
输入URL开始建立你的前端知识体系
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
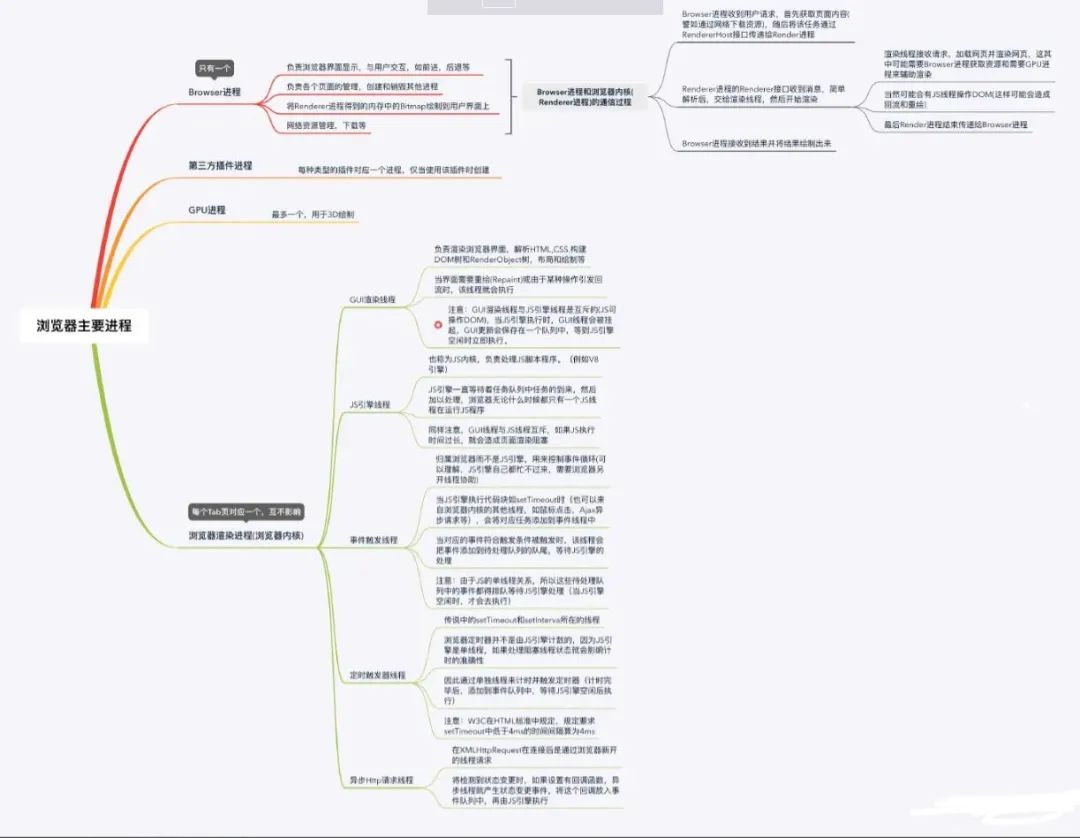
前置内容 浏览器主要进程
浏览器是多进程的,主要分为:
浏览器主进程:只有一个,主要控制页面的创建、销毁、网络资源管理、下载等。 第三方插件进程:每一种类型的插件对应一个进程,仅当使用该插件时才创建。 GPU进程:最多一个,用于3D绘制等。 浏览器渲染进程(浏览器内核):每个Tab页对应一个进程,互不影响。
第一部分 输入网址并解析
这里我们只考虑输入的是一个URL 结构字符串,如果是非 URL 结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串。
URL的组成
URL 主要由 协议、主机、端口、路径、查询参数、锚点6部分组成!

