
计算机视觉系统中图像究竟经历了哪些“折磨”
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

如今,计算机视觉(CV)已成为人工智能的主要应用之一(例如,图像识别,对象跟踪,多标签分类)。在本文中,我们将了解构成计算机视觉系统的一些主要步骤。
一般的计算机视觉系统工作流程具有如下步骤:
1.图像采集并输入到系统中。
2.图像预处理和提取特征。
3.利用提取的特征,通过机器学习系统来训练模型和做出预测。
接下来我们将简要介绍图像在这三个不同步骤中的一些主要过程。
在实现CV系统时,我们需要考虑两个主要组件:图像采集硬件和图像处理软件。部署CV系统要满足的主要要求之一是测试其鲁棒性。实际上,我们的系统应该能够适应环境变化(例如照明,方向,缩放比例的变化),并能够重复执行其设计任务。为了满足这些要求,可能有必要将某种形式的约束应用于我们系统的硬件或软件(例如,远程控制照明环境)
从硬件设备获取图像后,可以使用多种方法在软件系统中以数字方式表示颜色(色彩空间)。两种最著名的色彩空间是RGB(红色,绿色,蓝色)和HSV(色调,饱和度,值)。使用HSV色彩空间的主要优点是在仅考虑HS分量时可以使系统照明保持不变。这两种颜色空间如下图所示。
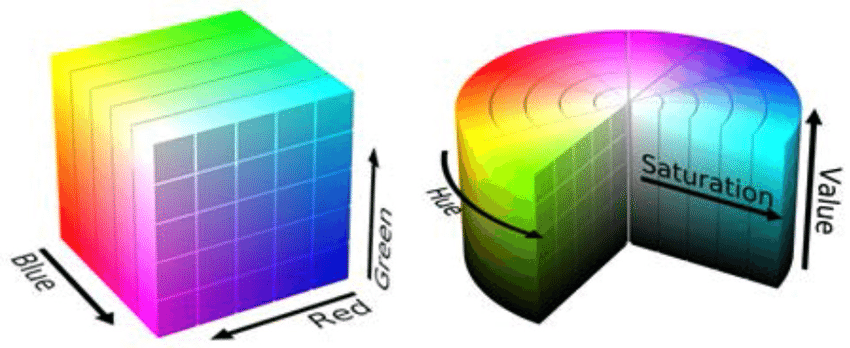
RGB与HSV颜色空间
一旦图像进入系统并使用色彩空间表示,我们便可以对图像进行不同的操作:
点运算符:点算子的一些例子是:强度归一化,直方图均衡化和阈值处理。通常使用点运算符来帮助更好地可视化人类视觉图像,但不一定为计算机视觉系统提供任何优势。
区域操作:在这种情况下,我们从原始图像中获取一组点,以便在图像的操作时重新得到一个像素点。这种类型的操作通常通过使用卷积来完成。为了获得操作后的结果,可以使用不同类型的内核与图像进行卷积。例如:直接平均,高斯平均和中值滤波器。对图像进行卷积运算可以减少图像中的噪波量并改善平滑度(尽管这也会导致图像稍微模糊)。由于我们使用一组点来在新图像中创建单个新点,因此新图像的尺寸将必然小于原始图像的尺寸。解决此问题的一种方法是应用零填充(将像素值设置为零)或通过在图像的边界使用较小的模板。使用卷积的主要限制之一是在处理尺寸较大的模板时其执行速度较慢,对此问题的一种的解决方案是改为使用傅立叶变换。卷积过程如下面的动图所示。
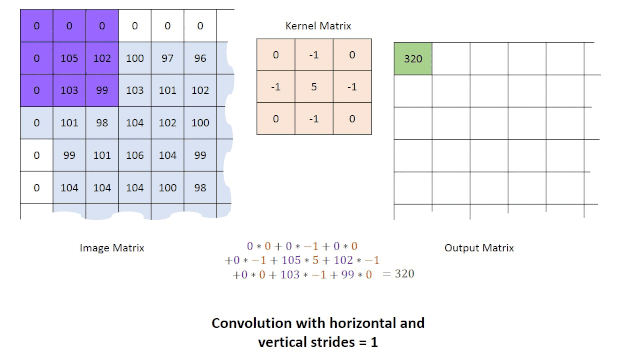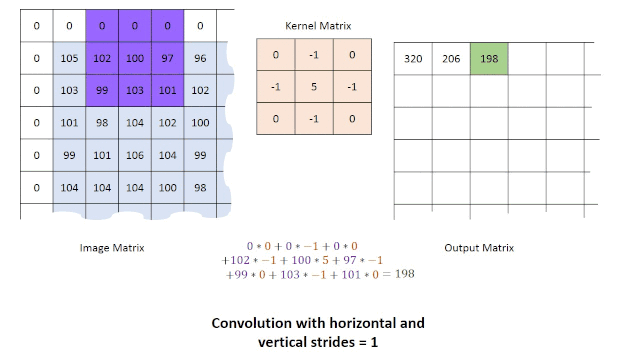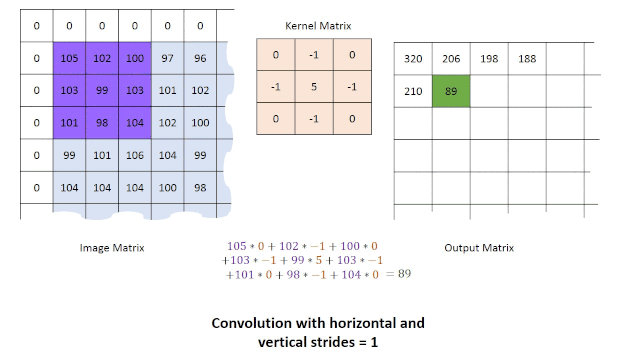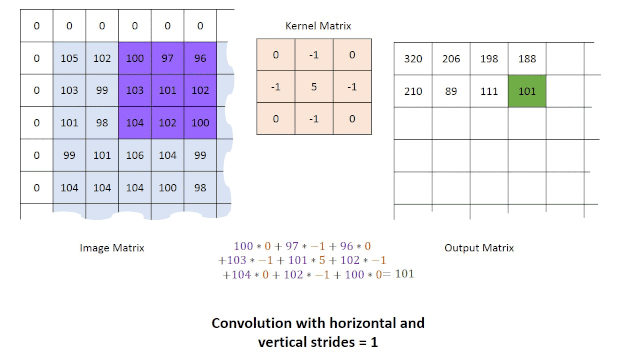
对图像进行了预处理后,我们便可以进行更多的操作,以尝试通过使用诸如一阶边缘检测(例如Prewitt算子,Sobel算子,Canny边缘检测器)等方法来提取图像中的边缘和形状,或者通过霍夫变换检测直线或者圆形。
对图像进行预处理后,可以使用特征提取器从图像中提取四种主要类型的特征形态:
