
如何将Vision Transformer应用在移动端?
【GiantPandaCV导语】
Vision Transformer在移动端应用的探索和改进,提出了不规则Patch嵌入和自适应Patch融合模块有效提升了VIT在移动端的性能表现,在DeiT基础上提升了9个百分点。
1前言
在本次工作中,研究了移动端的Vision Transformer模型,猜想Vision Transformer Block中的MSA(多头注意力)和FFN(前馈层)更适合处理High-level的信息。
我们提出的irregular patch embedding能在patch中以不同的感受野,提取丰富的信息。
最终这些处理过的patch经过adaptive patch merging模块得到最终分类结果。经过这些改进,我们在DeiT的baseline基础上,能够提升9%的精度,并且也超越了其他Vision Transformer模型。
2简介
在现有的Vision Transformer模型上,我们发现降低模型的FLOPS,其性能会严重下降。
以DeiT为例,从DeiT-Base到DeiT-Small,FLOPS降为原来的1/4,性能损失了2%
而从DeiT-Small到DeiT-Tiny,FLOPS也是降为原来的1/4,但是性能损失了7%,其他的vit架构也是类似。
所以我们猜测这些架构都是朝着有较强的特征提取能力和避免过拟合能力的大模型进行优化,从而导致信息提取效率较低。
ViT具有两个重要的模块:
MSA多头注意力,用于各个独立Patch之间的交互,能够整合high-level信息,但是不能提取patch内的low-level信息 FFN,有多个全连接层组成,对于提取low-level图像特征并不高效
也有一些ViT架构尝试将CNN的金字塔式架构引入(如swin,pvt),但在该工作里,我们展示了瓶颈可能并不在MSA和FFN这里。
本文通过改进Patch Embedding和Patch Merging,得到了不小的提升。
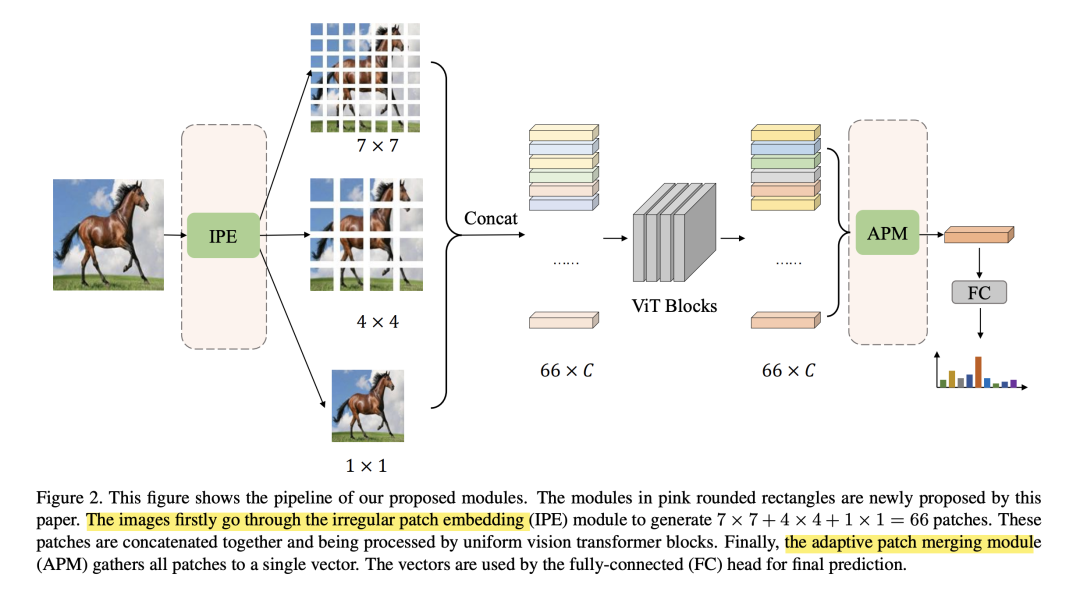
3Irregular Patch Embedding
分三步来介绍Irregular Patch Embedding的设计
