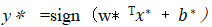
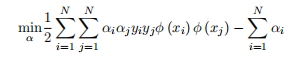
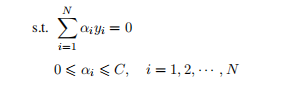 1.2.15
1.2.15
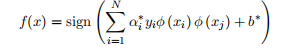 1.2.16
1.2.16
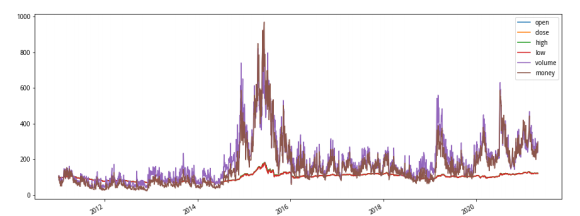
Open (当天开盘价)High (当天最高价)
Low (当天最低价)
Volume (当天成交的股票数量)
Money (当天成交的金额)
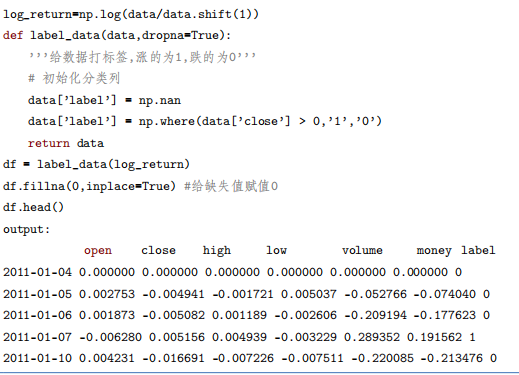
利用Pandas可以很方便查看数据集的基本结构和属性。

表2.1-1 数据格式





编辑:于腾凯
校对:林亦霖
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”加入组织~