点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达

- 前言 -
我们都知道,消息从生产端到消费端消费要经过3个步骤:
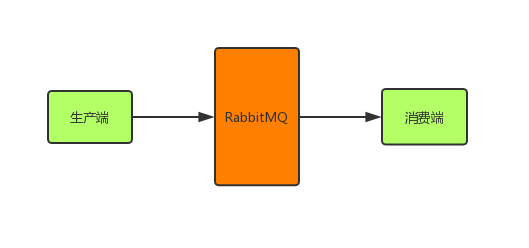 这3个步骤中的每一步都有可能导致消息丢失,消息丢失不可怕,可怕的是丢失了我们还不知道,所以要有一些措施来保证系统的可靠性。这里的可靠并不是一定就100%不丢失了,磁盘损坏,机房爆炸等等都能导致数据丢失,当然这种都是极小概率发生,能做到99.999999%消息不丢失,就是可靠的了。下面来具体分析一下问题以及解决方案。
这3个步骤中的每一步都有可能导致消息丢失,消息丢失不可怕,可怕的是丢失了我们还不知道,所以要有一些措施来保证系统的可靠性。这里的可靠并不是一定就100%不丢失了,磁盘损坏,机房爆炸等等都能导致数据丢失,当然这种都是极小概率发生,能做到99.999999%消息不丢失,就是可靠的了。下面来具体分析一下问题以及解决方案。
- 生产端可靠性投递 -
生产端可靠性投递,即生产端要确保将消息正确投递到RabbitMQ中。生产端投递的消息丢失的原因有很多,比如消息在网络传输的过程中发生网络故障消息丢失,或者消息投递到RabbitMQ时RabbitMQ挂了,那消息也可能丢失,而我们根本不知道发生了什么。针对以上情况,RabbitMQ本身提供了一些机制。
- 事务消息机制 -
事务消息机制由于会严重降低性能,所以一般不采用这种方法,我就不介绍了,而采用另一种轻量级的解决方案——confirm消息确认机制。
- Confirm 消息确认机制 -
什么是confirm消息确认机制?顾名思义,就是生产端投递的消息一旦投递到RabbitMQ后,RabbitMQ就会发送一个确认消息给生产端,让生产端知道我已经收到消息了,否则这条消息就可能已经丢失了,需要生产端重新发送消息了。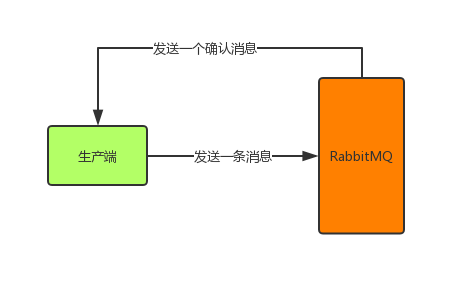
channel.confirmSelect();// 开启发送方确认模式
channel.addConfirmListener(new ConfirmListener() {
//消息正确到达broker
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("已收到消息");
//做一些其他处理
}
//RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("未确认消息,标识:" + deliveryTag);
//做一些其他处理,比如消息重发等
}
});
这样就可以让生产端感知到消息是否投递到RabbitMQ中了,当然这样还不够,稍后我会说一下极端情况。
- 消息持久化 -
