
AI模型性能上不去?这真的不怪我,ImageNet等数据集每100个标签就错3个!



主要发现
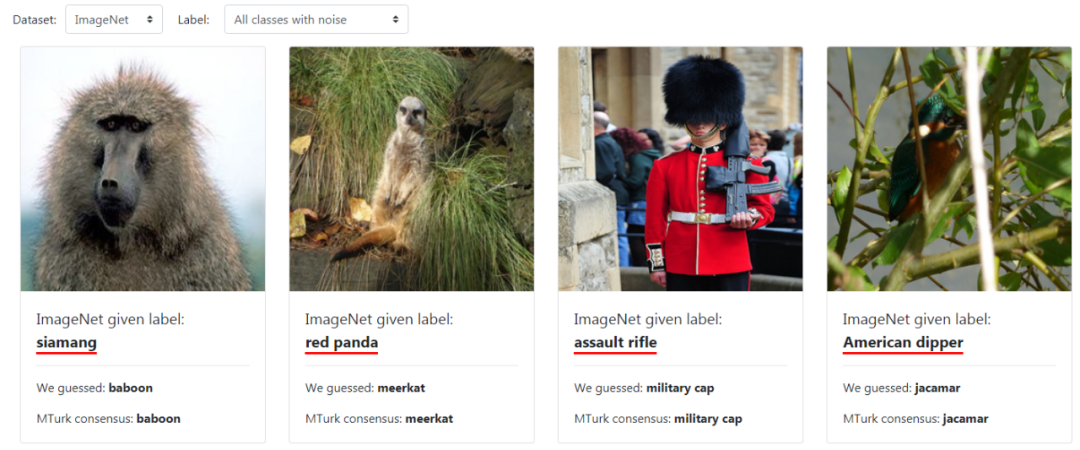
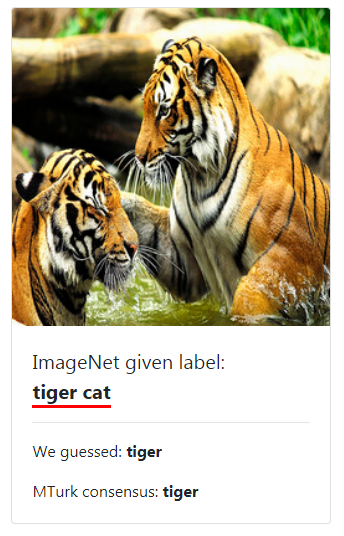
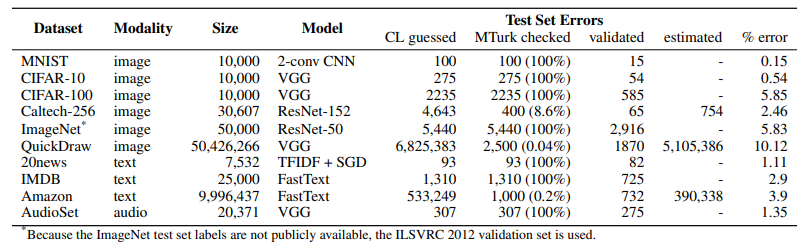
(1)ML测试集中的错误有多普遍?
(2)哪个ML数据集错误最多?
(3)高容量模型更容易过拟合错误标记数据
(4)多少噪声会破坏ImageNet和CIFAR基准测试的稳定性?
