
聊聊 yarn 的三种资源调度器和公平调度器的最佳配置实践
一。YARN 的三种资源调度器概述
Hadoop 的 资源管理框架 yarn 是支持可插拔的资源调度器的。目前内置支持的调度器有三个,即 fifo, capacity 和 fair 调度器三个,如下图所示:

简单对比下三种调度器:
FIFO - Allocates resources based on arrival time. 在当前强调多租户和资源利用率的大环境下,几乎已经没有集群采用 fifo调度器了;
Fair - Allocates resources to weighted pools, with fair sharing within each pool. When configuring the scheduling policy of a pool, Domain Resource Fairness (DRF) is a type of fair scheduler;Cloudera 在 cdh 中推荐使用的即是该 Fair 调度器。(不过在 cloudera 的 cdp中,目前官方推荐且唯一支持的却是 capacity 调度器)
Capacity - Allocates resources to pools, with FIFO scheduling within each pool. hadoop yarn 默认配置的调度器即是该 Capacity调度器 ;星环的 Tdh 中默认配置的也是该 capacity scheduler.
可以看到,Fair 和 Capacity 调度器的核心理念是类似的:
两个调度器都是把整个集群资源划分到若干个资源池 pool 中,而应用是提交到具体的资源池中并从中申请资源的,两个调取器都是基于这种机制,来做资源的隔离进而满足各种 sla 需求;
两个调度器的 pool 都是支持层次 即 Hierarchical 的;
两个调度器,都支持多租户;
两个调度器,都支持提交应用时指定具体的资源池;
当应用没有指定具体的资源池时,两个调度器都可以根据配置的规则,根据应用提交者的身份,决定实际使用的是哪个;
两个调度器,都支持根据应用提交者的身份,动态创建资源池;
两个调度器的对比如下:
两个调度器的核心区别,在于提交到一个具体的资源池中的所有任务,是采用 fair 公平调度还是 fifo 先进先出的调度;
fair 公平调度器,综合考量了提交到 pool 中的各种大小任务的差异,能避免因长时间运行的大任务占用了大量集群资源,造成小任务长时间得不到资源无法执行,影响用户体验;
Capacity 调度器,初看似乎没有像 fair 公平调取器那样,综合考量提交到 pool 中的任务大小的差异,但细想之下,管理员可以对大小任务/批流任务创建不同的 pool,由任务提交者根据任务的特点,提交到不同的 pool 中,一样能达到和 fair 调度器一样的效果和用户体验;
Capacity 调度器,配置更为简单,可能是因为这种原因,cloudera 的 cdp 中目前推荐且唯一支持的是 Capacity 调度器;
由于当前大部分客户使用的都是 cloudera 的 cdh 集群推荐的 Fair 调度器,所以这里我们重点看下该公平调度器。
二。一次 yarn 队列问题概述
某客户反馈,他们的cdh集群中“提交任务无法进入指定的资源池队列执行”,如下图所示:

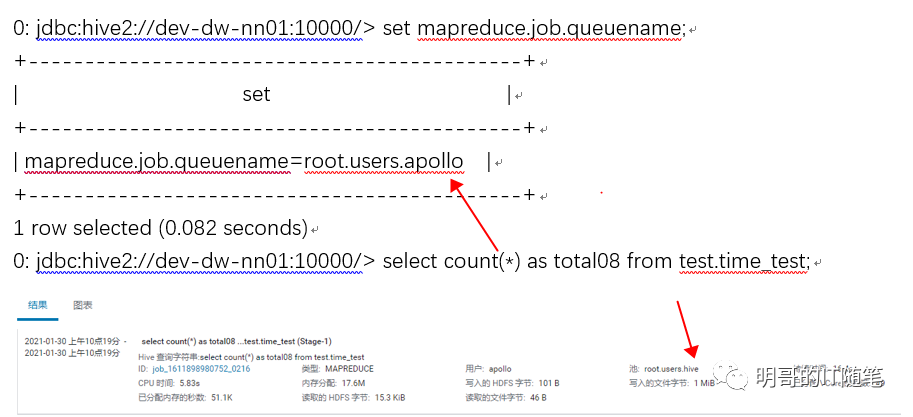
三。上述yarn 队列问题原因分析与解决
排查问题,首先查看用户配置使用的调度器是 fair scheduler:

