
微服务架构之雪崩效应

一、概述
二、原因
三、解决方案
四、总结

在密码学中,雪崩效应(avalanche effect)指加密算法(尤其是块密码和加密散列函数)的一种理想属性。雪崩效应是指当输入发生最微小的改变(例如,反转一个二进制位)时,也会导致输出的不可区分性改变(输出中每个二进制位有50%的概率发生反转)。合格块密码中,无论密钥或明文的任何细微变化都必须引起密文的不可区分性改变。该术语最早由Horst Feistel使用,[1]尽管其概念最早可以追溯到克劳德·香农提出的扩散(diffusion)。
- 维基百科
那么,在微服务体系中,雪崩效应又指的是什么呢?
在微服务系统中,整个系统是以一系列固有功能的微服务组成,如果某一个服务,因为流量异常或者其他原因,导致响应异常,那么同样的也会影响到调用该服务的其他服务,从而引起了一系列连锁反应,最终导致整个系统崩溃。

如上图所示,服务A、B、C串行调用,如果在某一时刻,ServerC出现异常,且暂时没有恢复,那么逐渐的,ServerB和ServerA也会出现异常,从而使得整个调用链异常,不能正常提供服务。
常见的原因如下:
流量突增
节假日访问量变大,常见于工具类APP,如美图秀秀
活动原因导致访问量变大
程序bug
内存泄漏
线程池中的线程使用之后未释放等
硬件或者网络异常
机器硬盘故障
所在的网段发生异常
同步等待
因为程序设计原因,整个请求都在同步进行,后面的请求只有在前面的请求完成之后,才能被执行
缓存击穿
常见于秒杀系统或者热门事件,短时间内大量缓存失效时大量的缓存不命中,使请求直击后端,造成服务提供者超负荷运行,引起服务不可用。
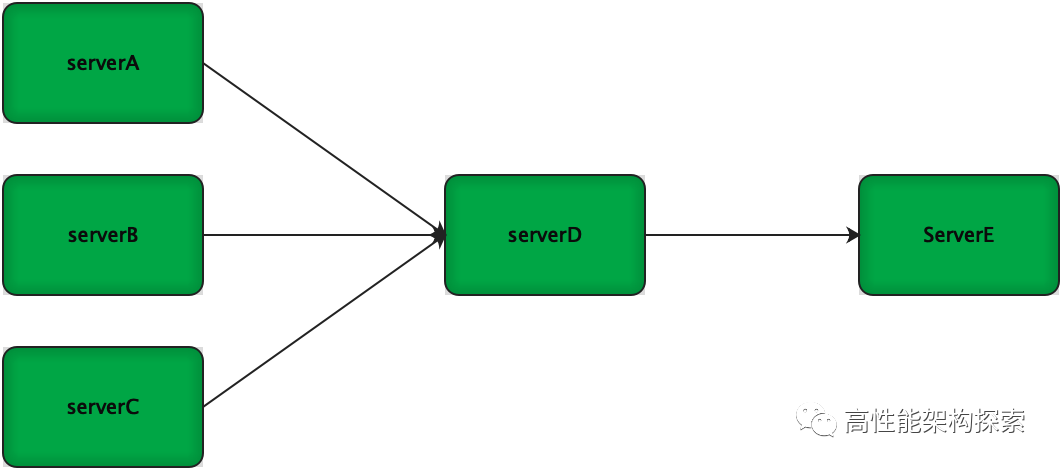