更正测试集标签 测试数据集是否受到不稳定基准的影响 考虑对带有噪声标签的数据集使用更简单/更小的模型
研究方法
置信学习
描述标签噪声 查找标签错误 学习噪声标签 发现本体论问题
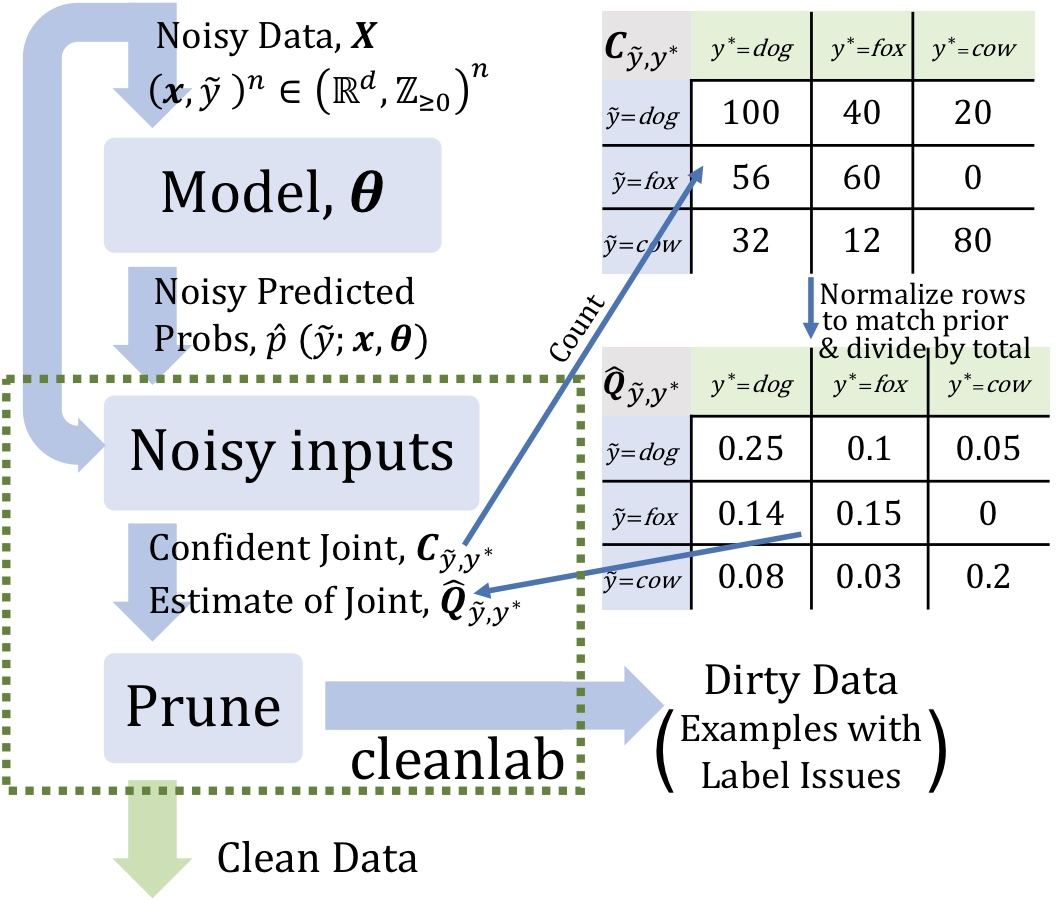
样本外预测概率(矩阵大小:类的样本数) 噪声标签(矢量长度:示例数)
估计给定噪声标签和潜在(未知)未损坏标签的联合分布,以充分描述类条件标签噪声 查找并删除带有标签问题的噪音示例 去除训练误差,通过估计潜在先验重新加权实例
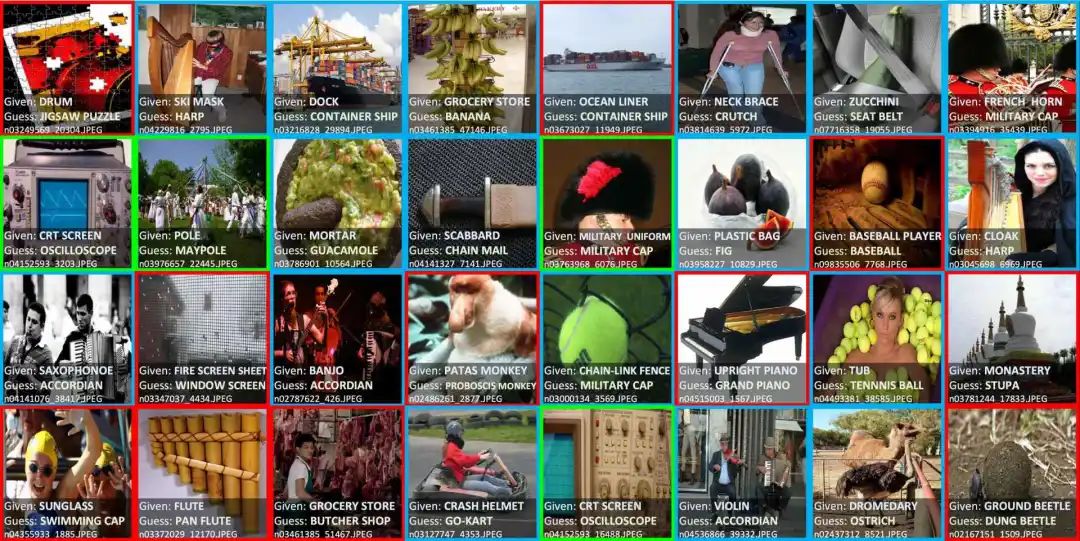
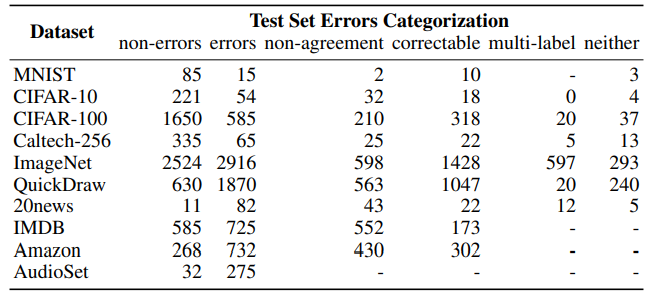
