
全链路中的数据透传
在微服务的应用场景下,服务之间可以通过各种方式与协议进行交互,同时整条链路也会变得比较长。与此同时,我们会希望一些数据在整条链路中进行透传,比如说用作对普通 api 参数的动态补充、链路压测标识或者灰度发布标识等。
关于 request headers
如果 rpc 采用一些 tcp 协议,压根不会考虑 request headers。但如果 rpc 是基于 http 协议的背景下,request headers 似乎天生是做透传数据载体的料。
在客户端,rpc 框架提供了 api 上的注解以注入自定义的 request header。在服务端 spring mvc 的 controller 里,我们也可以通过 HttpServletRequest 来获取 header。就算不在 controller 里,我们也能够通过 spring 提供的方法从任意地方获取 request 里的 header,当然由于使用了 threadLocal,所以前提是在同一线程里。
final RequestAttributes attributes = RequestContextHolder.getRequestAttributes();if (attributes instanceof ServletRequestAttributes){final HttpServletRequest request = ((ServletRequestAttributes) attributes).getRequest();final String headerVal = request.getHeader("headerKey");}
那么 request header 还有哪些不满足链路数据透传的地方呢。
如果链路中有异步线程切换的时候,我们没法再通过 RequestContextHolder 类来获取 request 了,意味着除了在 controller 层以为,拿到 request header 都是不容易的事儿,除非将 HttpServletRequest 对象在所有代码中传递。
request header 仍然是绑定在 http 上的东西,就算大部分业务在使用 http 协议进行交互,总有些应用会使用 tcp 协议的 rpc 框架,例如 thrift。除此之外,还有些许多应用间使用 mq 来解耦交互,但仍然希望数据可以透传。
大多数情况下,我们只能对 request header 进行"取"操作,而很难进行"存删改"操作,因为 HttpServletRequest 没有提供相关的方法。
数据透传
我们希望可以有一种类似 header 的载体来承载需要透传的数据,它能够跨线程进行数据传递,同时还能兼容不同的通信方式,支持自由存取,最后它需要对开发者透明。
兼容不同通信方式意味着我们得抽象出一层数据上下文 Context 的概念,而在实现上去兼容各个实际的通信方式。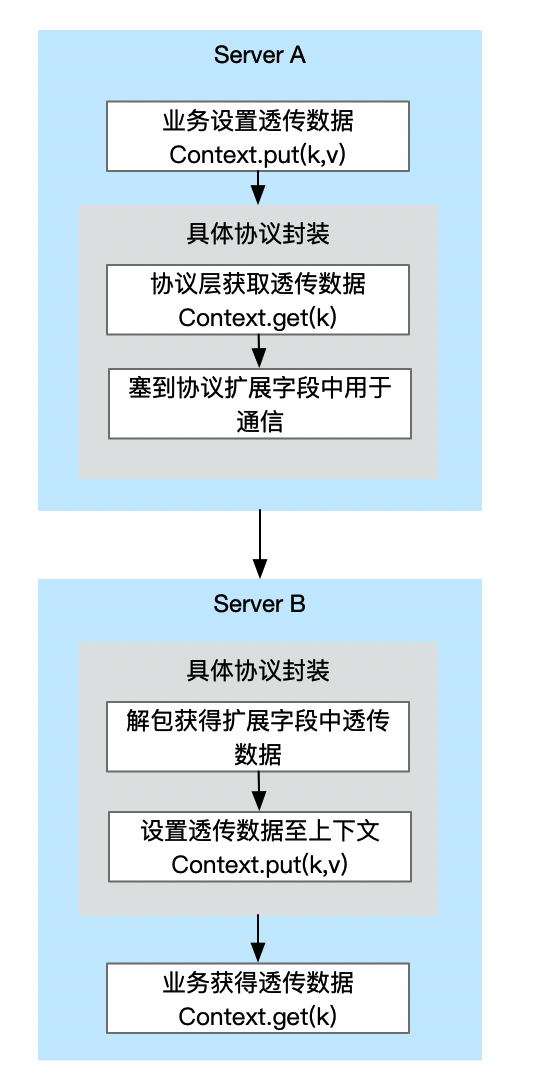
我们看到这里主要包括两层,即透传数据上下文与数据透传协议实现层。前者是一层抽象的概念,依附于一个贯穿整条链路的对象。而后者是依据各个通信方式协议的不同而具体实现的。
这里业务方 A 使用透传数据上下文设置透传数据后,在协议中需要先使用上下文获得透传数据,然后各个协议自己实现透传数据随通信传递,在通信对端获得透传数据后重新设置回透传上下文中,
这样业务方 B 就可以使用上下文获取到业务方 A 设置的透传数据并进行使用了。
数据上下文
我们知道数据上下文本身得是一个贯穿整条链路的对象,自然不依赖于具体的通信方式以及通信协议。
很多时候我们会直接把 Context 放到 Rpc 框架上去,随着 Rpc 通信而传递。但放在 Rpc 框架上,首先就违背了通信协议无关了,至少违背了通信框架无关。
