
使用OpenCV和Dlib的头部姿态估计
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在许多应用中,我们需要知道头部相对于相机是如何倾斜的。例如,在虚拟现实应用程序中,人们可以使用头部的姿势来呈现场景的正确视图。在驾驶员辅助系统中,一个摄像头可以用头部姿态估计来判断司机是否注意到了道路。当然,我们可以使用基于头部姿势的手势来控制一个没有手的应用程序/游戏。显然,头部姿势估计在生活中是很有用的。

在计算机视觉中,物体的姿态是指物体相对于摄像机的相对方位和位置。可以通过相对于相机移动物体或相对于物体移动相机来改变姿势。
本篇文章中描述的姿态估计问题通常称为透视-n点计算机视觉术语中的问题或PNP。我们将在下面的章节中更详细地看到,在这个问题中,我们的目标是当我们有一个校准的照相机时,找到一个物体的姿态,并且我们知道N物体上的三维点和图像中相应的2D投影。
三维刚性物体相对于摄像机只有两种运动方式。
1. 平移:将相机从其当前的3D位置移动(X,Y,Z)到一个新的3D位置(X',Y',Z')。正如我们看到的,平移有3个自由度-你可以在X,Y或Z方向移动。翻译用向量表示。t等于(X'-X,Y'-Y,Z'-Z)。
2. 旋转:我们还可以将摄像机旋转到X,Y,Z轴。因此,旋转也有三个自由度。有许多表示旋转的方法。我们可以使用欧拉角(滚动、俯仰和偏航),a 旋转矩阵,或旋转方向(即轴)和角度.
因此,估计三维物体的姿态意味着找到6个数字--3个用于平移,3个用于旋转。
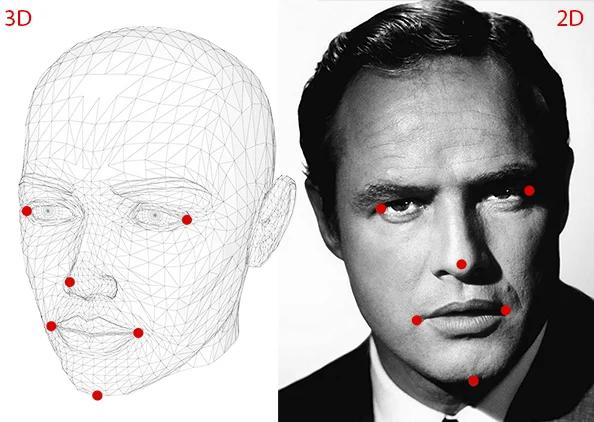
要计算图像中物体的三维姿态,需要以下信息
1. 几个点的二维坐标:我们需要二维(x,y)位置的几个点的图像。在上图情况中,我们可以选择眼角,鼻尖,嘴角等等。面部标志探测器为我们提供了很多可供选择的地方。在本篇文章中,我们将使用鼻尖,下巴,左眼的左角,右眼的右角,嘴角的左下角和嘴角。
2. 相同点的三维位置:我们还需要2D特征点的三维位置。你可能会想,我们需要照片中人的三维模型,以获得三维位置。理想情况下,是的,但实际上并非如此。一个通用的3D模型就足够了。你从哪里得到头部的三维模型?我们不需要一个完整的3D模型。你只需要一些任意参照系中的几个点的3D位置。在本篇文章中,我们将使用以下3D点。
鼻尖:(0.0,0.0,0.0)
下巴:(0.0,-330.0,-65.0)
左眼角:(-225.0f,170.0f,-135.0)
右眼角:(225.0,170.0,-135.0)
嘴角:(-150.0,-150.0,-125.0)
嘴角:(150.0,-150.0,-125.0)
请注意,上述各点位于某些任意的参考框架/坐标系中。这叫做世界坐标(OpenCV文档中的模型坐标)。
3. 摄像机固有参数。如前所述,在这个问题中,相机被假定是校准的。换句话说,我们需要知道相机的焦距,图像中的光学中心和径向畸变参数。所以我们需要校准相机。我们可以用图像的中心近似光学中心,近似焦距由图像的宽度(以像素为单位)并假定径向失真不存在。
姿态估计有几种算法。第一个已知的算法可以追溯到1841年。解释这些算法的细节超出了这篇文章的范围,但是这里有一个一般性的想法。
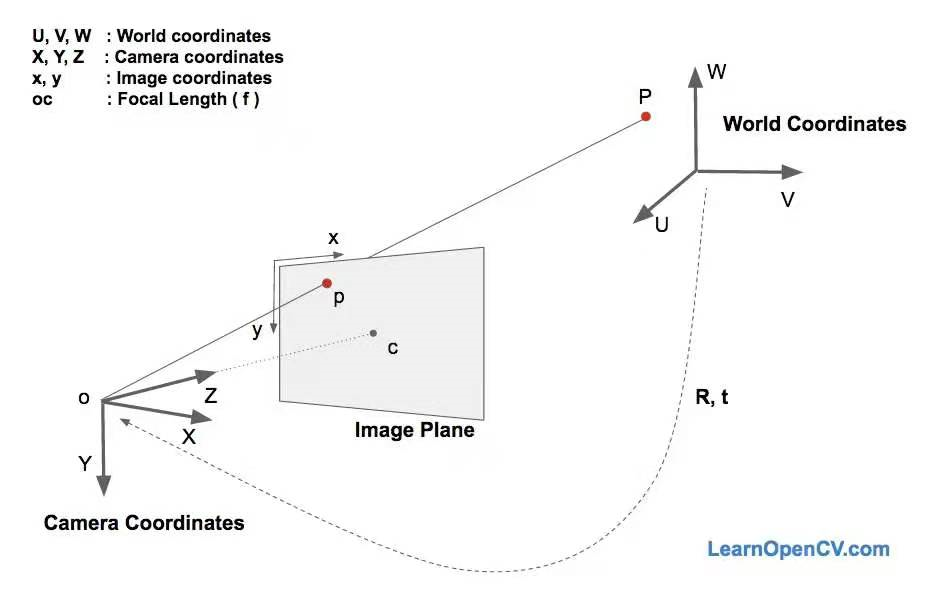
这里有三个坐标系。上述各种面部特征的三维坐标如下所示世界坐标。如果我们知道旋转和平移(即姿态),我们就可以将世界坐标中的3d点转换为相机坐标。相机坐标中的三维点可以投影到图像平面上。图像坐标系)利用摄像机的本征参数(焦距、光学中心等)。
由于一些原因,DLT解决方案不太准确。第一,旋转有三个自由度,但DLT解中使用的矩阵表示有9个数字。DLT解中没有任何东西强迫估计的3×3矩阵为旋转矩阵。更重要的是,DLT解决方案不会最小化正确的目标函数。理想情况下,我们希望将重投影误差如下所述。
如方程式所示2和3,如果我们知道正确的姿势(和)通过将三维点投影到二维图像上,可以预测三维人脸点在图像上的二维位置。换句话说,如果我们知道和我们能找到重点在图像中每一个3D点.
我们还知道二维面部特征点(使用dlib或手动单击)。我们可以观察投影三维点和二维面部特征之间的距离。当估计的姿态完美时,投影到图像平面上的三维点几乎与二维人脸特征一致。当姿态估计不正确时,我们可以计算出再投影误差测量-投影三维点和二维面部特征点之间的平方距离之和。
如前所述,对姿势的大致估计(R和t)可以使用DLT解决方案找到。改进DLT解决方案是随机改变姿势(R和t)并检查重投影误差是否减小。如果是的话,我们可以接受新的姿态估计。
在OpenCV中解决PnP和SolvePnPRansac可以用来估计姿势。