那消息持久化呢?我们知道,RabbitMQ收到消息后将这个消息暂时存在了内存中,那这就会有个问题,如果RabbitMQ挂了,那重启后数据就丢失了,所以相关的数据应该持久化到硬盘中,这样就算RabbitMQ重启后也可以到硬盘中取数据恢复。那如何持久化呢?message消息到达RabbitMQ后先是到exchange交换机中,然后路由给queue队列,最后发送给消费端。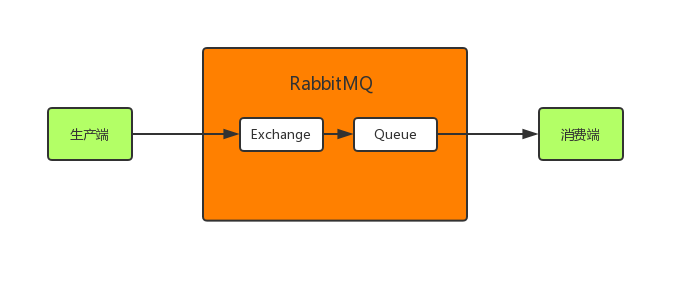 所有需要给exchange、queue和message都进行持久化:
所有需要给exchange、queue和message都进行持久化://第三个参数true表示这个exchange持久化
channel.exchangeDeclare(EXCHANGE_NAME, "direct", true);
//第二个参数true表示这个queue持久化
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
//第三个参数MessageProperties.PERSISTENT_TEXT_PLAIN表示这条消息持久化
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes(StandardCharsets.UTF_8));
这样,如果RabbitMQ收到消息后挂了,重启后会自行恢复消息。到此,RabbitMQ提供的几种机制都介绍完了,但这样还不足以保证消息可靠性投递RabbitMQ中,上面我也提到了会有极端情况,比如RabbitMQ收到消息还没来得及将消息持久化到硬盘时,RabbitMQ挂了,这样消息还是丢失了,或者RabbitMQ在发送确认消息给生产端的过程中,由于网络故障而导致生产端没有收到确认消息,这样生产端就不知道RabbitMQ到底有没有收到消息,就不好做接下来的处理。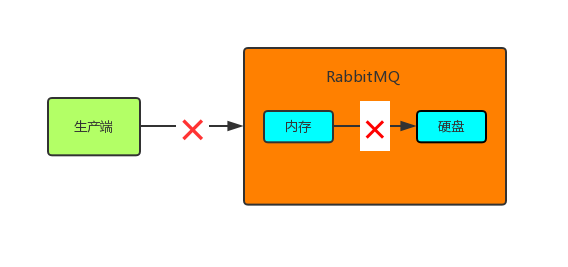 所以除了RabbitMQ提供的一些机制外,我们自己也要做一些消息补偿机制,以应对一些极端情况。接下来我就介绍其中的一种解决方案——消息入库。
所以除了RabbitMQ提供的一些机制外,我们自己也要做一些消息补偿机制,以应对一些极端情况。接下来我就介绍其中的一种解决方案——消息入库。消息入库
消息入库,顾名思义就是将要发送的消息保存到数据库中。首先发送消息前先将消息保存到数据库中,有一个状态字段status=0,表示生产端将消息发送给了RabbitMQ但还没收到确认;在生产端收到确认后将status设为1,表示RabbitMQ已收到消息。这里有可能会出现上面说的两种情况,所以生产端这边开一个定时器,定时检索消息表,将status=0并且超过固定时间后(可能消息刚发出去还没来得及确认这边定时器刚好检索到这条status=0的消息,所以给个时间)还没收到确认的消息取出重发(第二种情况下这里会造成消息重复,消费者端要做幂等性),可能重发还会失败,所以可以做一个最大重发次数,超过就做另外的处理。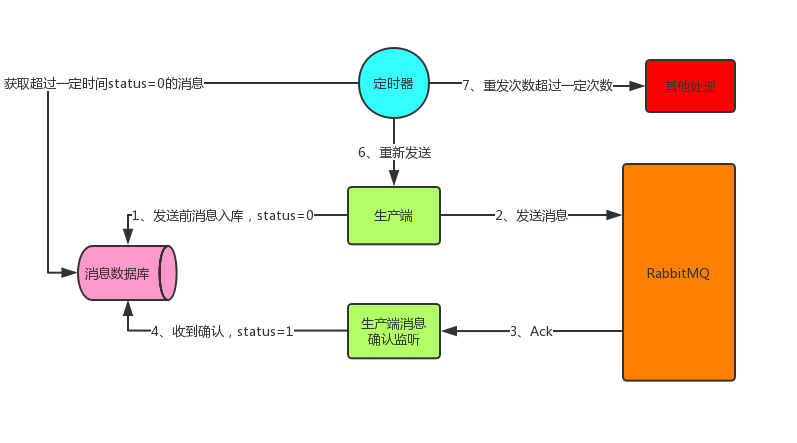 这样消息就可以可靠性投递到RabbitMQ中了,而生产端也可以感知到了。
