
微服务之Saga事务管理

Saga是一种在微服务架构中维护数据一致性的机制,一个Saga表示需要更新多个服务中数据的一个系统操作。Saga由一连串的本地事务组成,每一个本地事务负责更新自己的数据库,这些操作满足于ACID要求。通常Saga是通过异步消息的方式来协调各个本地事务执行的。即:通过使用一部消息来协调一系列本地事务,从而维护多个服务之间的数据一致性。
Saga的一个挑战在于只满足了ACD(原子性、一致性和持久性)特性,缺少了隔离性。因此,应用程序必须通过一些对策来防止或是减少由于缺乏隔离性而导致的并发异常。
传统的本地事务实现方式简单,可以通过各种开发框架直接引入,例如spring提供的@Transactional。在分布式系统下理论上是可以通过一个单点服务把所有操作参与服务方的调用放到一个本地事务里管理,并通过查询事务API确认事务的执行情况,以及通过补充事务来回滚所作出的改变。但是这种实现方式的成本较高,而且耦合度太高不易于维护,最致命的是系统性能将成为瓶颈。
如何使用Saga来维护数据一致性Saga是通过使用补偿事务来回滚所做出的改变,与传统的ACID事务不同,传统事务在检测到范围业务规则(通常是识别异常),可以通过执行ROLLBACK语句,轻松回滚事务。而Saga无法做到自动回滚,只能通过编写配套的补偿事务进行回滚。假设一个Saga的第n+1个事务失败了,必须撤销前n个事务的影响。从概念上讲每个步骤Ti都有一个相应的补偿事务Ci,它可以撤销Ti的影响。要撤销前n个步骤的影响,Saga必须以相反的顺序执行每个Ci。
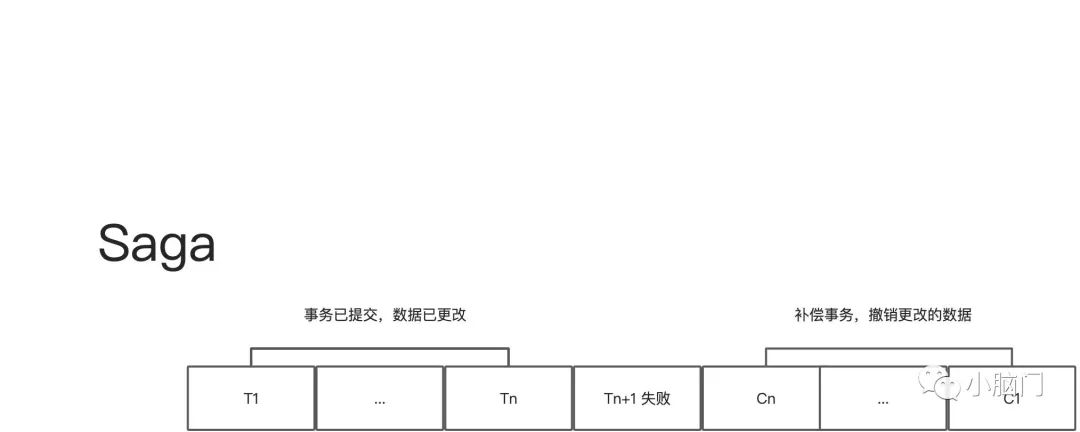
Saga的解构这里需要注意的一点就是并非所有事物都需要补偿事务,有些事务可能只是记录了一条历史,或者发送一条通知消息等。
通常一个saga包含三种类型的事务
可补偿性事务:可以使用补偿事务回滚的事务。
关键性事务:saga执行过程的关键点。如果关键性事务执行成功,则saga将一直运行到完成。关键性事务不见得是一个可补偿查询的事务,或者可重复性事务,但是它可以是最后一个可补偿事务或第一个可重复的事务。
可重复性事务:在关键事务之后的事务,它不需要回滚并保证能够完成。
Saga的两种协调方式eg:下单 → 支付 → 通知。下单时可以创建订单、锁定库存,这两个事务都属于可补偿性事务。任何一步失败都可以回滚订单状态和恢复库存。而支付事务则属于关键性事务,只要支付成功那么整个saga从理论上就已经算是成功了,即使支付失败,也不需要回滚支付事务本身。最后的通知事务,这就是一个不需要幂等的可重复性事务,即使执行失败,也可以重试。

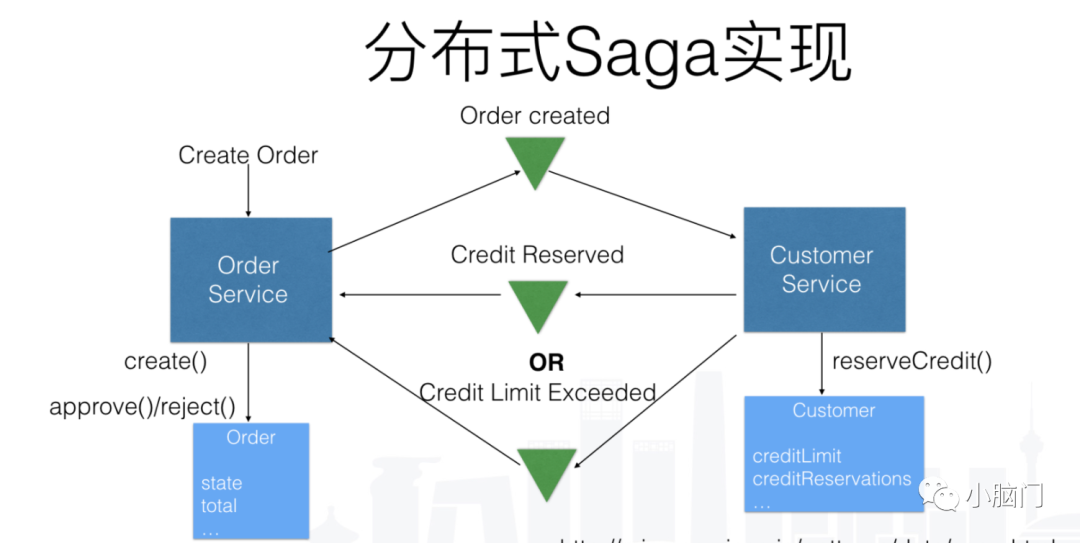
