
最佳实践:构建新一代智能、可靠、可调度的大型骨干网络(下)
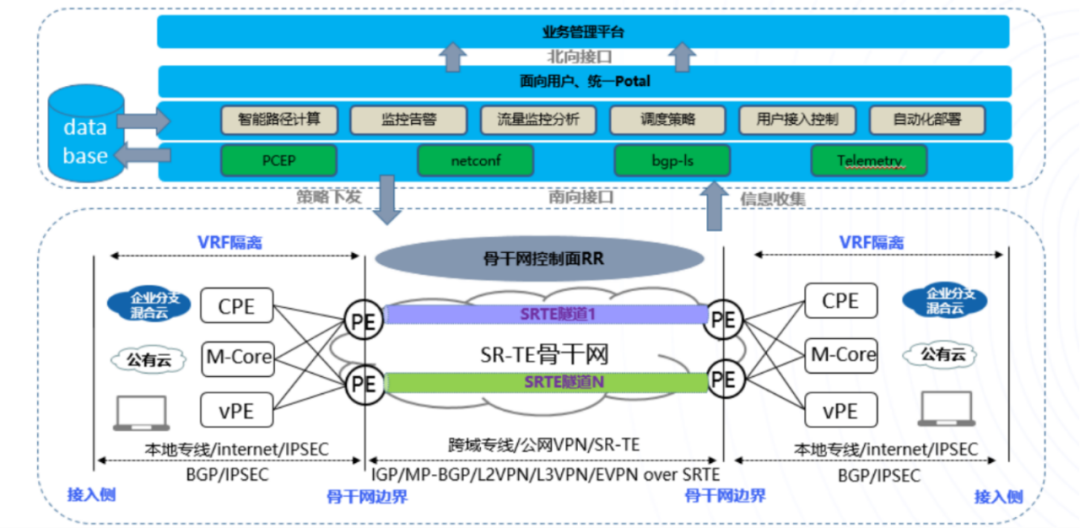
控制器智能计算路径和头端自动计算路径:控制器实时收集转发设备状态信息,响应转发节点路径计算请求和路径下发。 全场景接入,实现灵活组网:支持用户本地专线、互联网线路混合接入方式,实现用户灵活组网。 多维度SLA路径规划:满足多业务不同路径转发需求,确保关键业务的优先级和服务质量。 降低专线成本,提高整体专线利用率:废除骨干网2.0中的VXLAN技术,缩减包头开销,降低专线成本;通过智能流量调度合理规划专线容量。 流量可视化,按需调度:通过telemetry和netflow技术实现骨干网流量可视化,针对部分“热点流量”和“噪声流量”进行按需调度。
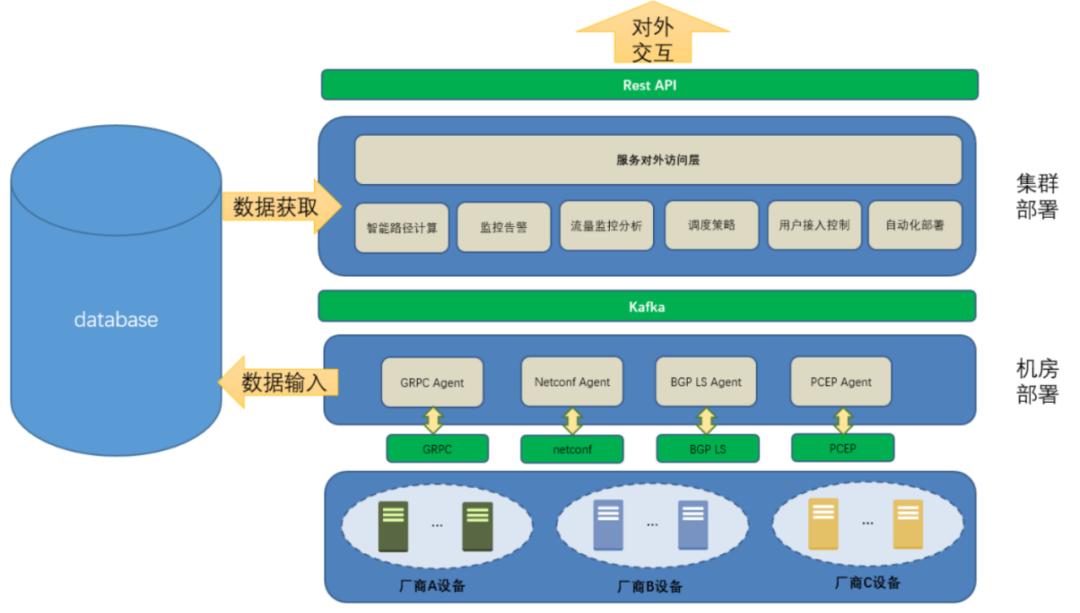
基本的IGP拓扑信息(节点、链路、IGP度量值) BGP EPE(Egress peer Engineering)信息 SR信息(SRGB、Prefix-SID、Adj-SID、Anycast-SID等) TE链路属性(TE度量、链路延迟度量、颜色亲和属性等) SR Policy信息(头端、端点、颜色、Segment列表、BSID等)
