Redis Sentinel 架构原理详解
每日英文
You think letting go would make me happy, but you don’t know my biggest happiness is to hold your hand.
你以为放手可以成全我的幸福,可你不知道,我最大的幸福就是能和你手牵手。
每日掏心话
牵念于心守一方宁静品一份孤独,于漫漫红尘中携一缕安然,淡泊烟火人间。
来自:CoderJed | 责编:乐乐
链接:jianshu.com/p/00a6d7cc82b2

程序员小乐(ID:study_tech)第 736 次推文 图片来自网络
往日回顾:传言阿里P10赵海平,被P11多隆判定3.25离职,如何评价阿里 P10 赵海平对王垠的面试?
正文
1. Redis Sentinel 简介
redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,再通知所有的程序把 master 地址统统改一遍,然后重新上线。毫无疑问,这种故障处理的方法是效率低下的,无法接受。
于是,redis 从 2.8 开始正式提供了 sentinel 架构来解决这个问题。
redis sentinel 是 redis 的高可用实现方案,多个 sentinel 进程协同工作,组成了一套分布式的架构,它负责持续监控主从节点的健康状况,当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 要地址,sentinel 会将最新的主节点地址告诉客户端。如此应用程序将无需重启即可自动完成节点切换。
2. Redis Sentinel 架构及原理
我们以经典的一主二从架构来说明的 sentinel 的原理。
(1) 主从切换的过程
每个 sentinel 节点通过定期监控 master 的健康状况。
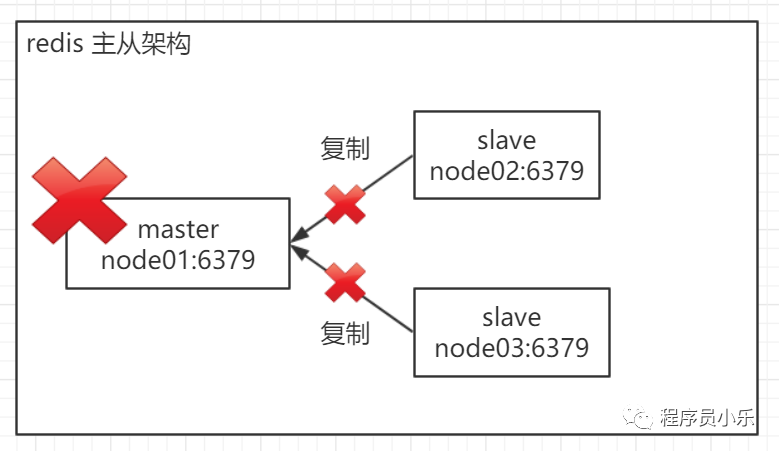
主节点出现故障,两个从节点与主节点失去连接,主从复制失败。
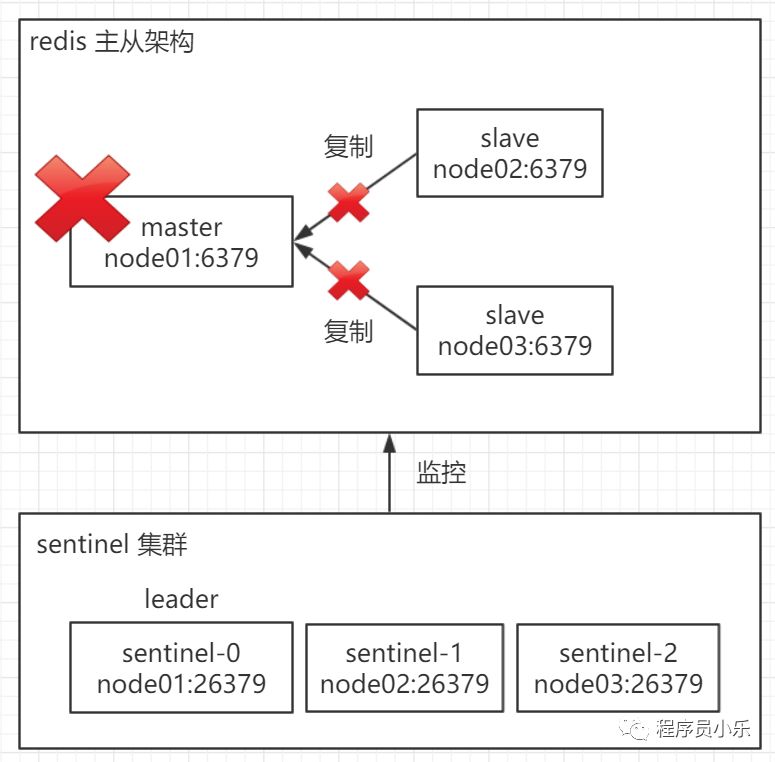
sentinel 集群 发现 master 故障后,多个 sentinel 节点对主节点的故障达成一致,在 3 个 sentinel 节点中选择一个作为 leader ,例如,选举出 sentinel-0 节点作为 leader,来负责故障转移。
leader sentinel 把一个 slave 节点提升为 master,并让另一个 slave 从新的 master 复制数据,并告知客户端新的 master 的信息。
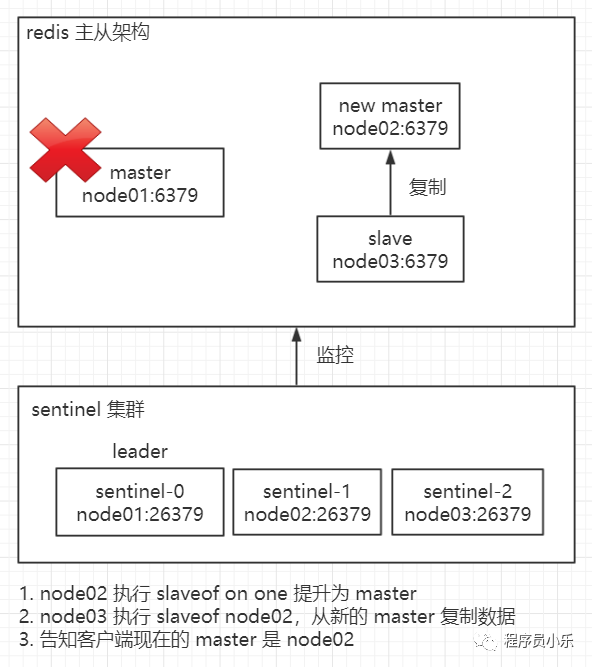
故障的旧 master 上线后,leader sentinel 让它从新的 master 复制数据。
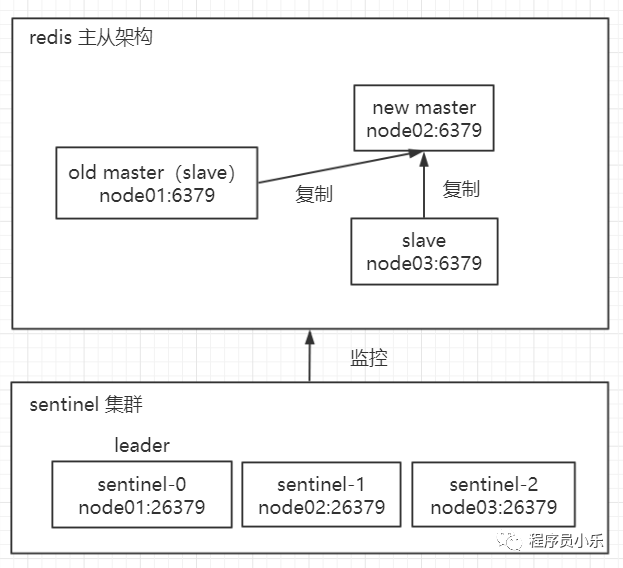
以上就是 sentinel 集群进行故障转移的整体流程,具体的一些细节还会详细介绍,这里先总结一下 sentinel 集群在 redis 主从架构高可用中起到的 4 个作用:
集群监控
sentinel 节点会定期检测 redis 数据节点、其余 sentinel 节点是否故障。故障转移
实现从节点晋升为主节点并维护后续正确的主从关系。配置中心
sentinel 架构中,客户端在初始化的时候连接的是 sentinel 集群,从中获取主节点信息。消息通知
sentinel 节点会将故障转移的结果通知给客户端。
此外,使用 sentinel 集群而不是单个 sentinel 节点去监控 redis 主从架构有两个好处:
