1031 | SEED江苏大数据开发与应用大赛老肥码码码关注共 2783字,需浏览 6分钟 ·2022-11-01 17:532022年第三届江苏省大数据开发与应用大赛(SEED 大赛),由江苏省工业和信息化厅、无锡市人民政府联合举办,以“促数字转型,赋数据应用”为主题,设置医疗卫生、智能制造、能源管理、数字媒体四个赛道。大赛英文名称SEED,寓意海量的数据如一颗颗沉睡的种子,等待开发培育。这边给大家带来其中三个赛道(医疗卫生、智能制造、能源管理)的详细介绍。01 医疗卫生赛道赛题描述传统病理分析诊断需专业的病理医师在显微镜下逐个寻找目标区域和细胞,病理切片通常包含数万个细胞,但与疾病相关的目标区域及细胞仅占极小部分,大量冗余信息会给病理医师造成严重的“阅片疲劳”。AI能够辅助病理医生更高效更精准的判断,降低误诊和漏诊率。现阶段,医疗病理学已逐步进入数字病理时代,数字病理的推广与应用在减轻病理医师工作负担的基础上可提高我国医疗欠发达地区的诊断水平和操作规范。胃癌是临床当中比较常见的消化道肿瘤,胃癌患者的分期一般以TNM分期为主,T代表的是原发肿瘤情况,N代表的是区域淋巴结受累情况。M代表的是有没有远处转移。综合以上的TNM分期,可以确定肿瘤的总分期(即Ⅰ-Ⅳ期),为肿瘤的综合性治疗及转归提供科学的依据,是目前临床上采用的一种癌症分期的方法。本届Seed大赛医疗卫生赛道围绕胃癌病理图像,通过参赛者开发的AI算法,辅助判断胃癌图像的T分期指标。大赛在此基础上公布病例的其它多维度的病理诊断信息,选手需进行多模态数据分析,构建融合分析模型,实现患者的胃癌总分期的准确预测。赛题任务【初赛】本赛题提供一批病理数字切片,由专业医师给出癌症TNM分期指标的标注。选手需要使用计算机视觉相关技术,按照TNM分期指标中“T”指标对切片进行分类预测,辅助医生进行识别,提高病理诊断效率。使用TNM分期进行肿瘤评估时,T0代表无证据表明存在原发肿瘤、T1~T4代表癌细胞的侵入程度逐渐加深。在初赛中,选手需对提供的切片进行侵入程度的分类预测,共分为五类,包括T0、T1、T2、T3、T4。【复赛】大赛提供胃癌患者的多模态病理数据信息,选手需要依据这些数据使用人工智能技术构建算法模型进行胃癌分期的智能预测,预测出每个病例的病理总分期(即Ⅰ-Ⅳ期)情况,辅助医生进行病理诊断决策。评估指标【初赛】评估指标:Macro-F1(宏F1)【复赛】评估指标:Macro-F1(宏F1)02 智能制造赛道赛题描述智能制造是我国制造业转型升级的核心路径,江苏省更是以智能制造引领产业转型发展为目标,加快推动数字技术与工业企业深度融合。《江苏省制造业智能化改造和数字化转型三年行动计划(2022-2024年)》明确指出,到2024年底,江苏规模以上工业企业全面实施智能化改造和数字化转型,“智改数转”改革实践正在江淮大地上如火如荼地展开。本赛道紧跟“智改数转”步伐,以需求牵引、应用落地为主线,聚焦细分领域的智能化改造和数字化转型。赛题聚焦垃圾发电厂的真实需求,对于垃圾发电厂来说,在垃圾量固定的前提下,产生的主蒸汽流量越多,带来的经济效益就越高,但在燃烧过程中,要确保炉膛温度>850℃。但垃圾成分的多变及操作员工水平的参差不齐,会导致垃圾焚烧锅炉参数波动剧烈,且垃圾焚烧的整个过程是存在较大的延迟和滞后的。目前,垃圾焚烧炉的燃烧调整主要依据人工判断,年轻的师傅由于缺乏经验积累,无法提前预估主蒸汽流量的变化,导致调节不及时使得参数波动剧烈,从而超过锅炉额定值,甚至对锅炉设备造成较大损耗。因此,本赛题旨在通过锅炉传感器采集的多维度数据,深度分析挖掘数据间的联动关系从而预测锅炉的主蒸汽流量并同步辅助工艺人员进行关键指标的调整和优化。赛题任务【初赛】依托锅炉传感器采集的多维脱敏数据(采集频率为秒级别),根据锅炉工况,进行多维特征处理并构造算法模型,预测未来30分钟的主蒸汽流量。【复赛】依托锅炉传感器采集的多维脱敏数据(采集频率为秒级别),根据锅炉工况,进行多维特征处理并构造算法模型,在已知未来30分钟主蒸汽流量的基础上,公开推料器这段时间的启停状态,预测推料器的自动指令值。评估指标【初赛】采用RMSE(均方根误差)的值作为评判标准(误差越小排名越高),公式如下:【复赛】推料器自动投退信号启动(为True)时的推料器自动指令进行比对评估。