然后查看资源池 resource pools配置:
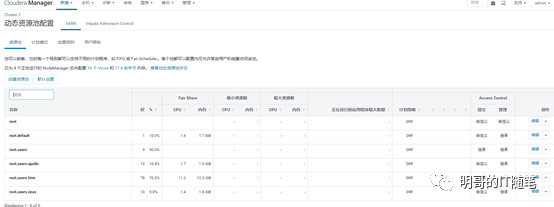
接下来查看具体的放置规则 placement rules:
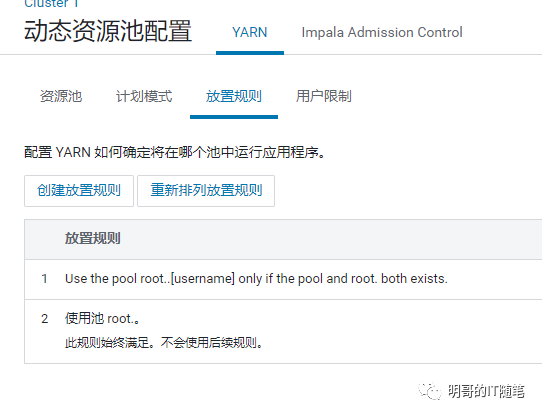
再看各个资源池具体的配置,尤其是提交访问控制:
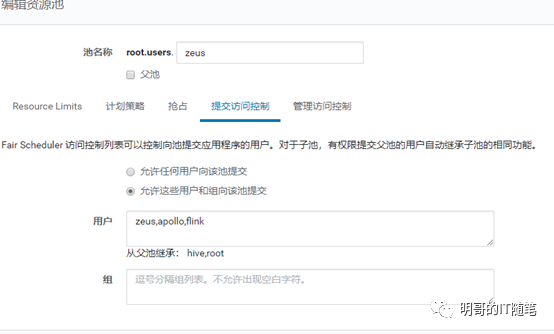
熟悉 yarn 调度器的细心读者,看到这里有的已经发现问题所在了:在placementrules 放置规则中,管理员没有配置“specified at runtime”即“运行时指定资源池”!
在修改 palcement rules,添加了“specified at runtime”后,作业可以提交到指定的队列,截图如下:
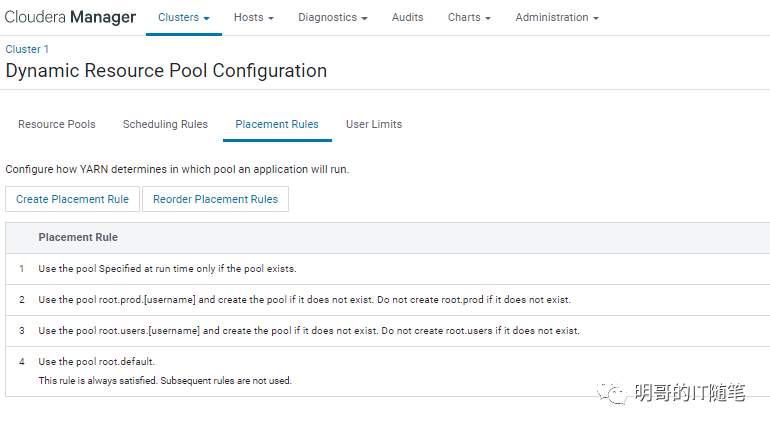

四。背景知识:Fair 调度器支持的多种 placement rules
事实上,公平调度器支持了丰富的 placement rules:

"specified at run time" placement rules 配置细节:

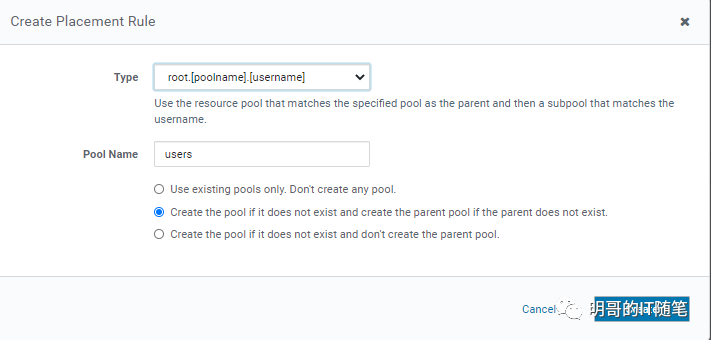
"root.poolname.username" placement rules 配置细节:
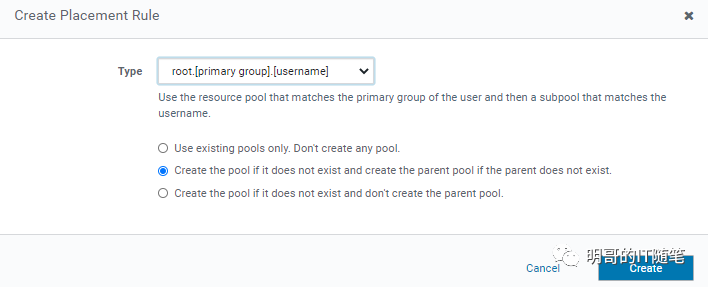
"root.primary-group.username" placement rules 配置细节:
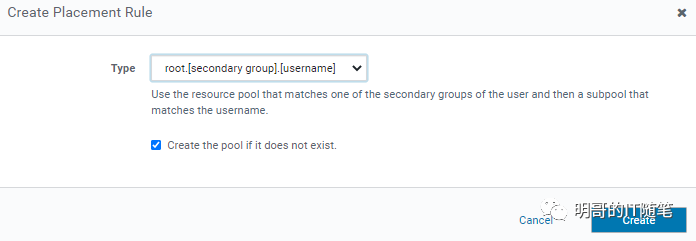
"root.secondary-group.username" placement rules 配置细节:
"root.username" placement rules 配置细节:
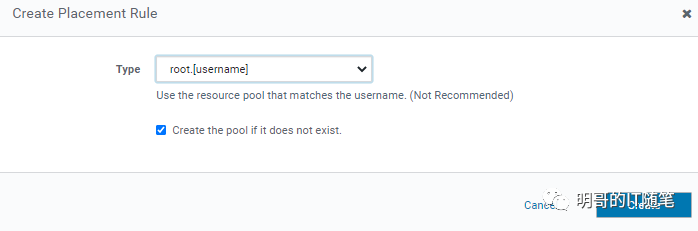
fair 公平调度器支持的以上多种放置策略,大体可以分为以下几大类:
用户提交作业时指定 pool;
使用集群管理员配置的指定 pool;
根据用户名动态判断 pool;
根据用户的 primary group 动态判断 pool;
根据用户的 secondary group 动态判断 pool;
其中大多数都支持选项 “Create the pool if it does not exis”,即对应的子池不存在时动态创建。
五。笔者推荐的Fair 调度器的最佳配置实践
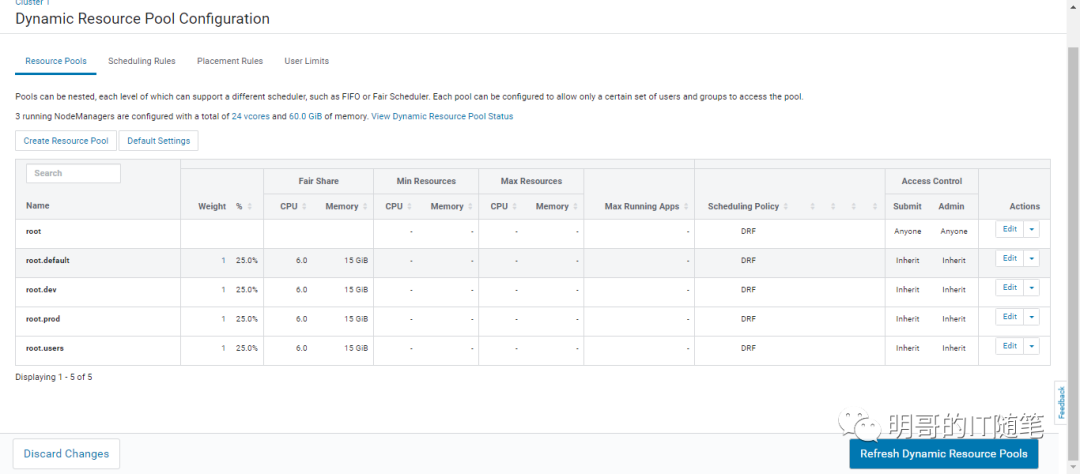
笔者建议,Fair 调度器配置以下resource pools (注意:root.dev, root.prod 等资源队列可以根据实际情况配置多个):
配合以下placement rules: (注意:规则生效的优先级跟以下配置项的顺序有关,我们这里故意配置优先使用用户指定的队列。)

每个资源池,再根据情况,配置 resouce limits, scheduling policy, preemption, submission accsscontrol, administration access control(注意:这里的提交访问控制submissionaccss control需要根据实际情况配置,很重要!)
以上资源池 resouce pools,放置规则 placemnt rules, 和每个资源池具体的配置尤其是提交访问控制submission accss control的配置,兼顾了配置的灵活性和易用性,也兼顾了集群资源管控的严谨性:
第一条 placement rules 确保了,如果用户提交作业时指定了队列,则优先使用该队列,且如果该队列不存在,不会动态创建,集群管理员需要事先规划,创建好各个应用系统需要的队列;
第二条和第三条 placement rules 确保了,如果用户没有指定作业使用的队列,yarn 会根据每个池子的 acl 和提交作用的用户名,决定对应的最终队列名,如 root.prod.username 或 root.dev.username 或 root.users.username 等 (事实上,多租户多系统的平台,可能会根据租户和具体的 sla,建多个父池:root.promtion, root.dev, root.prd 等等)。此时即限制了作业资源上限(是父池的子池),也能通过资源池子池的名字看出来是哪个用户的作业;
以上第二条和第三条 placement rules,我们指定了不能自动动态创建父池,只能根据用户名自动创建指定的父池下的子池,这点是出于严谨的考量,集群管理员需要事先规划,创建好各个应用系统需要的队列;
以上第四条 placement rules 是拖底方案,确保以上条件都不满足时, 作业也有对应的资源队列去申请资源。
使用以上笔者推荐的公平调度器的最佳配置实践,还需要配合上应用上线前代码的 review (重点关注提交作业用户的身份,和代码中是否指定了具体的资源队列),和集群定期的 audit (重点关注都运行了哪些类型的作业,是什么用户提交的,运行在哪些资源池中),整个集群就会处于一种可控且灵活的资源管控下,很好地满足 sla, 服务于各个业务部门啦!
需要说明的是,以上是以 cloudera cdh 为例,演示了如何通过界面化方式进行具体配置,在其他大数据平台如 星环的 tdh中,界面化配置方式入口略有不同,大家也可以直接编辑底层的配置文件fair-scheduler.xml.
参考资料:
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