对于节点的故障判断由多个 sentinel 节点共同完成,这样可以有效地防止误判。
sentinel 集群可以保证自身的高可用性,即某个 sentinel 节点自身故障也不会影响 sentinel 集群的健壮性。
(2) sentinel 集群的监控功能详解
sentinel 集群通过三个定时监控任务完成对各个节点发现和监控。
每隔10秒,每个 sentinel 节点会向主节点和从节点发送 info 命令获取 redis 主从架构的最新情况。例如,发送
info replication命令可以得到以下信息:
node01:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.239.102,port=6379,state=online,offset=18621889,lag=1
slave1:ip=192.168.239.103,port=6379,state=online,offset=18621889,lag=1
这样,sentinel 集群就可以得知 master 和 slave 的基本信息,通过向主节点执行 info 命令,获取从节点的信息,所以 sentinel 节点不需要显式配置监控从节点,当有新的从节点加入时都可以立刻感知出来,当 master 节点故障或者故障转移后,可以通过 info 命令实时更新 redis 主从信息。
每隔2秒,每个 sentinel 节点会向 redis 数据节点的
__sentinel__:hello这个channel(频道)发送一条消息,消息的内容是:
每个 sentinel 节点会订阅该 channel,来了解其他
sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
发现新的 sentinel节点:通过订阅主节点的
__sentinel__:hello了解其他的 sentinel 节点信息,如果是新加入的 sentinel 节点,将该 sentinel 节点信息保存起来,并与该 sentinel 节点创建连接sentinel 节点之间交换主节点的状态,用于确认 master 下线和故障处理的 leader 选举。
每隔1秒,每个 sentinel 节点会向主节点、从节点、其余 sentinel 节点发送一条ping命令做一次心跳检测,来确认这些节点是否可达。通过定时发送ping命令,sentinel 节点对主节点、从节点、其余 sentinel 节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点下线判定的重要依据。
(3) sdown(主观下线) 和 odown(客观下线)
主观下线
每个 sentinel 节点每隔1秒对主节
点、从节点、其他 sentinel 节点发送 ping 命令做心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,sentinel节点就会认为该节点下线,这个行为叫做主观下线。主观下线是某个 sentinel 节点的判断,并不是 sentinel 集群的判断,所以存在误判的可能。客观下线
当 sentinel 主观下线的节点是主节点时,该 sentinel 节点会通过sentinel ismaster-down-by-addr命令向其他 sentinel 节点询问对主节点的判断,当超过个数(quorum可配置)的 sentinel 节点认为主节点确实有问题,这时该 sentinel 节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分是 sentinel 节点都对主节点的下线做了同意的判定,那么这个判定就是客观的。