使用卷积来做Patch Embedding,现有的论文都已经证明了卷积擅于提取low-level局部特征,为了进一步压缩计算量,我们使用了depthwise+pointwise的组合。 发现原始的14x14的patch对于移动端vit是难以处理的。一方面,如果我们想减少patch的通道数和Block的数目,那剩下的模块是无法处理如此多的patch。另一方面,我们可以通过减少patch数目,提高通道数,来得到一个平衡。 DeiT把图片切为14x14patch,每个patch都有同样的感受野。而对于不同的图片,可能需要high-level信息(比如区分狗和猫),也有可能需要low-level信息(比如区分悬崖和湖边)
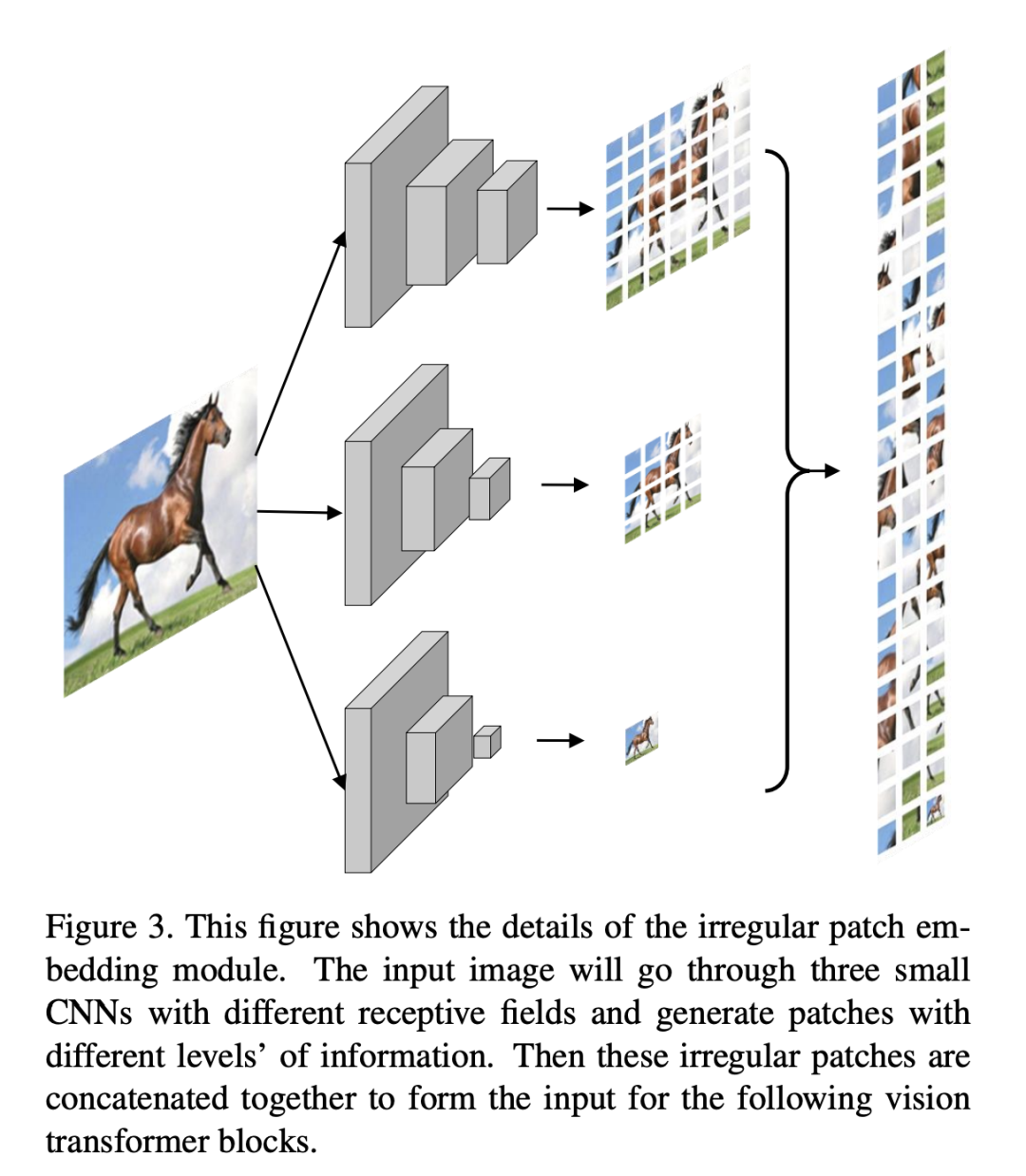
对此,设计了三个并行的分支,分别得到7x7, 4x4, 1x1个Patch,然后拼到一起
这些分支都是inverted-residual-block+SE模块,并且使用不同大小的stride来提取特征
笔者认为如果想要证明Irregular patch embedding的有效性,那么就应该用普通的卷积层来做,而不是用这种复杂的结构。
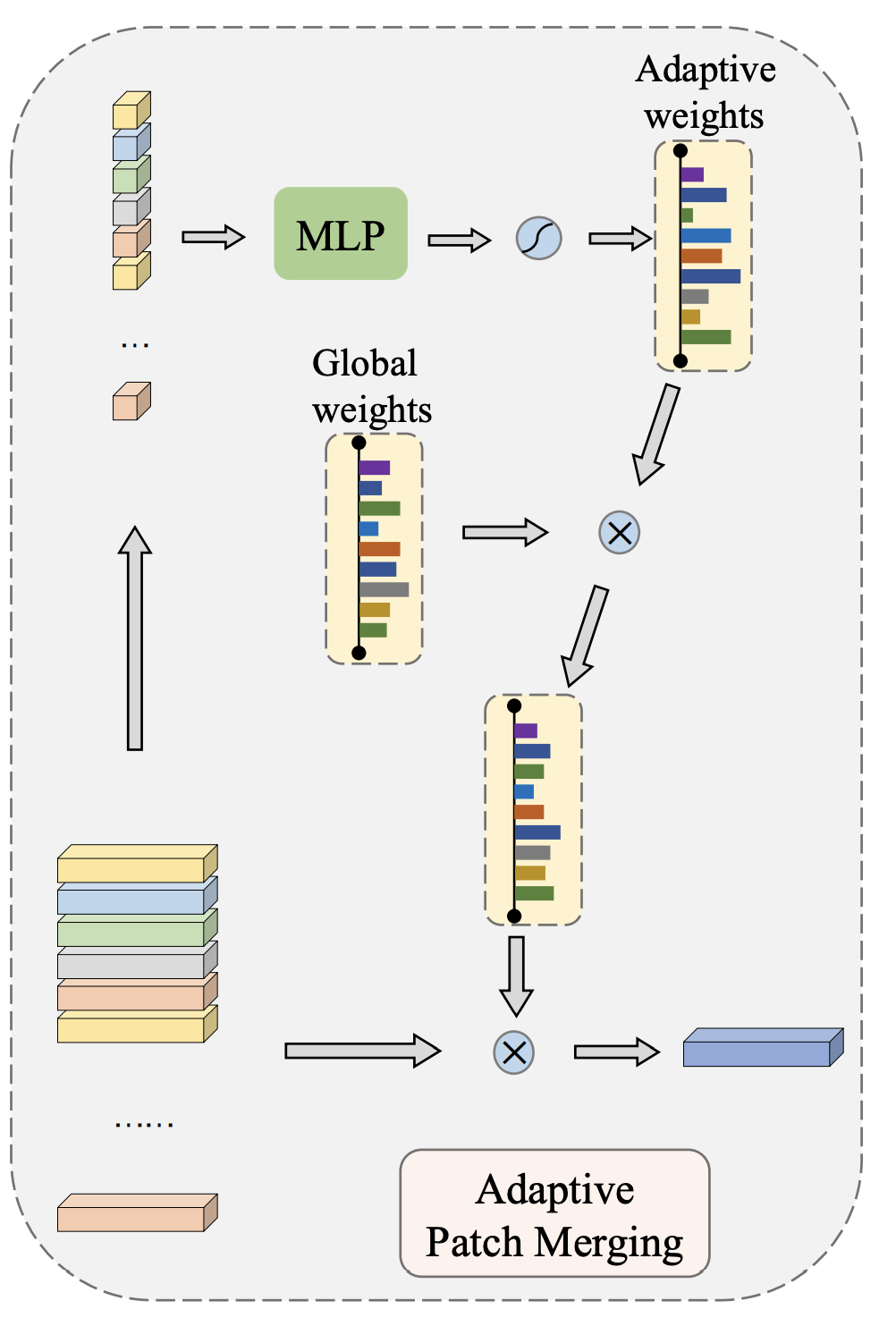