解决PnP实现了几种可以使用参数选择的姿态估计算法。SOLVEPNP迭代它本质上是DLT解,其次是Levenberg-Marquardt优化。SOLVEPNP_P3P只使用一部分内容来计算姿势,只在使用时才调用。
在OpenCV 3中,引入了两种新方法-SOLVEPNP_DLS和SOLVEPNP_UPnP。有趣的是SOLVEPNP_UPnP它也试图估计摄像机的内部参数。
SolvePnPRansac非常类似于解决PnP只是它用随机样本一致性(RANSAC)来准确地估计姿势。
当我们怀疑一些数据噪声比较大时,使用RANSAC是非常有用的。例如,考虑将一条线拟合到2D点的问题。这个问题可以用线性最小二乘法来解决,其中所有点离拟合线的距离都是最小的。现在来考虑一个糟糕的数据点,这个数据点离我们很远。这一个数据点可以控制最小二乘解,我们对这条线的估计是非常错误的。在RANSAC中,参数是通过随机选择所需的最小点数来估计的。在一个直线拟合问题中,我们从所有数据中随机选取两个点,并找到通过它们的直线。其他距离这条线足够近的数据点被称为“不动点”(Inliers)。通过随机选取两点得到直线的多个估计值,并选取最大误差数的直线作为正确的估计。
使用SolvePnPRansac的参数如下所示。SolvePnPRansac都被解释了。
C++*无效SolvePnPRansac(InputArray ObjectPoint,InputArray ImagePoint,InputArray CameraMatrix,InputArray disCoeffs,OutputArray rvec,OutputArray TVEC,bool useExtrinsicGuess=false,int iterationsCount=100,浮动重投影Error=8.0,int minInliersCount=100,OutputArray inliers=noArray(),int标志=迭代)
Python:cv2.solvePnPRansac(ObjectPoint,ImagePoint,CameraMatrix,distCoeffs[,rvec[,tvc[,useExtrinsicGuess[,iterationsCount[,reprojectionError[,minInliersCount[,Inliers[,标志])→rvec,tvc,inliers
迭代计数-挑选最低点数的次数和估计参数。重投射错误-正如前面在RANSAC中提到的,预测足够接近的点称为“不稳定点”。这个参数值是观测到的点投影和计算的点投影之间的最大允许距离,从而认为它是一个独立点。
MinInliersCount-不稳定因素的数目。如果算法在某个阶段发现了比minInliersCount更多的inliersCount,它就完成了。衬垫-输出向量,其中包含ObtPoint和ImagePoint中的inliers索引。
OpenCV习惯于一种名为POSIT的姿态估计算法。它仍然存在于C API中(CvPosit),但不是C++API的一部分。PREST假设一个缩放的正射相机模型,因此你不需要提供焦距估计。这个函数现在已经过时了,我们建议使用SolvePnp。我们提供了源程序代码,感兴趣的小伙伴们可以尝试一下。
using namespace std;using namespace cv;int main(int argc, char **argv){// Read input imagecv::Mat im = cv::imread("headPose.jpg");// 2D image points. If you change the image, you need to change vectorstd::vector<cv::Point2d> image_points;image_points.push_back( cv::Point2d(359, 391) ); // Nose tipimage_points.push_back( cv::Point2d(399, 561) ); // Chinimage_points.push_back( cv::Point2d(337, 297) ); // Left eye left cornerimage_points.push_back( cv::Point2d(513, 301) ); // Right eye right cornerimage_points.push_back( cv::Point2d(345, 465) ); // Left Mouth cornerimage_points.push_back( cv::Point2d(453, 