全局特征:将整个图像作为一个整体进行分析,然后从特征提取器中提取单个特征向量。全局特征的一个简单例子是合并像素值的直方图。
基于网格或基于块的特征:将图像分为不同的块,并从每个不同的块中提取特征。这种类型的特征通常用于训练机器学习模型。
基于区域的特征:将图像分割为不同的区域(例如,使用阈值或K-Means聚类等技术,然后分解成不同的连通域),然后从每个区域中提取特征。可以通过使用区域和边界描述方法(例如“矩”和“链码”)来提取特征。
局部特征:在图像中检测到多个单个兴趣点,并通过分析邻近兴趣点的像素来提取特征。可以从图像中提取的感兴趣的像素点主要有两种主要类型:角点和斑点。可以使用诸如Harris、Stephens Detector和Gaussians的Laplacian之类的方法来提取它们。最后,可以使用诸如SIFT(尺度不变特征变换)之类的技术从检测到的兴趣点中提取特征。通常使用局部特征来匹配图像以构建全景图或者进行3D重建、以及从数据库中检索图像。
一旦提取了一组判别特征,我们就可以使用它们来训练机器学习模型并进行预测。
在计算机视觉中用于对图像进行分类的常用工具之一是视觉单词袋(BoVW)。为了构造视觉单词袋,我们首先需要通过从一组图像中提取所有特征(例如,使用基于网格的特征或局部特征)来创建词汇表。之后,我们可以计算提取的特征在图像中出现的次数,并根据结果构建频率直方图。使用频率直方图作为基本模板,可以通过比较图像的直方图来对图像是否属于同一类进行分类,具体如下图所示。
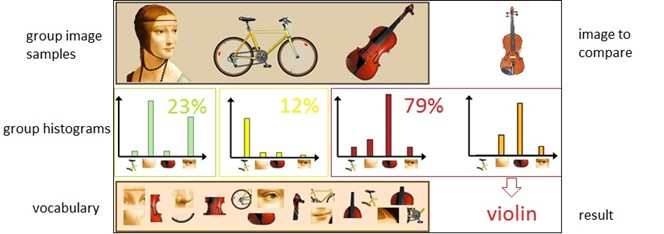
这个过程可以概括为以下几个步骤:
我们首先通过使用特征提取算法(例如SIFT和Dense SIFT)从图像数据集中提取不同的特征来构建词汇表。
其次,我们使用K-Means或DBSCAN等算法对词汇表中的所有特征进行聚类,并使用聚类质心来总结数据分布。
之后,我们可以通过计算词汇中不同特征出现在图像中的次数来从每个图像构建频率直方图。
然后,通过对要分类的每个图像重复相同的过程,然后使用任何分类算法,找出词汇表中哪个图像与我们的测试图像最相似,可以对新图像进行分类。
此外,由于人工神经网络体系结构较为成熟,例如卷积神经网络(CNN)和循环人工神经网络(RCNN),这些网络结构可以为计算机视觉提出一个替代的工作流程,取代上面的过程,直接由输入图像经过神经网络直接得到输入结果。具体形式如下图所示。
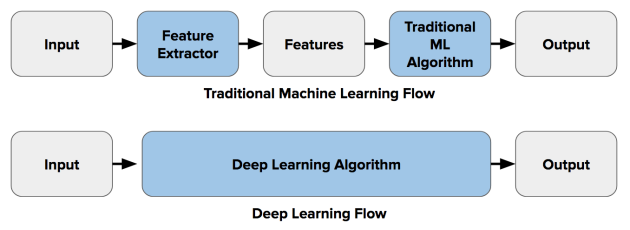
在这种情况下,深度学习算法结合了计算机视觉工作流程的特征提取和分类步骤。使用卷积神经网络时,神经网络的每一层在描述时都应用了不同的特征提取技术(例如,第1层检测边缘,第2层在图像中找到形状,第3层对图像进行分割等)。
机器学习在计算机视觉中的进一步应用包括多标签分类和对象识别等领域。在多标签分类中,我们旨在构建一个模型,该模型能够正确识别图像中有多少个对象以及它们属于哪个类。相反,在对象识别中,我们旨在通过识别图像中不同对象的位置,将这一概念进一步发展。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~