介绍一下sentinel is-master-down-by-addr命令:
sentinel is-master-down-by-addr <ip> <port> <current_epoch> <runid>
ip、port:询问此 ip:port 的 redis 进程是否下线
current_epoch:当前配置版本
runid:如果为当前 sentinel 节点的 runid,则此命令用于申请自己成为故障处理的 leader,如果是*,则此命令用于向其他 sentinel 节点确认 master 是否下线。
此命令返回结果包括3个信息:
down_state:目标 sentinel 节点对于主节点的下线判断,1是下线,0是在线。
leader_runid:当leader_runid等于
*时,代表返回结果是说明主节点是否不可达,当 leader_runid 等于具体的runid,代表目标节点同意该 runid sentinel 节点成为 leader。leader_epoch:leader 版本。
(4) 故障转移前的 leader 选举
当 sentinel 集群确认 master odown,需要选举出一个 leader 节点来进行故障转移,选举过程如下:
每个在线的 sentinel 节点都有资格成为 leader,当它确认主节点客观下线时候,会向其他 sentinel 节点发送
sentinel is-master-down-by-addr命令,要求将自己设置为leader,比如 sentinel-0 节点首先发起请求成为 leader 的请求。每个 sentinel 节点都只能投出一票,于是当 sentinel-0 节点发起成为 leader 的请求后,会得到 sentinel-1 和 sentinel-2 节点的投票,总共得到 2 票,得到的票数和以下公式计算的值作比较:
max(quorum, num(sentinels) / 2 + 1)
= max(2, 3 / 2 + 1)
= max(2, 1 + 1)
= max(2, 2)
= 2
当得到的票数 >= max(quorum, num(sentinels) / 2 + 1) 的值,那么该 sentinel 节点成为 leader,于是,sentinel-0 节点成为 leader。
比如下一个确认 master 客观下线的 sentinel 节点为 sentinel-1,当它发起成为 leader 的请求后,由于 sentinel-2 节点已经给 sentinel-0 节点投过票了,于是它只能得到 sentinel-0 节点投的一票,所以它不能成为 leader,而当 sentinel-2 发起请求成为 leader 的请求后,它一票都得不到。于是当已经选举出 leader 后,就不会再继续进行选举流程了,因为是没有意义的。
如果一次选举没有选举出 leader,那么会进行下一次选举。
总结:正常情况下,哪个 sentinel 节点最先确认 master 客观下线,哪个 sentinel 节点就会成为执行故障转移的 leader。
(5) 故障转移前新的 master 选择
要执行故障转移,首先要从 slave 中选择一个作为新的 master,选择的准则如下:
不选择不健康的 slave,以下状态的 slave 是不健康的:
主观下线的 slave
大于等于5秒没有回复过 sentinel 节点 ping 响应的 slave