在正常情况下,整个微服务系统运行正常(以绿色表示),如下图所示:
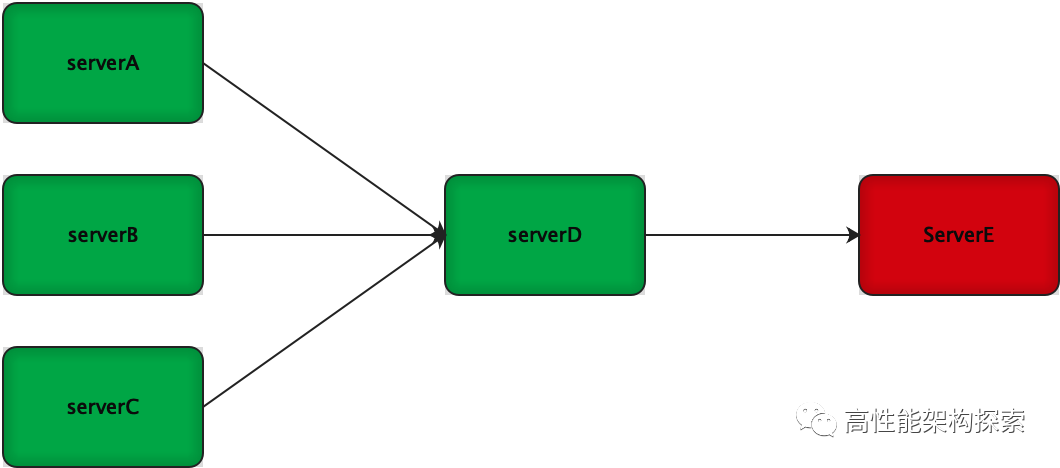
在某一时刻,serverE出现了异常,如下图所示:
因为服务E的异常,导致serverD在接收和处理请求上面也出现了异常,如下图:
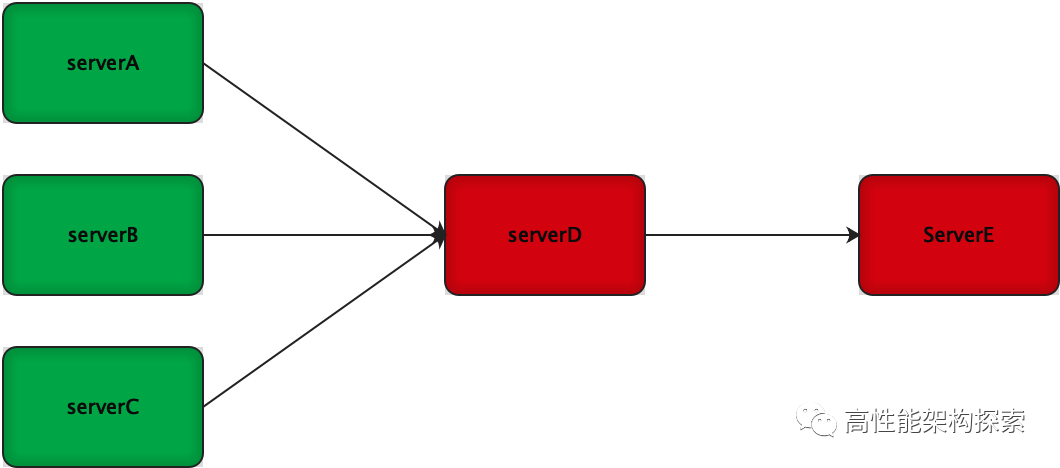
久而久之,因为serverD的异常,也影响了serverA、serverB和serverC。也就是说因为serverE的异常,间接影响了serverA、serverB、serverC和serverD,从而整个系统出现了崩溃,这就是所谓的雪崩效应。
微服务系统,是一个复杂的系统,呈网状调用结构,其每个微服务的实例成百上千,很难或者不可能去完全避免某个实例出现异常,这就使得异常在某个特定情况或者特定压力下才会出现,那么避免雪崩效应,除了要求开发人员有扎实的开发功底外,还得需要依赖其他方式来有效的进行避免或者应对雪崩效应。
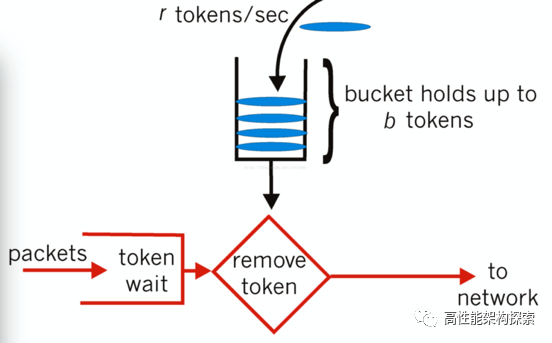
通过限制调用端的流量数来达到限流的目的。比如控制实例每秒钟的处理请求量,即控制QPS。常见的QPS控制方法有令牌桶算法,如下图所示(图片来自于网络)
在调用端即上游服务控制对下游服务的熔断功能,在上游服务中,如果发现下游服务在一定时间内,其超时率达到了某个阈值,则开启熔断机制,即不对下游服务进行调用,或者只进行一定比例的调用,而对于剩下的流量,则直接返回空响应或者返回默认响应。

分为服务内降级和服务外降级两种。
