
大数据之数据脱敏技术
背景与目标
在数据仓库建设过程中,数据安全扮演着重要角色,因为隐私或敏感数据的泄露,会对数据主体(客户,员工和公司)的财产、名誉、人身安全、以及合法利益造成严重损害。
因此我们需要严格控制对仓库中的数据访问,即什么样的人员或者需求才可以访问到相关的数据。
这就要求对数据本身的敏感程度进行安全级别划分。数据有了安全等级的划分,才能更好管理对数据访问控制,以此来保护好数据安全。
举个例子简单的说明下,例如我们仓库中有一张关于注册用户的基本信息表User,其中有手机号mobile,昵称username两个字段。我们在划分数据安全层级的时,将用户mobile的安全等级划分为L2要高于username的等级L1,并规定只有访问权限达到L2的运营部门才能访问mobile字段。
这样在公司各个部门需要访问注册用户基本信息表User时,我们只需检查访问者是否来自运营部门,如果是运营部可以访问mobile,如果不是只能访问username信息了。
这样就有效的防止用户手机号被不相关工作人员泄露出去,同时也不影响查询用户username的需求。
但是往往在实际生产过程中,应用场景会更加复杂,仅靠类似这样的访问控制,满足不了生产的需要,还需要结合其它的途径,而数据脱敏就是一种有效的方式,既能满足日常生产的需要,又能保护数据安全。
数据脱敏,具体指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。这样可以使数据本身的安全等级降级,就可以在开发、测试和其它非生产环境以及外包或云计算环境中安全地使用脱敏后的真实数据集。
借助数据脱敏技术,屏蔽敏感信息,并使屏蔽的信息保留其原始数据格式和属性,以确保应用程序可在使用脱敏数据的开发与测试过程中正常运行。
敏感数据梳理
在数据脱敏进行之前,我们首先要确定哪些数据要作为脱敏的目标。我们根据美团特有的业务场景和数据安全级别划分(绝密、高保密、保密、可公开,四个级别), 主要从“高保密”等级的敏感数据,开始进行梳理。
这里我们把敏感数据分成四个维度进行梳理,用户、商家、终端、公司。
从用户维度进行梳理可能有这些敏感字段如下:手机号码、邮件地址、账号、地址、固定电话号码等信息(此外个人隐私数据相关还有如:种族、政治观点、宗教信仰、基因等)
从商家维度进行梳理:合同签订人,合同签订人电话等(不排除全局敏感数据:如商家团购品类等)
从用户终端维度进行梳理:能够可能标识终端的唯一性字段,如设备id。
从公司角度进行梳理:交易金额、代金卷密码、充值码等
确定脱敏处理方法
梳理出了敏感数据字段,我们接下来的工作就是如何根据特定的应用场景对敏感字段实施具体的脱敏处理方法。
常见的处理方法如下几种有:
替换:如统一将女性用户名替换为F,这种方法更像“障眼法”,对内部人员可以完全保持信息完整性,但易破解。
重排:序号12345重排为54321,按照一定的顺序进行打乱,很像“替换”, 可以在需要时方便还原信息,但同样易破解。
加密:编号12345加密为23456,安全程度取决于采用哪种加密算法,一般根据实际情况而定。
截断:13811001111截断为138,舍弃必要信息来保证数据的模糊性,是比较常用的脱敏方法,但往往对生产不够友好。
掩码: 123456 -> 1xxxx6,保留了部分信息,并且保证了信息的长度不变性,对信息持有者更易辨别, 如火车票上得身份信息。
日期偏移取整:20130520 12:30:45 -> 20130520 12:00:00,舍弃精度来保证原始数据的安全性,一般此种方法可以保护数据的时间分布密度。