协同式(分布式实现方式)
把Saga的决策和执行顺序逻辑分布在Saga的每一个参与方中,他们通过交换事件的方式来进行沟通。使用协同式实现Saga时,没有一个中央协调器会告诉Saga参与方该做什么。相反,Saga的参与方订阅彼此的事件并作出相应的响应。在具体的实现过程中,必须保证Saga的参与方将更新其本地数据库和发布事件作为数据库事务的一部分,基于协同式Saga的每一步都会更新数据并发一个事件,且确保能够将接收到的每个事件映射到自己的数据上。
优点 | 缺点 |
松耦合:采用事件源的方式降低系统复杂程度,提升系统扩展性, 处理模块通过订阅事件的方式降低系统的耦合程度 | 更难理解:协同式saga的逻辑分布在每个服务的实现中,因此开发人员很难理解特定的saga是如何工作的。 |
实现方式简单:服务在创建、更新或删除业务对象时发布事件 | 服务之间的循环依赖:saga的参与方订阅彼此的时间,这通常会导致循环依赖关系。虽然这并不一定会有什么影响,但循环依赖被认为是一种不好的设计风格。 |
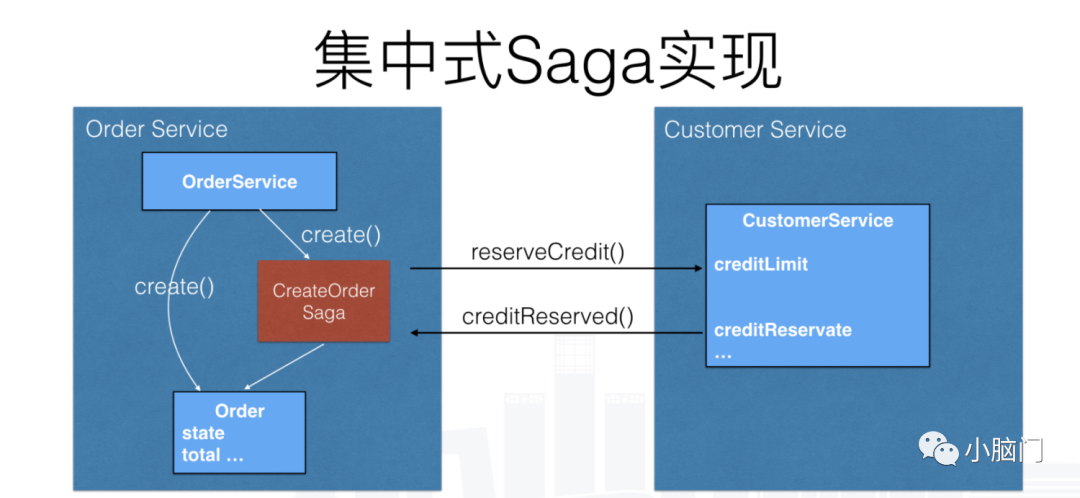
编排式(集中式实现方式)
当使用编排式saga时,开发人员定义一个编排器类,这个类的唯一职责就是告诉saga的参与方该做什么事情。相当于把所有参与方集中管理起来。编排器使用命令/异步响应方式与saga的参与方服务通信。为了完成saga中的每一个环节,编排器对某个参与方发出一个命令式的消息,告诉这个参与方该做什么操作。当参与方服务完成操作后,会给编排器发出一个答复消息。编排器处理这个消息后,并决定下一步操作是什么。
对于编排器比较形象的一种呈现方式就是,将其看做是一个状态机。状态机都是通过触发事件来维护一组状态的转换。对于saga来说,触发事件就是对每个参与方的调用,而状态的转换就是参与方对调用事件的执行结果,也就是在参与方执行完本地事务后触发状态的更改。对于状态机是有高效的测试策略的,因此,使用状态机模型可以更轻松地设计、实现和测试saga。
优点 | 缺点 |
高更简单的依赖关系:编排的一个好处就是它不会引入循环依赖关系。编排器调用参与方,但参与方不会调用编排器。 | 业务耦合程度较高:由于在编排器中存在集中过多业务逻辑实现,对于可扩展性存在一些挑战。 |
较少的耦合:参与方之间是松耦合的,每个参与方只需要向编排器提供调用的PAI就行,参与方之间不需要相互感知。 | 连续性保障:要有编排器故障的恢复策略,可以根据状态进行补偿。 |
核心协调逻辑本地化在编排器中,领域对象更加简单清晰,不需要了解参与方的具体实现。 |