4Adaptive Patch Fusion
在DeiT里设置了额外的一个class token,这个token会跟其他token进行交互,最后分类只选用class token来得到分类结果。
当然也有一些其他架构,通过global average pooling的方式来聚合各token的信息用于分类。
实验发现class token表现并不好,猜想当Transformer block数量有限时,class token不能聚集足够的信息。
因此设计了一种自适应的融合机制:
首先给所有图像设定一个全局的权重,然后再通过一系列mlp全连接层,生成权重。最后这两个权重相乘,并输出最终结果。
5实验
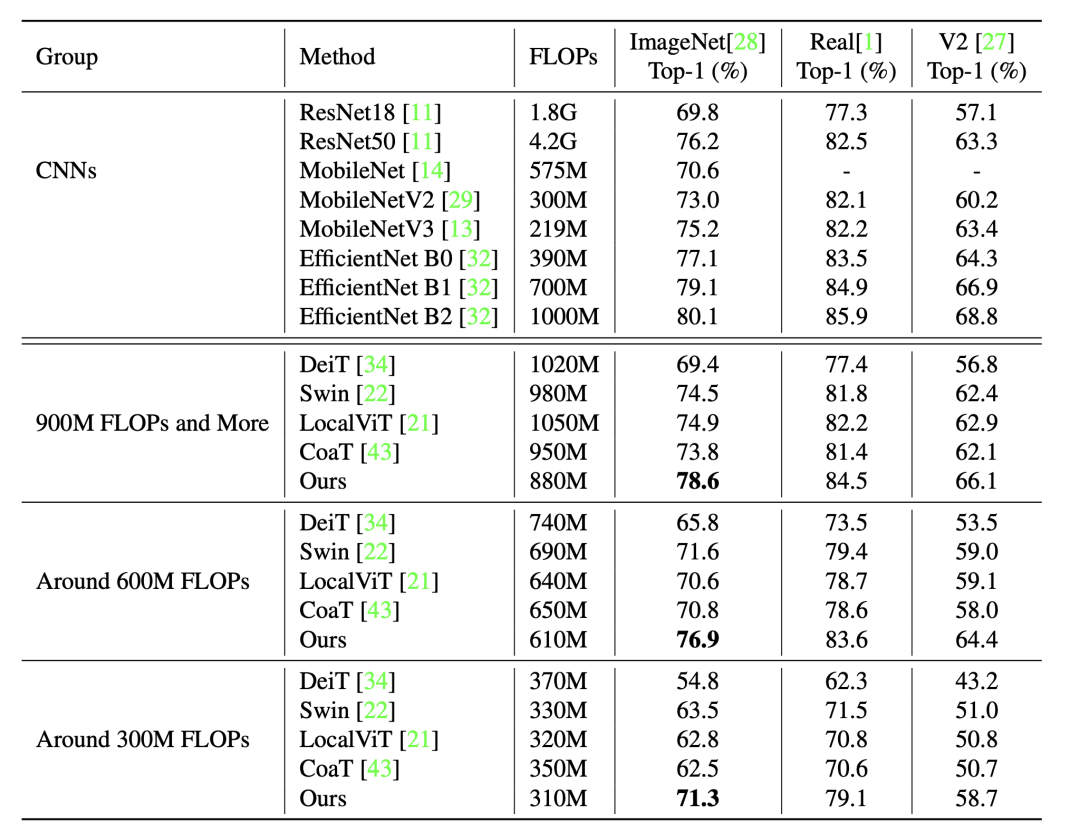


可以看到最后实验的提升也是蛮大的,关于Patch Embedding也做了相关消融实验,来证明有效性。

关于positional encoding也做了相关实验,发现结果差的并不多,作者猜想在irregular patch embedding阶段,已经编码了足够多的位置信息进去了。
END
加入GiantPandaCV交流群,探讨CV/算法/部署/论文