头端向控制器请求路径计算;控制器针对收到路径计算请求进行路径计算 头端从控制器学到路径,控制器通过PCEP向头端传递路径信息 头端向控制器报告其本地的SR Policy
快速的故障响应:由于内部自定义的算法需求,在线路或者节点出现问题时,需要重新计算整张拓扑,以避开故障链路; 快速实现手动故障域隔离:借助架构的优势,实现所有流量在线路级别与节点级别的隔离; 快速自定义调优路径:可以根据客户的需求快速将客户流量引导到任意路径上,保证客户各类路径需求; 客户流量秒级实时监控:可监控流级别的客户故障,并实现故障情况下的路径保护;
首先需要在MPLS VPN Backbone内采用一个IGP(IS-IS)来打通核心骨干网络的内部路由; PE上创建VRF实例,与不同的VRF客户对接,VPN实例关联RD及RT值,并且将相应的端口添加到对应的VRF实例; PE上基于VRF实例运行PE-CPE&VPE、M-Core间的路由协议,从CPE&VPE、M-Core学习到站点内的VRF路由; PE与RR之间,建立MP-IBGP连接,PE将自己从CE处学习到的路由导入到MP-IBGP形成VPNv4的前缀并传递给对端PE,并且也将对端PE发送过来的VPNv4前缀导入到本地相应的VRF实例中; 为了让数据能够穿越MPLS VPN Backbone,所有的核心PE激活MPLS及SR功能。

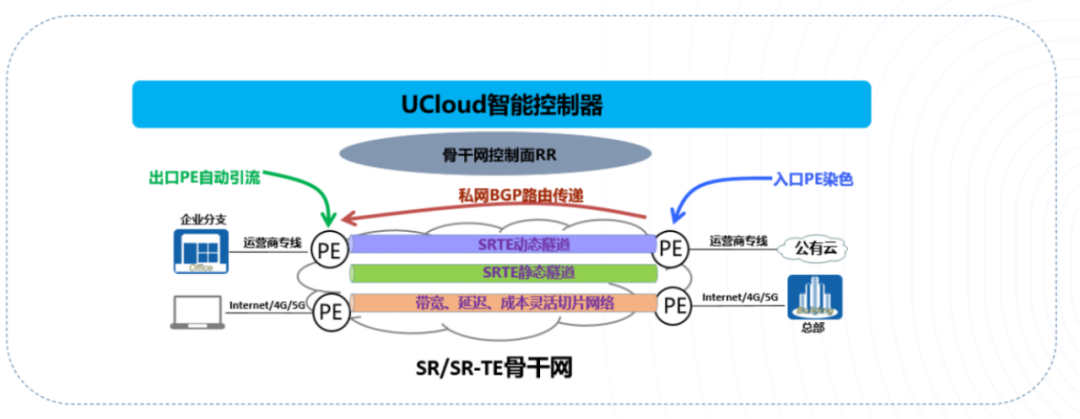
控制器统一编排业务场景:
头端自动算路和自动引流:
基于业务场景对网络灵活切片:

毫秒级拓扑收敛、链路重算、路径下发:线路故障场景下控制器可以做到毫秒级的拓扑收敛、故障链路重算以及备份路径下发; 流级别路径展示:实现基于数据流级别的路径查询和展示。
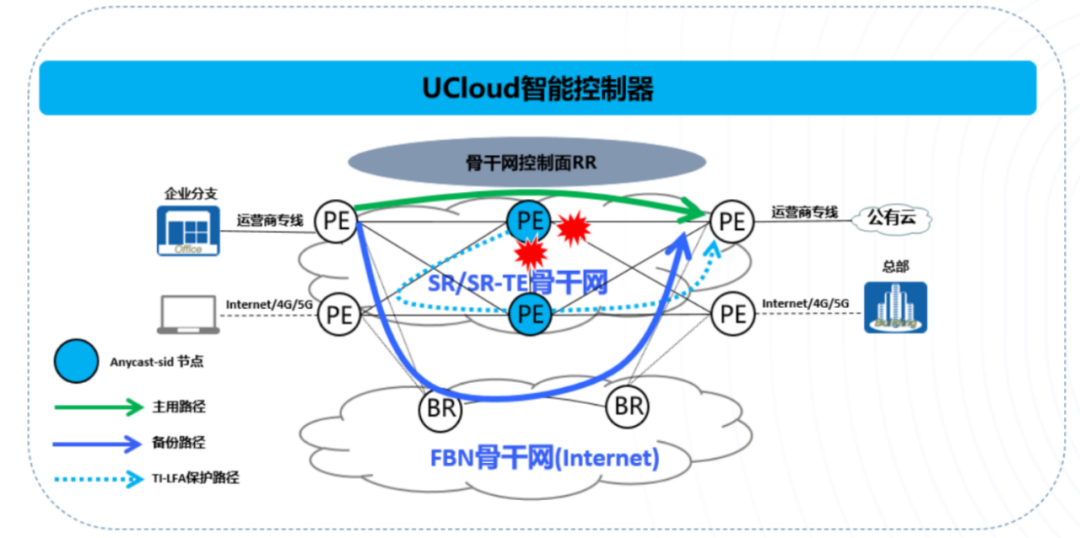
全球核心节点专线组网:节点之间提供运营商级的专线资源,SLA可达99.99%; 双PE节点 Anycast-SID保护:地域级的双PE配置Anycast-SID标签,实现路径的ECMP和快速容灾收敛; Ti-LFA无环路径保护:100%覆盖故障场景,50ms内完成备份路径切换; SR-TE主