但不管哪种手段都要基于不同的应用场景,遵循下面两个原则:
1.remain meaningful for application logic(尽可能的为脱敏后的应用,保留脱敏前的有意义信息) 2.sufficiently treated to avoid reverse engineer(最大程度上防止黑客进行破解)
以这次脱敏一个需求为例:
美团一般的业务场景是这样的,用户在网站上付款一笔团购单之后,我们会将团购密码,发到用户对应的手机号上。这个过程中,从用户的角度来看团购密码在未被用户消费之前,对用户来说是要保密的,不能被公开的,其次美团用户的手机号也是要保密的,因为公开之后可能被推送一些垃圾信息,或者更严重的危害。
从公司内部数据分析人员来看,他们有时虽然没有权限知道用户团购密码,但是他们想分析公司发送的团购密码数量情况,这是安全允许;再有数据分析人员虽然没有权限知道用户具体的手机号码,但是他们需要统计美团用户手机的地区分布情况,或者运营商分布差异,进而为更上层的决策提供支持。
根据这样的需求,我们可以对团购密码做加密处理保证其唯一性,也保留其原有的数据格式,在保密的同时不影响数据分析的需求。同样,我们将用户的手机号码的前7位,关于运营商和地区位置信息保留,后四位进行模糊化处理。这样同样也达到了保护和不影响统计的需求。
因此从实际出发遵循上面的两个处理原则,第一阶段我们在脱敏工具集中,确定了如下4种基本类型的脱敏方案(对应4个udf):
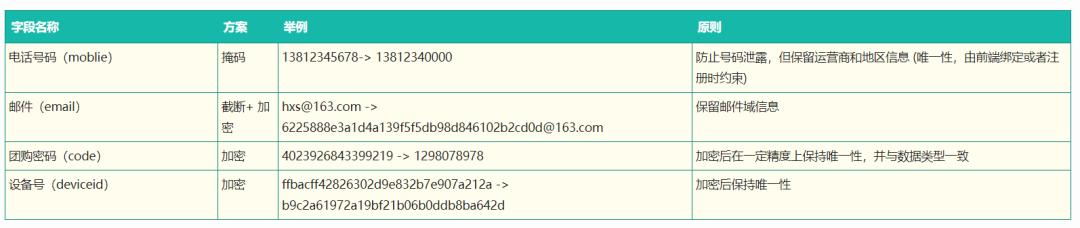
确定实施范围与步骤
通过上面字段的梳理和脱敏方案的制定,我们对美团数据仓库中涉及到得敏感字段的表进行脱敏处理。在数据仓库分层理论中,数据脱敏往往发生在上层,最直接的是在对外开放这一层面上。在实际应用中,我们既要参考分层理论,又要从美团现有数据仓库生产环境的体系出发,主要在数据维度层(dim),以及基础服务数据层(fact)上实施脱敏。这样,我们可以在下游相关数据报表以及衍生数据层的开发过程中使用脱敏后的数据,从而避免出现数据安全问题。
确认处理的表和字段后,我们还要确保相关上下游流程的正常运行, 以及未脱敏的敏感信息的正常产出与存储(通过更严格的安全审核来进行访问)。
以用户信息表user为例,脱敏步骤如下:
1.首先生产一份ndm_user未脱敏数据,用于未脱敏数据的正常产出。2.对下游涉及的所有依赖user生产流程进行修改,来确保脱敏后的正常运行,这里主要是确认数据格式,以及数据源的工作。3.根据对应的脱敏方法对user表中对应的字段进行脱敏处理。
总结
通过上面的几个步骤的实施,我们完成了第一阶段的数据脱敏工作。在数据脱敏方案设计与实施过程中, 我们觉得更重要的还是从特定的应用场景出发进行整体设计,兼顾了数据仓库建设这一重要考量维度。数据脱敏实施为公司数据安全的推进,提供了有力支持。当然,我们第一阶段脱敏的工具集还相对较少,需要补充。脱敏的技术架构还有待完善和更加自动化。
本文关于数据安全和数据访问隔离的控制阐述较少,希望通过以后的生产实践,继续为大家介绍。
参考文献如下:
http://en.wikipedia.org/wiki/Data_masking
http://www.prnews.cn/press_release/51034.htm
tech.meituan.com/2014/04/08/data-desensitization.html
--end--
扫描下方二维码
添加好友,备注【交流群】
拉你到学习路线和资源丰富的交流群