与 master 失联超过
down-after-milliseconds * 10秒的 slave
对健康的 slave 进行排序
选择 priority(从节点优先级,可配置,默认100)最低的从节点,如果有优先级相同的节点,进行下一步。注意如果这个值配置为0,则代表禁止该节点成为 master。
选择复制偏移量最大的从节点(复制的最完整),如果有复制偏移量相等的节点,进行下一步。
选择 runid 最小的从节点。
然后就是 leader 进行故障转移的过程了:
leader 对选择出来的要成为 new master 的 slave 执行
slaveof no one命令让其成为 new master。leader 会向剩余的 slave 发送命令,让它们成为 new master 的 slave。
leader 会将 old master 更新为 slave点,并保持着对其关注,当其恢复后命令它去复制 new master。复制规则和
parallel-syncs配置有关。该配置指定了在执行故障转移时,最多可以有多少个 slave 同时对 new master 进行同步,这个数字越小,完成故障转移所需的时间就越长。如果从服务器被设置为允许使用过期数据集(redis.conf 中slave-serve-stale-data配置) ,那么你可能不希望所有 slave 都在同一时间向 new master 发送同步请求,因为尽管复制过程的绝大部分步骤都不会阻塞slave, 但 slave 在 load new master 发来的 RDB 文件时, 仍然会造成其在一段时间内不能处理请求。如果全部 slave 一起对 new master 进行同步, 那么就可能会造成所有 slave 在短时间内全部不可用的情况出现。你可以通过将这个值设为 1 来保证故障转移后最多只有一个 slave 处于不可用状态。但这样的话,全部 slave 的数据同步就是串行的,这样就会增加故障转移整个过程的时间。
(6) Sentinel 集群的 quorum 和 majority
quorum 是在 sentinel.conf中手动配置的,默认为2
# sentinel monitor [master-name] [master-ip] [master-port] [quorum]
sentinel monitor mymaster 127.0.0.1 6379 2
意味着,只有 大于等于 quorum 数量都认为 master 主观下线,sentinel 集群才会认为 master 客观下线。
sentinel 集群执行故障转移时需要选举 leader,此时涉及到 majority,majority 代表 sentinel 集群中大部分 sentinel 节点的个数,只有大于等于
max(quorum, majority)个节点给某个 sentinel 节点投票,才能确定该 sentinel 节点为 leader,majority 的计算方式为:num(sentinels) / 2 + 1,比如:
2 个节点的 sentinel 集群的 majority为 2
3 个节点的 sentinel 集群的 majority为 2
4 个节点的 sentinel 集群的 majority为 3
5 个节点的 sentinel 集群的 majority为 3
所以 sentinel 集群的节点个数至少为3个,当节点数为2时,假如一个 sentinel 节点宕机,那么剩余一个节点是无法让自己成为 leader 的,因为2个节点的 sentinel 集群的 majority 是 2,此时没有2个节点都给剩余的节点投票,也就无法选择出 leader,从而无法进行故障转移。