ACID中的隔离属性可确保同时执行多个事务的结果与顺序执行它们的结果相同。因为saga事务没有准备阶段,事务没有隔离,如果两个saga事务同时操作同一资源就会遇到我们操作多线程临界资源的的情况。因此会产生更新丢失,脏数据读取、不可重复读等问题。
更新丢失:一个saga没有读取更新,而是直接覆盖了另一个saga所做的更改。
脏读:一个事务或一个saga读取了尚未完成的saga所做出的更新。
不可重复读:一个saga的两个不同步骤读取相同的数据却获得了不同结果,因为有另外一个saga已经进行了更新。

隔离的本质是为了控制并发,防止并发事务操作相同资源而引起的结果错乱。saga模式下解决由于缺少隔离性带来弊端的对策有:
语义锁
所谓的语义锁就是一个标记性状态。在使用语义锁时,saga的可补充性事务会在其创建或更新的任何记录中设置标志,该标志表示记录未提交且可能发生更改。该标志可以阻止其他事务访问记录的锁,也可以是指示其他事物应该谨慎地处理该记录的一个警告。这个标志会被一个可重复的事务清除,这表示saga成功完成;或通过补偿事务清除,这表示saga发生了回滚。
eg:锁定库存时,可以给商品打上一个出货中的标志,当有其他saga获取这个商品时发现是在出货中装填就不会再获取这个商品了。如果订单正常完成,可以通过一个可重复事务清除这个状态(或者理解为通过一个定时任务将状态更新为已出货);如果订单执行失败,那么可以通过锁定库存的补偿事务回滚,将状态更改为可出货。
使用语义锁的好处是他们实质上重建了ACID事务提供的隔离性,更新相同数据的saga被序列化了,这显著减少了编程工作量。另一个好处是它消除了客户端重试的负担。缺点是应用程序必须管理锁,要实现死锁检测和兜底机制。
交换式更新
一个简单的对策是将更新操作设计为可交换的。所谓可交换就是可以按任何顺序执行,则操作是可交换的。这种对策很有用,因为它可以避免更新的丢失。
悲观视图
处理缺乏隔离性的另一种方法是悲观视图。它重新排序Saga的步骤,以最大限度地降低由于脏读而导致的业务风险。
重读值
重读值对策可防止丢失更新。使用此计数器的Saga在更新之前重新读取记录,验证它是否未更改,然后更新记录。如果记录已更改,则Saga将中止并可能重新启动。此对策是乐观脱机锁模式的一种形式。
版本文件
版本文件对策之所以如此命名,是因为它记录了对数据执行的操作,以便可以对它们进行重新排序。这是将不可交换操作转换为可交换操作的一种方法。
业务风险评级
最终的对策是基于价值(业务风险)对策。这是一种基于业务风险选择并发机制的策略。使用此对策的应用程序使用每个请求的属性来决定使用Saga和分布式事务。它使用Saga执行低风险请求,可能会应用前几节中描述的对策。但它使用分布式事务来执行高风险请求(例如涉及大量资金)。此对策使应用程序能够动态地对业务风险、可用性和可伸缩性进行权衡。