这样消息就可以可靠性投递到RabbitMQ中了,而生产端也可以感知到了。消费端消息不丢失
既然已经可以让生产端100%可靠性投递到RabbitMQ了,那接下来就改看看消费端的了,如何让消费端不丢失消息。- 在RabbitMQ将消息发出后,消费端还没接收到消息之前,发生网络故障,消费端与RabbitMQ断开连接,此时消息会丢失;
- 在RabbitMQ将消息发出后,消费端还没接收到消息之前,消费端挂了,此时消息会丢失;
- 消费端正确接收到消息,但在处理消息的过程中发生异常或宕机了,消息也会丢失。
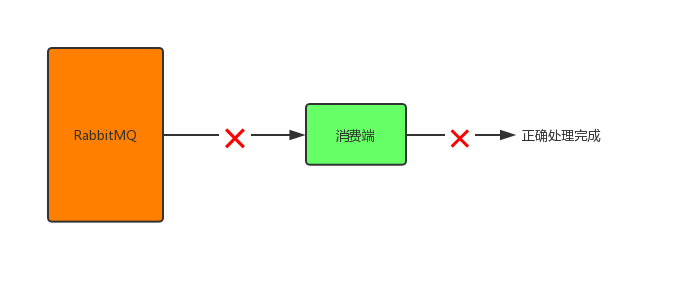 其实,上述3中情况导致消息丢失归根结底是因为RabbitMQ的自动ack机制,即默认RabbitMQ在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完,导致消费端消息丢失时RabbitMQ自己又没有这条消息了。
其实,上述3中情况导致消息丢失归根结底是因为RabbitMQ的自动ack机制,即默认RabbitMQ在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完,导致消费端消息丢失时RabbitMQ自己又没有这条消息了。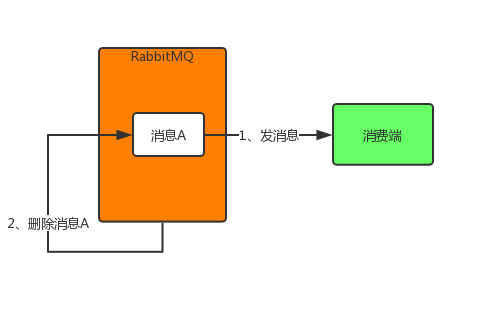
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
try {
//接收到消息,做处理
//手动确认
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} catch (Exception e) {
//出错处理,这里可以让消息重回队列重新发送或直接丢弃消息
}
};
//第二个参数autoAck设为false表示关闭自动确认机制,需手动确认
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> {});
这样,当autoAck参数置为false,对于RabbitMQ服务端而言,队列中的消息分成了两个部分:一部分是等待投递给消费端的消息;一部分是已经投递给消费端,但是还没有收到消费端确认信号的消息。如果RabbitMQ一直没有收到消费端的确认信号,并且消费此消息的消费端已经断开连接或宕机(RabbitMQ会自己感知到),则RabbitMQ会安排该消息重新进入队列(放在队列头部),等待投递给下一个消费者,当然也有能还是原来的那个消费端,当然消费端也需要确保幂等性。好了,到此从生产端到RabbitMQ再到消费端的全链路,就可以保证数据的不丢失。由于个人水平有限,有些地方可能理解错了或理解不到位的,请大家多多指出!作者:指尖凉
来源:blog.csdn.net/hsz2568952354/article/details/86559470