实际上比较符合条件的还是调用链框架,本身调用链框架针对各种通信方式就适配了许多插件,包括 Thrift、Kafka 等,同时针对异步线程切换的情况也已经有一套适配方式。
所以我们选择的载体就是调用链框架了,把 Context 类放到调用链的核心包中,然后设置了几个简单的方法:
Context.put(k,v,option) //一个简单的存储或者替换操作,option是为了控制是否往下游透传Context.get(k) //一个简单的获取操作Context.del(k) //一个简单的删除操作
实际上调用这些方法的地方在调用链为各个协议封装的的插件中,因为要涉及到各个协议的装包与解包。
数据透传实现层
各个协议层需也只需要干两件通用的事情,1 是将透传数据从上下文中取出设置到协议中,2 是将透传数据从协议中取出设置回上下文中,实现方式依协议而定。
比如我们目前使用最广泛的 Rpc 框架仍然是基于 Http 协议的,那么意味着在客户端我们需要将透传数据从上下文取出设置到 request headers 中,而在服务端则是从 request headers 中取出所有头(可能做一些过滤)然后设置回数据上下文中。
再比如到 Thrift 框架中,数据上下文中的透传数据就是依附于 thrift 协议 header 进行传递的。
同样的,kafka 之类的 mq 也是做类似的工作。
异步数据上下文
我们之前说,整条链路中可能会存在很多线程切换的场景,手动起的线程池、servlet 3.0 的异步、spring5 的响应式、有些应用甚至使用的 akka 等。但不管怎样,在 java 中要处理异步线程的数据传递的话无非 2 中方式:
基于对象传递
以 trace 信息为例,我们在主线程将 trace 信息封装到一个对象里,然后再起子线程的时候显式将对象传递进去,那么我们在子线程里就能拿到主线程的 trace 信息了。当然为了对使用者透明,我们往往采取装饰类的方式,比如对 taskDecorator、callable、runnable、supplier 等类进行装饰,然后再装饰类里预设异步上下文。所以基于装饰类对象的异步数据上下文传递如下所示: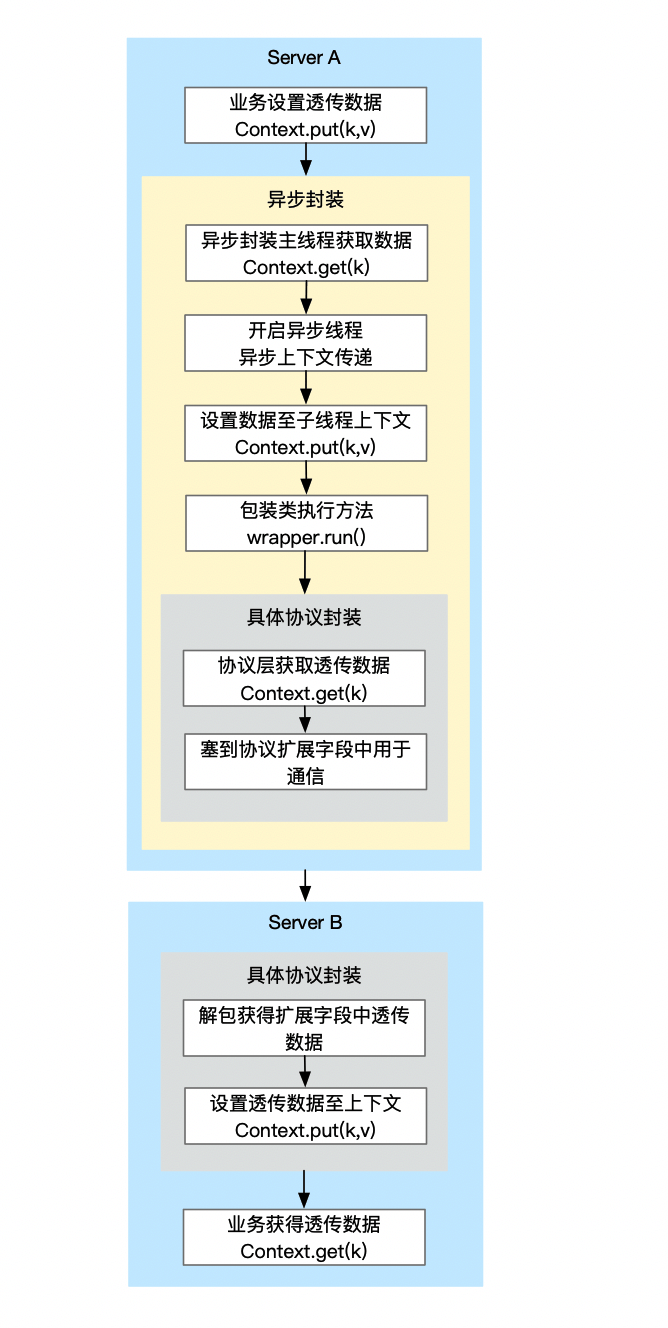
还有一种方法就是基于 jdk 提供的 InheritableThreadLocal 衍生出的父子线程传递了,包括支持线程池池化复用场景的 Transmittable ThreadLocal。
数据透传的使用场景
链路的数据透传看起来好像使用场景比较单一,除了给业务方传递一些业务场景上的数据外,其实数据透传在纯技术层面也有比较多的应用,这里简单介绍 2 个场景。
第一个就是在全链路压测的场景下,我们的压测请求与正常请求需要有一定的区分,从而让整个压测请求的流转过程都不至于影响线上环境与数据,包括存储层面我们也会让压测请求落入"影子库"中而不会产生脏数据。区分的方法往往是对请求进行"打标",然后让标识通过数据上下文在整条链路中进行透传。不管链路中是否有线程切换,包括多少种通信方式。
其次就是对整条链路的流量灰发,灰发是一种比较稳妥的部署上线方式,比方说一种灰发规则是可以针对某些特定用户展示最新版本的应用,那么这时我们往往是根据请求中的类似"user-id"字段来区分用户的。那么这些字段数据也需要在整条链路中进行透传,才能够满足全链路灰发的需求。

腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)
面试:史上最全多线程面试题 !
最新阿里内推Java后端面试题
JVM难学?那是因为你没认真看完这篇文章

关注作者微信公众号 —《JAVA烂猪皮》
了解更多java后端架构知识以及最新面试宝典

看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力
作者:fredalxin
地址:https://fredal.xin/all-link-context