469) ); // Right mouth corner// 3D model points.std::vector<cv::Point3d> model_points;model_points.push_back(cv::Point3d(0.0f, 0.0f, 0.0f)); // Nose tipmodel_points.push_back(cv::Point3d(0.0f, -330.0f, -65.0f)); // Chinmodel_points.push_back(cv::Point3d(-225.0f, 170.0f, -135.0f)); // Left eye left cornermodel_points.push_back(cv::Point3d(225.0f, 170.0f, -135.0f)); // Right eye right cornermodel_points.push_back(cv::Point3d(-150.0f, -150.0f, -125.0f)); // Left Mouth cornermodel_points.push_back(cv::Point3d(150.0f, -150.0f, -125.0f)); // Right mouth corner// Camera internalsdouble focal_length = im.cols; // Approximate focal length.Point2d center = cv::Point2d(im.cols/2,im.rows/2);cv::Mat camera_matrix = (cv::Mat_<double>(3,3) << focal_length, 0, center.x, 0 , focal_length, center.y, 0, 0, 1);cv::Mat dist_coeffs = cv::Mat::zeros(4,1,cv::DataType<double>::type); // Assuming no lens distortioncout << "Camera Matrix " << endl << camera_matrix << endl ;// Output rotation and translationcv::Mat rotation_vector; // Rotation in axis-angle formcv::Mat translation_vector;// Solve for posecv::solvePnP(model_points, image_points, camera_matrix, dist_coeffs, rotation_vector, translation_vector);// Project a 3D point (0, 0, 1000.0) onto the image plane.// We use this to draw a line sticking out of the nosevector<Point3d> nose_end_point3D;vector<Point2d> nose_end_point2D;nose_end_point3D.push_back(Point3d(0,0,1000.0));projectPoints(nose_end_point3D, rotation_vector, translation_vector, camera_matrix, dist_coeffs, nose_end_point2D);for(int i=0; i < image_points.size(); i++){circle(im, image_points[i], 3, Scalar(0,0,255), -1);}cv::line(im,image_points[0], nose_end_point2D[0], cv::Scalar(255,0,0), 2);cout << "Rotation Vector " << endl << rotation_vector << endl;cout << "Translation Vector" << endl << translation_vector << endl;cout << nose_end_point2D << endl;// Display image.cv::imshow("Output", im);cv::waitKey(0);}
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~