备路径保护:SR-TE路径中规划主备Segment-List,实现路径转发高可用; SR-TE路径快速逃生:SR-TE故障场景下可以一键切换到SR-BE转发路径(IGP最短路径转发); Internet级骨干网备份:为了保障新一代骨干网的高可靠性,在每个地域的PE设备旁路上两台公网路由器,规划了一张1:1的Internet骨干网,当某地域专线故障时可以自动切换到Internet线路上;同时使用Flex-Algo技术基于Internet级骨干网规划出一张公网转发平面用于日常管理流量引流。
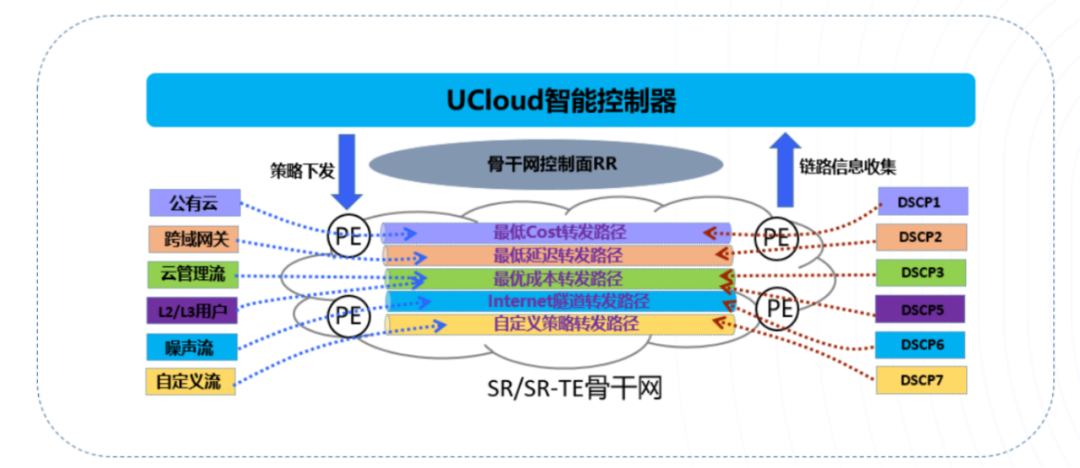
根据五元组,识别并定义应用,支持Per-destination、Per-Flow调度; 跨域之间根据应用业务分类定义多条不同类型SR-TE隧道; 每种类型隧道定义主备路径,支持SR-TE一键逃生; 通过灵活算法定义Delay、带宽、TCO(链路成本)、公网隧道等多种网络切片平面; 智能控制器支持自动下发、自动计算、自动调整、自动引流和自动调度。
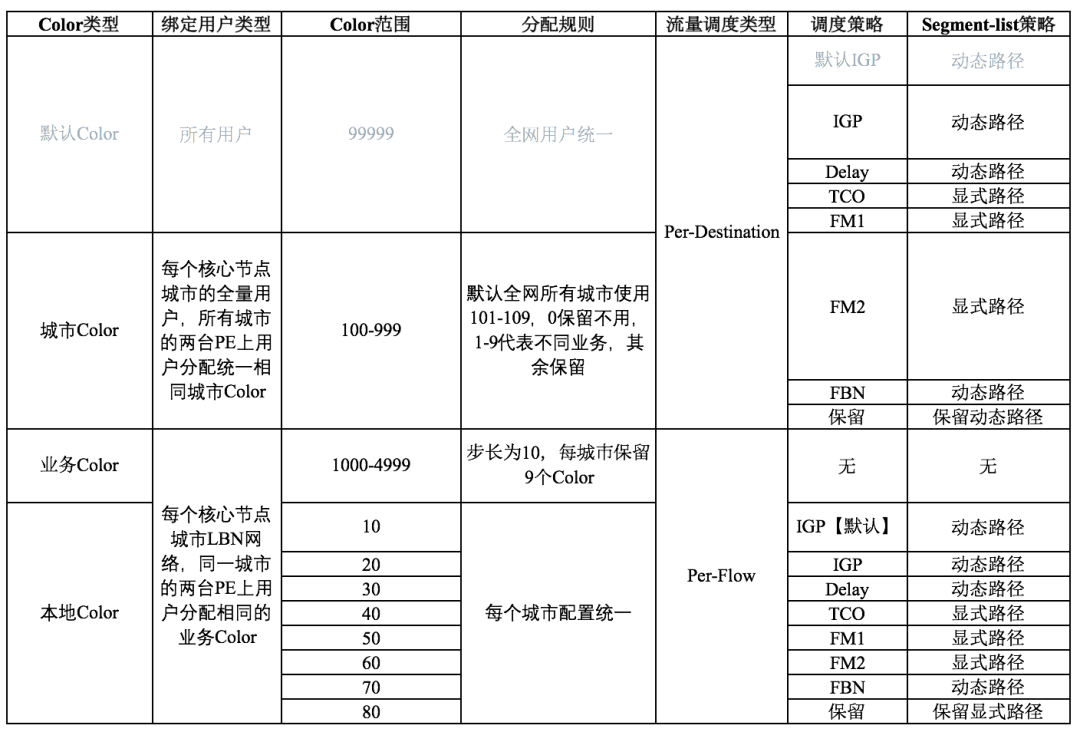
