
保姆级NLP学习路线来啦!
这个保姆级不是形容这份指南有多详细,而是形容这个指南会伴随你们一起成长哟(其实就是太多了写不完)。之后的更新都会定期发文并汇总在Github上,欢迎催更:
https://github.com/leerumor/nlp_tutorial
下面开始学!习!(敲黑板)
如何系统地学习
机器学习是一门既重理论又重实践的学科,想一口吃下这个老虎是不可能的,因此学习应该是个循环且逐渐细化的过程。
首先要有个全局印象,知道minimum的情况下要学哪些知识点:
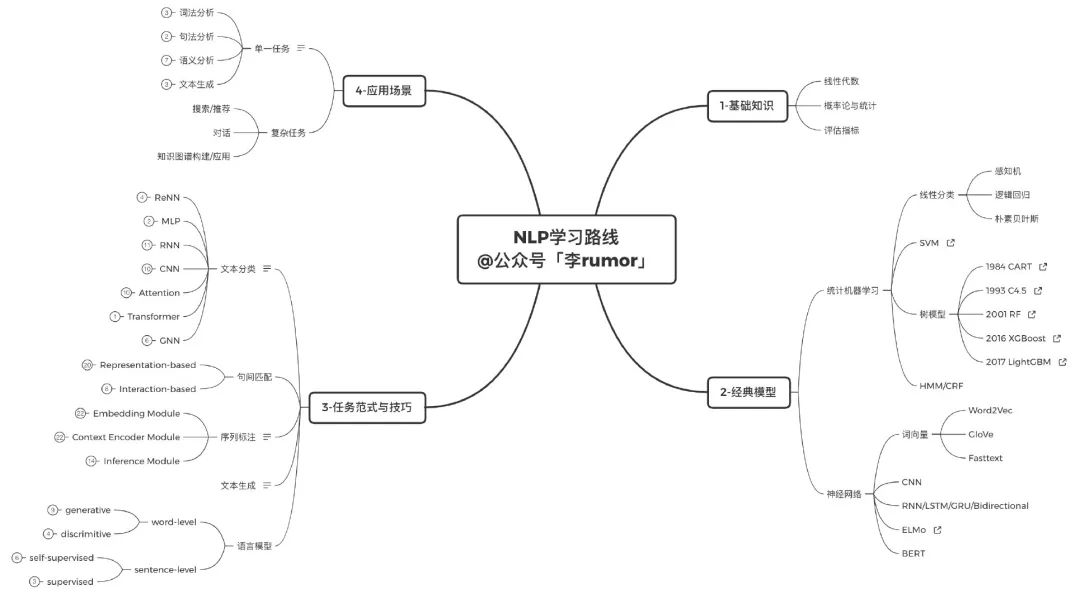
之后就可以开始逐个击破,但也不用死磕,控制好目标难度,先用三个月时间进行第一轮学习:
读懂机器学习、深度学习原理,不要求手推公式 了解经典任务的baseline,动手实践,看懂代码 深入一个应用场景,尝试自己修改模型,提升效果
迈过了上面这道坎后,就可以重新回归理论,提高对自己的要求,比如手推公式、盲写模型、拿到比赛Top等。
Step1: 基础原理
机器学习最初入门时对数学的要求不是很高,掌握基础的线性代数、概率论就可以了,正常读下来的理工科大学生以上应该都没问题,可以直接开始学,碰到不清楚的概念再去复习。