另外最好把 quorum 的值设置为 <= majority,否则即使 sentinel 集群剩余的节点满足 majority 数,但是有可能不能满足 quorum 数,那还是无法选举 leader,也就不能进行故障转移。
(7) configuration epoch
configuration epoch 是当前 redis 主从架构的配置版本号,无论是 sentinel 集群选举 leader 还是进行故障转移的时候,要求各 sentinel 节点得到的 configuration epoch 都是相同的,sentinel is-master-down-by-addr 命令中就必须有当前配置版本号这个参数,在选举 leader 过程中,如果本次选举失败,那么进行下一次选举,就会更新配置版本号,也就是说,每次选举都对应一个新的 configuration epoch,在故障转移的过程中,也要求各个 sentinel 节点使用相同的 configuration epoch。
在故障转移成功之后,sentinel leader 会更新生成最新的 master 配置,configuration epoch 也会更新,然后同步给其他的 sentinel 节点,这样保证 sentinel 集群中保存的 master <-> slave 配置都是最新的,当 client 请求的时候就会拿到最新的配置信息。
(8) Redis Sentinel 可能出现的问题以及解决办法
redis sentinel 无法保证数据完全不丢失,原因有两个:
(1) 异步复制导致的数据丢失
因为 master -> slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这部分数据就丢失了。
(2) redis 服务脑裂导致的数据丢失
脑裂,也就是说,某个 master 所在机器突然网络故障,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了master,这个时候,集群里就会有两个master,也就是所谓的脑裂。此时虽然某个 slave 被切换成了 master,但是 client 还没来得及切换到新的master,还继续写向旧 master 的数据就丢失了。因为旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master 上去,自己的数据会清空,重新从新的 master 复制数据。
redis 提供了两个配置参数可以尽量丢失少的数据:
min-slaves-to-write 1
min-slaves-max-lag 10
第一个参数表示 master 必须至少有一个 slave 在进行正常复制,否则就拒绝写请求,此时 master 丧失可用性。
何为正常复制,何为异常复制?这个就是由第二个参数控制的,它的单位是秒,
表示如果 10s 没有收到从节点的反馈,就意味着从节点同步不正常。
这样可以把 master 宕机期间的数据丢失降低到可控范围内。
redis-2.6 版本提供的是 redis sentinel v1版本,但是功能性和健壮性都有一些问题,如果想使用 redis sentinel的话,建议使用2.8以上版本,也就是v2版本的 redis sentinel。
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,学习能力的提升上有新的认识,欢迎转发分享给更多人。
猜你还想看
关注「程序员小乐」,收看更多精彩内容