多标签图像(蓝色):图像中有两个或两个以上标签。 本体论问题(绿色):包括“是”或 “有”两种关系,在这些情况下,数据集应该包含其中一类。 标签错误(红色):存在比给定类标签更适合某一示例的类标签。
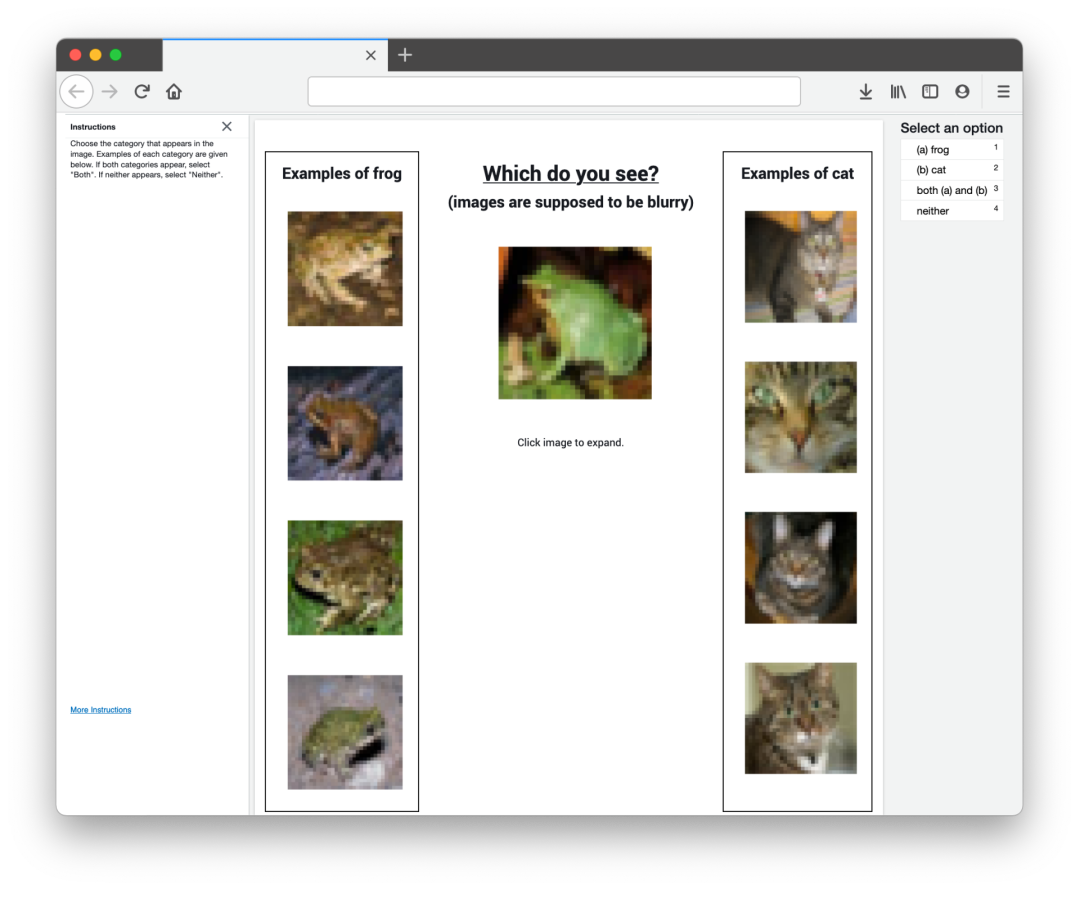
人工验证
https://www.reddit.com/r/MachineLearning/comments/mfsn18/r_pervasive_label_errors_in_test_sets_destabilize/ https://l7.curtisnorthcutt.com/label-errors https://l7.curtisnorthcutt.com/confident-learning

评论