统计机器学习部分,建议初学者先看懂线性分类、SVM、树模型和图模型,这里推荐李航的「统计学习方法」,薄薄的摸起来没有很大压力,背着也方便,我那本已经翻四五遍了。喜欢视频课程的话可以看吴恩达的「CS229公开课」或者林田轩的「机器学习基石」。但不管哪个教程,都不必要求一口气看完吃透,第一轮先重点看懂以下知识点就够了:
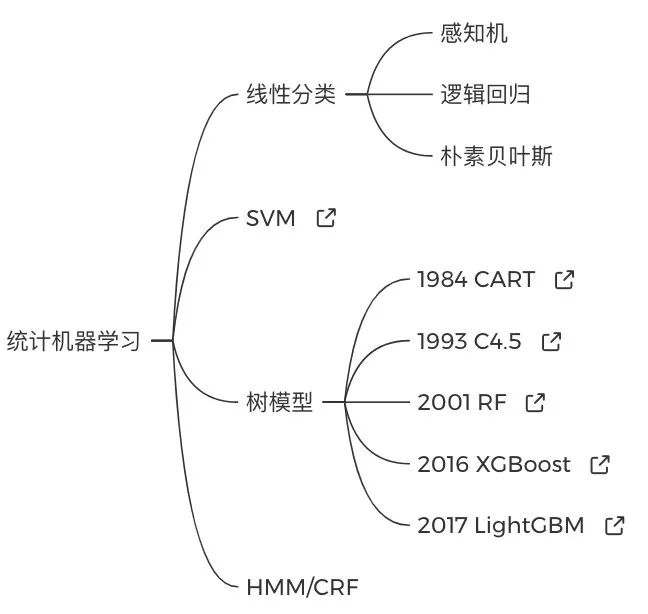
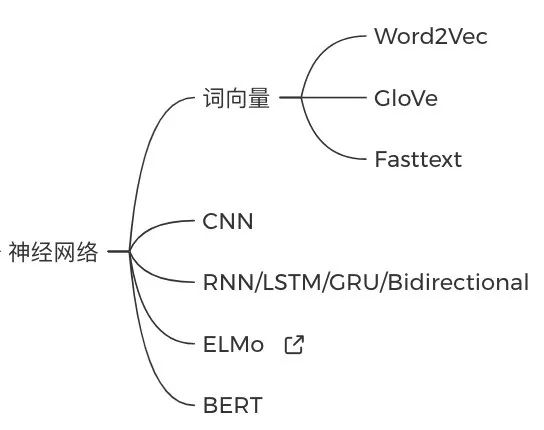
深度学习部分,推荐吴恩达的「深度学习」网课、李宏毅的「深度学习」网课或者邱锡鹏的「神经网络与深度学习」教材。先弄懂神经网络的反向传播推导,然后去了解词向量和其他的编码器的核心思想、前向反向过程:
Step2: 经典模型与技巧
有了上述的基础后,应该就能看懂模型结构和论文里的各种名词公式了。接下来就是了解NLP各个经典任务的baseline,并看懂源码。对于TF和Pytorch的问题不用太纠结,接口都差不多,找到什么就看什么,自己写的话建议Pytorch。
快速了解经典任务脉络可以看综述,建议先了解一两个该任务的经典模型再去看,否则容易云里雾里:
2020 A Survey on Text Classification: From Shallow to Deep Learning
2020 A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