服务内降级:指的是当本服务响应比较慢的时候,主动停掉本服务内一些不重要的业务,从而释放机器资源给重要的业务。
服务外降级:当下游服务响应慢或者无响应的时候,上游服务主动调用备用逻辑,停掉对下游服务的调用。
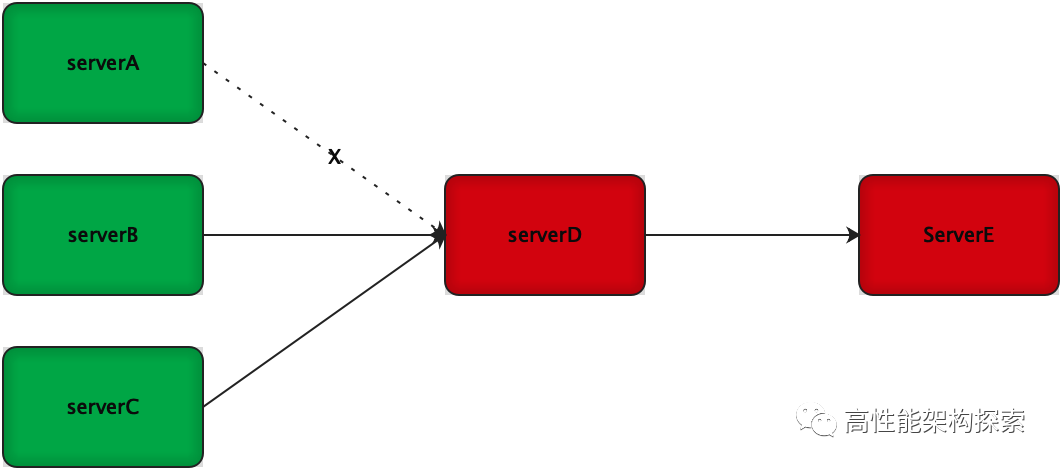
如下图所示,当serverD异常的时候,断开serverA对serverD的调用。
在流量突增的时候,微服务系统内某个实例因为机器资源或者别的原因,响应比较慢,这就是需要对该实例进行临时扩容,现在扩容方案比较成熟,比如docker方式等等,具体依赖于服务的实际部署方式,此处不再赘述。
对下游服务正常响应的数据进行缓存,之后一段时间内直接向上游返回缓存中的数据。这样可以有效降低对下游服务质量的敏感度,在一定程度上提升服务的稳定性。
评估服务的最大并发,在上线之前,先对服务进行压测,了解其性能以及QPS等,无论程序是同步还是异步,用户都可以通过 最大QPS * 非拥塞时的延时(秒)来评估最大并发,原理见little's law。
雪崩效应,在微服务系统中,是一个很常见的现象,对于其解决或者避免方式,每个开发人员的理解见仁见智,但方案无非就是以上几种,具体使用哪种,则依赖于具体的场景。
比如,笔者从业于某互联网公司的广告相关业务,在节假日的时候,流量会较平时增加,也遇到过因为流量变大导致的整个系统短时间内访问异常的情况,解决方案有以下几种:
1、提前扩容,针对可能存在性能瓶颈的服务实例,节前提前扩容,做到临时以防万一。
2、服务降级,对于广告业务线中收入占比不是很大或者耗时比较久的业务,不对其进行调用或者降低调用请求量从而使得整个系统的rt尽可能的小,以能够接受更多的请求去处理重要业务线
3、其他