解析URL
输入URL后,浏览器会解析出协议、主机、端口、路径等信息,并构造一个HTTP请求。
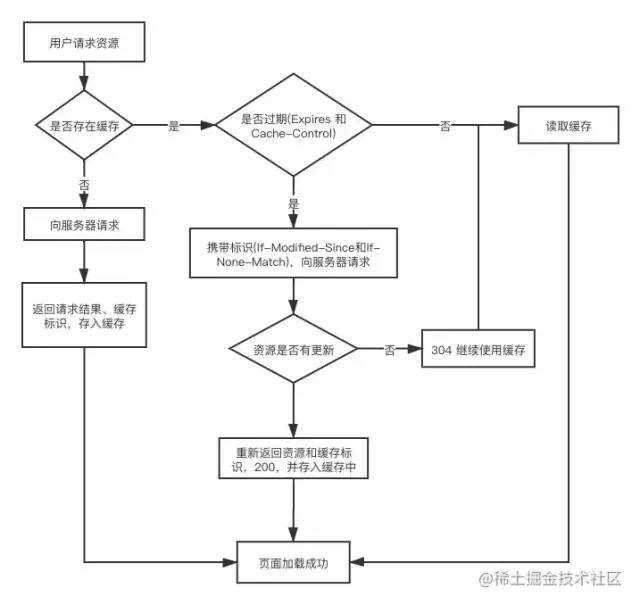
浏览器发送请求前,根据请求头的 expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,并不会发送请求。如果没有命中,则进入下一步。没有命中强缓存规则,浏览器会发送请求,根据请求头的 If-Modified-Since和If-None-Match判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,则进入下一步。如果前两步都没有命中,则直接从服务端获取资源。
HSTS
由于安全隐患,会使用 HSTS 强制客户端使用 HTTPS 访问页面。详见:你所不知道的 HSTS[1]。当你的网站均采用 HTTPS,并符合它的安全规范,就可以申请加入 HSTS 列表,之后用户不加 HTTPS 协议再去访问你的网站,浏览器都会定向到 HTTPS。无论匹配到没有,都要开始 DNS 查询工作了。
浏览器缓存
强缓存
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程。强缓存又分为两种Expires和Cache-Control
Expires
版本:HTTP/1.0 来源:存在于服务端返回的响应头中 语法:Expires: Wed, 22 Nov 2019 08:41:00 GMT 缺点:服务器的时间和浏览器的时间可能并不一致导致失效
Cache-Control
版本:HTTP/1.1 来源:响应头和请求头 语法:Cache-Control:max-age=3600 缺点:时间最终还是会失效
请求头:
| 字段名称 | 说明 |
|---|---|
| no-cache | 告知(代理)服务器不直接使用缓存,要求向原服务器发起请求 |
| no-store | 所有内容都不会被保存到缓存或Internet临时文件中 |
| max-age=delta-seconds | 告知服务器客户端希望接收一个存在时间不大于delta-secconds秒的资源 |
| max-stale[=delta-seconds] | 告知(代理)服务器客户端愿意接收一个超过缓存时间的资源,若有定义delta-seconds则为delta-seconds秒,若没有则为任意超出时间 |
| min-fresh=delta-seconds | 告知(代理)服务器客户端希望接收一个在小于delta-seconds秒内被更新过的资源 |
| no-transform | 告知(代理)服务器客户端希望获取实体数据没有被转换(比如压缩)过的资源 |
| noly-if-cached | 告知(代理)服务器客户端希望获取缓存的内容(若有),而不用向原服务器发去请求 |
| cache-extension | 自定义扩展值,若服务器不识别该值将被忽略掉 |
响应头:
| 字段名称 | 说明 |
|---|---|
| public | 表明任何情况下都得缓存该资源(即使是需要HTTP认证的资源) |
| Private=[field-name] | 表明返回报文中全部或部分(若指定了field-name则为field-name的字段数据)仅开放给某些用户(服务器指定的share-user,如代理服务器)做缓存使用,其他用户则不能缓存这些数据 |
| no-cache | 不直接使用缓存,要求向服务器发起(新鲜度校验)请求 |
| no-store | 所以内容都不会被保存到缓存或Internet临时文件中 |
| no-transform | 告知客户端缓存文件时不得对实体数据做任何改变 |
| noly-if-cached | 告知(代理)服务器客户端希望获取缓存的内容(若有),而不用向原服务器发去请求 |
| must-revalidate | 当前资源一定是向原方法服务器发去验证请求的,如请求是吧会返回504(而非代理服务器上的缓存) |
| proxy-revalidate | 与must-revalidate类似,但仅能应用于共享缓存(如代理) |
| max-age=delta-seconds | 告知客户端该资源在delta-seconds秒内是新鲜的,无需向服务器发请求 |
| s-maxage=delta-seconds | 同max-age,但仅能应用于共享缓存(如代理) |
| cache-extension | 自定义扩展值,若服务器不识别该值将被忽略掉 |
示例:
// server.js
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response) {
console.log('request come', request.url)
if (request.url === '/') {
const html = fs.readFileSync('test.html', 'utf8')
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(html)
}
if (request.url === '/script.js') {
response.writeHead(200, {
'Content-Type': 'text/javascript',
'Cache-Control': 'max-age=20,public' // 缓存20s 多个值用逗号分开
})
response.end('console.log("script loaded")')
}
}).listen(8888)
console.log('server listening on 8888')
// test.html
"en">
"UTF-8">
"viewport" content="width=device-width, initial-scale=1.0">
"X-UA-Compatible" content="ie=edge">
Document