2020 Evolution of Semantic Similarity - A Survey
2017 Neural text generation: A practical guide
2018 Neural Text Generation: Past, Present and Beyond
2019 The survey: Text generation models in deep learning
2020 Efficient Transformers: A Survey
文本分类
文本分类是NLP应用最多且入门必备的任务,TextCNN堪称第一baseline,往后的发展就是加RNN、加Attention、用Transformer、用GNN了。第一轮不用看得太细,每类编码器都找个代码看一下即可,顺便也为其他任务打下基础。

但如果要做具体任务的话,建议倒序去看SOTA论文,了解各种技巧,同时善用知乎,可以查到不少提分方法。
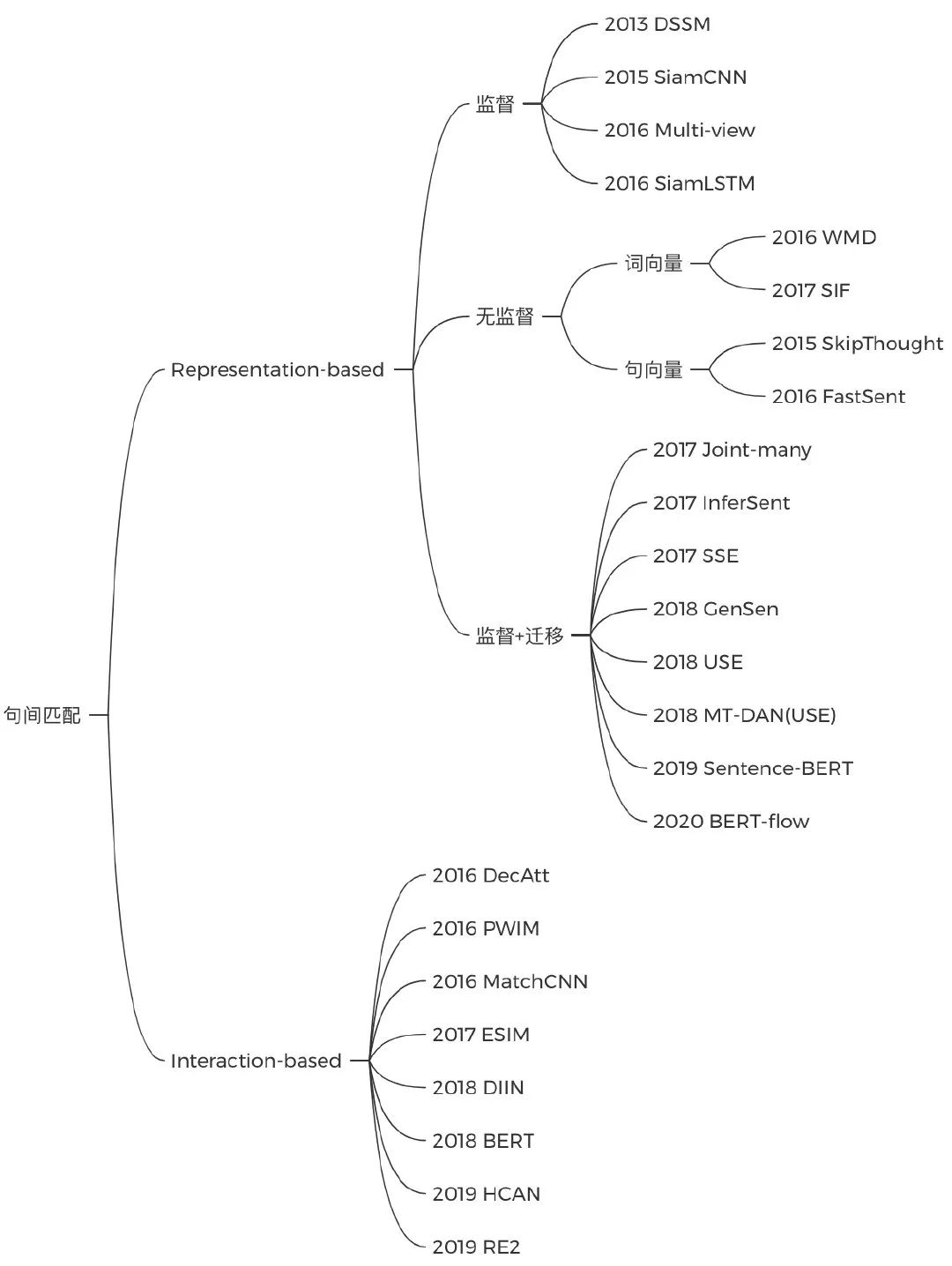
文本匹配
文本匹配会稍微复杂些,它有双塔和匹配两种任务范式。双塔模型可以先看SiamCNN,了解完结构后,再深入优化编码器的各种方法;基于匹配的方式则在于句子表示间的交互,了解BERT那种TextA+TextB拼接的做法之后,可以再看看阿里的RE2这种轻量级模型的做法:
序列标注
序列标注主要是对Embedding、编码器、结果推理三个模块进行优化,可以先读懂Bi-LSTM+CRF这种经典方案的源码,再去根据需要读论文改进。

文本生成
文本生成是最复杂的,具体的SOTA模型我还没梳理完,可以先了解Seq2Seq的经典实现,比如基于LSTM的编码解码+Attention、纯Transformer、GPT2以及T5,再根据兴趣学习VAE、GAN、RL等。
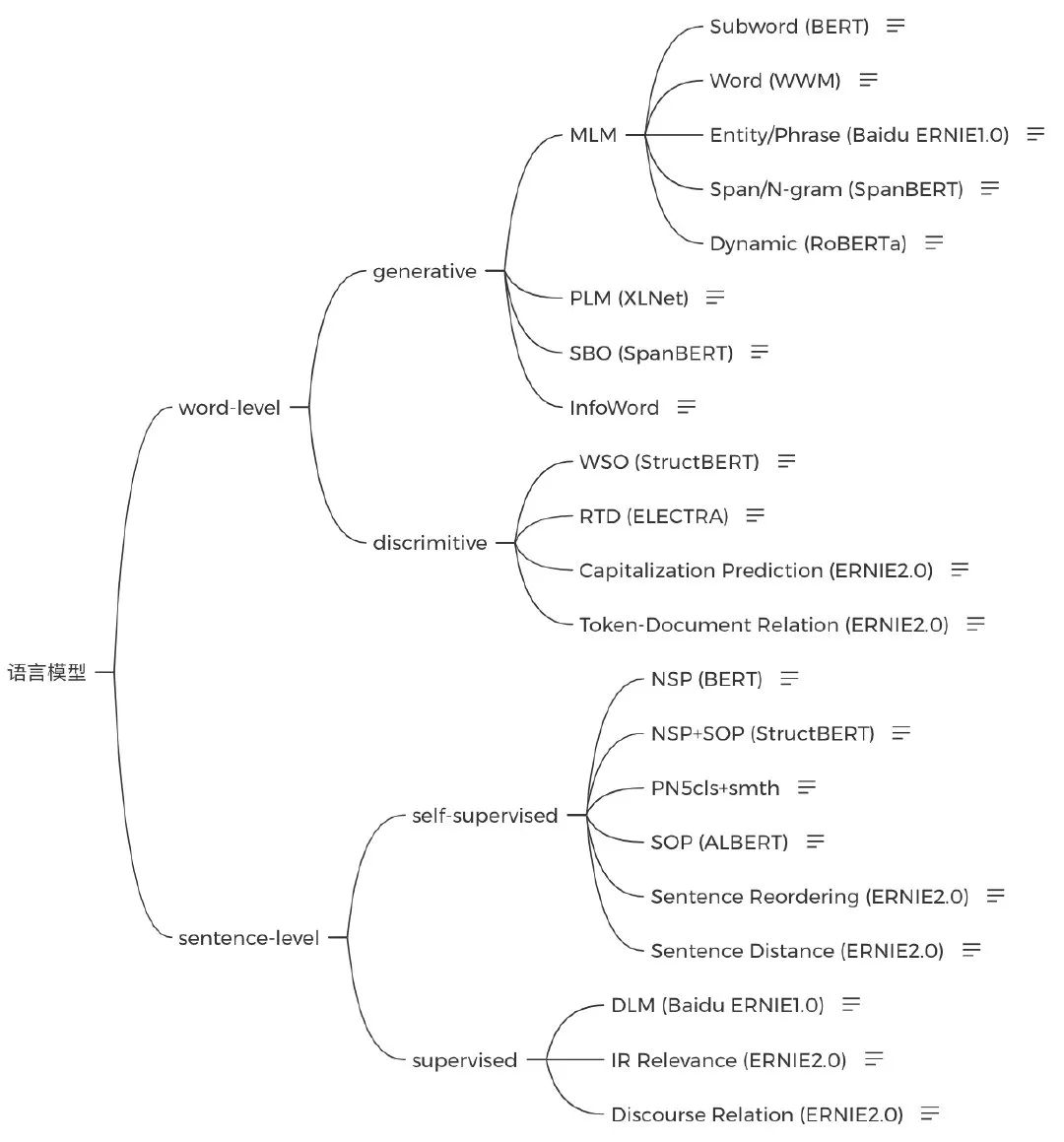
语言模型
语言模型虽然很早就有了,但18年BERT崛起之后才越来越被重视,成为NLP不可或缺的一个任务。了解BERT肯定是必须的,有时间的话再多看看后续改进,很经典的如XLNet、ALBERT、ELECTRA还是不容错过的。
Step3: 实践优化
上述任务都了解并且看了一些源码后,就该真正去当炼丹师了。千万别满足于跑通别人的github代码,最好去参加一次Kaggle、天池、Biendata等平台的比赛,享受优化模型的摧残。
Kaggle的优点是有各种kernel可以学习,国内比赛的优点是中文数据方便看case。建议把两者的优点结合,比如参加一个国内的文本匹配比赛,就去kaggle找相同任务的kernel看,学习别人的trick。同时多看些顶会论文并复现,争取做完一个任务后就把这个任务技巧摸清。