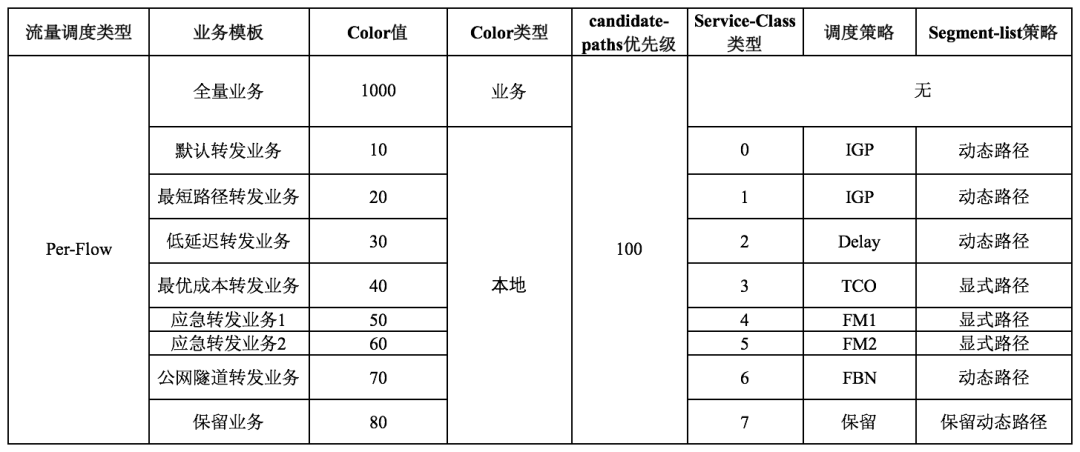
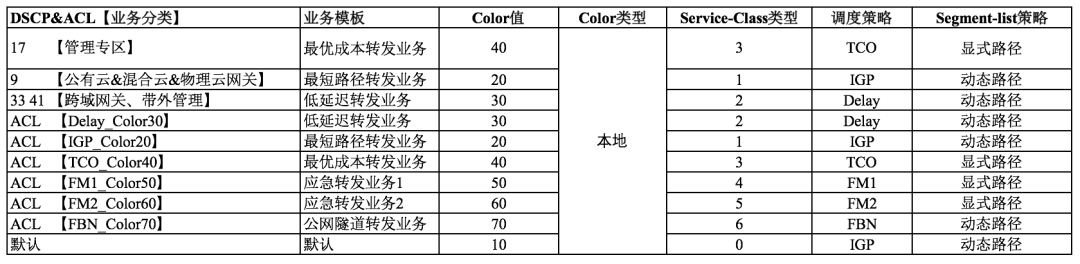
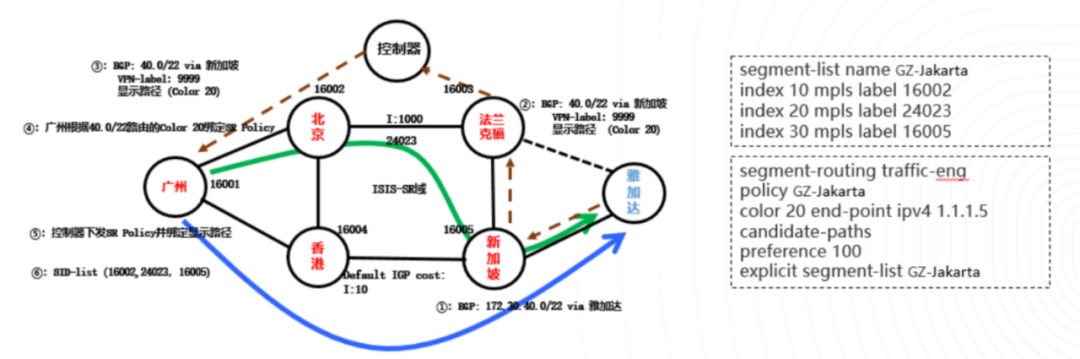
业务流量背景
调度前流量模型
传统流量调度方案
传统调度存在问题
SR-TE流量调度方案
SR-TE流量调度优势
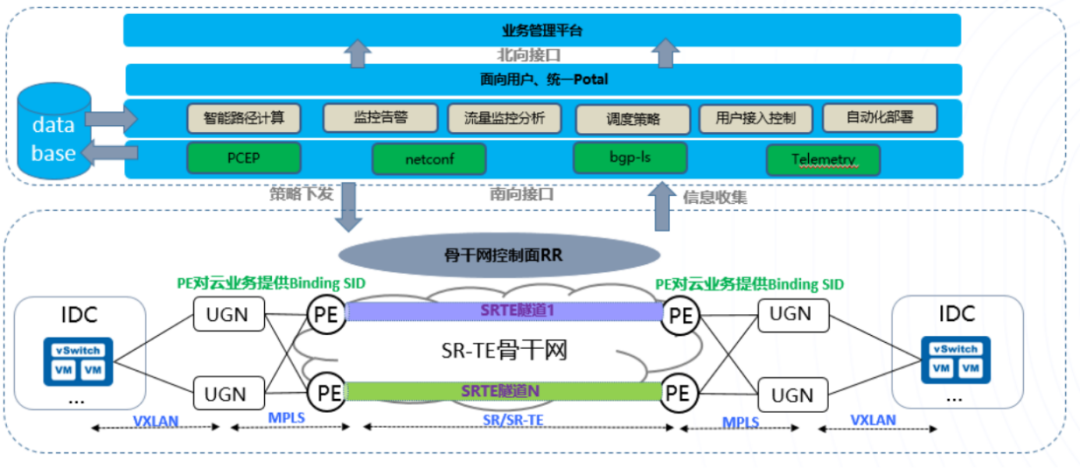
骨干网为每个城市的端到端SR-TE隧道分配一个Binding SID,用于数据中心云租户引流; 数据中心宿主机通过VXLAN将租户流量送到骨干网UGN(公有云跨域网关); UGN解封装VXLAN报文后,封装MPLS标签,内层标签用于区分租户,外层标签用于封装远端城市的Binding SID标签; PE设备收到带有目标城市的Binding SID后,自动引流进对应的SR-TE隧道进行转发; 对端PE收到报文后解封外层MPLS报文,然后转发给UGN,UGN根据内层标签和VXLAN的VNI的映射关系进行转换,最终通过IP转发至DCN的宿主机上。


评论