采用RMSE(均方根误差)值作为评判标准(误差越小排名越高),公式如下:03 能源管理赛道赛题描述数字化转型工作中,一般由政府、行业集团牵头在合规的情况驱动数据分级开放,促进数据融合应用。在数据安全防护的前提下进行电力数据价值挖掘,具备非常大的创新意义和示范作用,这也对电力数据价值挖掘,电力场景设计,数据安全防护提出了更高的要求。隐私计算是指在保护数据本身不对外泄露的前提下实现数据分析计算的技术集合,达到对数据“可用、不可见”的目的,选择安全可靠的数据安全防护和隐私计算技术,将电力数据与其他领域的数据进行深度融合,通过场景设计,充分挖掘数据价值,形成能源领域数据资产是本赛道的命题方向。希望选手充分发挥对数据价值挖掘的洞察力和对前沿技术的探索精神,尝试电力数据的场景应用和价值挖掘,赋能数字化转型,赋能数字化政府建设。赛题任务【初赛】初赛阶段,选手需要基于隐私计算技术搭建联邦学习框架(推荐使用FATE联邦学习集群框架),在本地构建联邦学习模型。联邦学习一方持有电力数据,另一方持有政务数据,二者数据需要做到互相不可见。选手基于构建好的联邦学习集群,依托两方数据,预测企业未来一个季度的税收。【复赛】复赛阶段,大赛将提供开源的在线隐私计算环境(FATE1.8)。选手需要基于该环境并结合大赛提供的电力与政务的数据样例(较初赛开放更多的数据维度),在线构建联邦学习模型,预测企业未来一个季度的税收。评估指标【初赛】采用RMSE(均方根误差)作为评判标准(误差越小排名越高),公式如下:【复赛】复赛将根据模型性能进行排名,包括模型准确性和程序运行效率。复赛初始以模型准确性的评估标准RMSE进行排名;复赛最终排名会在初始排名基础上综合考虑模型的运行效率(模型训练和预测的时间)参赛对象 所有人赛程安排【初赛】2022年10月–11月10月中旬,发布初赛数据集;初赛截止后,作品评审,公布复赛晋级名单,本赛道取初赛成绩排名前50进入复赛。【复赛】2022年11月提供复赛数据集,复赛团队比赛,作品提交;提交截止,成绩评定,公布复赛成绩,各赛道复赛成绩前12名队伍进入决赛。决赛答辩以通知日期为准奖项设置一等奖1个,奖金8万元二等奖2个,奖金4万元/个三等奖3个,奖金1万元/个优胜奖6个,奖金0.5万元/个比赛网址https://www.jseedata.com/#dynamic关注我们不迷路,带你及时获取更多竞赛信息~浏览 120点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 通知 | 2021 中国高校计算机大赛 —— 微信大数据挑战赛数据派THU0报名 | 2024中国高校计算机大赛——大数据挑战赛报名启动!2016年,教育部高等学校计算机类专业教学指导委员会、教育部高等学校软件工程专业教学指导委员会、教育部高等学校大学计算机课程教学指导委员会、全国高等学校计算机教育研究会联合创办了“中国高校计算机大赛”(China Collegiate Computing Contest,简称C4),目前“中国高校计报名即将截止,中国移动“梧桐杯”大数据应用创新大赛,寻找大数据敢想者!Datawhale0鲲鹏大数据鲲鹏大数据0快讯 | 2024中国高校计算机大赛——大数据挑战赛晋级复赛队伍揭晓7月25日,经过初赛阶段的激烈角逐,2024中国高校计算机大赛——大数据挑战赛进入复赛的参赛队伍名单已经出炉。本次大赛旨在通过算法比拼激发数据处理与分析的新思路,探索气象大数据的奥秘,促进大数据技术的创新与应用。大赛吸引了来自全国各地的高校学生和企业在职人员的积极参与,共有386所高校的1777支队报名 | 2022中国高校计算机大赛——微信大数据挑战赛即将开启数据派THU0【数据竞赛】天池蛋白质结构预测大赛总结机器学习初学者0大数据之数据脱敏技术程序源代码0江苏海平面数据科技有限公司江苏海平面数据科技有限公司0阿里大数据之路:数据技术篇大总结程序源代码0点赞 评论 收藏 分享 手机扫一扫分享分享 举报

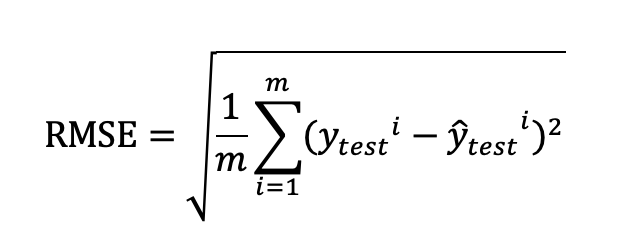
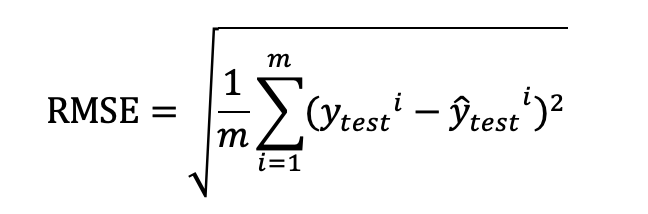
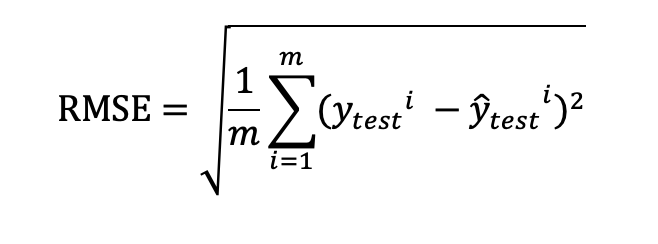
 下载APP
下载APP