
C#网络编程的最佳实践
转自:egmkang
cnblogs.com/egmkang/p/13637768.html
网络框架的选择
C++语言里面有asio和libuv等网络库, 可以方便的进行各种高效编程. 但是C#里面, 情况不太一样, C#自带的网络API有多种. 例如:
Socket
TcpStream(同步接口和BeginXXX异步接口)
TcpStream Async/Await
Pipeline IO
ASP.NET Core Bedrock
众多网络库, 但是每个编程模型都不太一样, 和C++里面我常用的reactor模型有很大区别. 最重要的是, 编程难度和性能不是很好. 尤其是后面三种模型, 都是面对轻负载的互联网应用设计, 每个玩家跑两个协程(一读一写)会对进程造成额外的负担.
Golang面世的时候, 大家都说协程好用, 简单, 性能高. 可是面对大量 高频交互的应用, 最终还是需要重新编写网络层(参见Gnet).
因为协程上下文切换需要消耗微秒左右的时间(通常是0.5us到1微秒左右), 另外有栈协程占用额外的内存(无栈协程不存在这个问题).
所以在C#里面需要选择一个类似于Reactor模型的网络库. Java里面有Netty. 好在微软把Netty移植到了.NET里面, 所以我们只需要照着Netty的文档和DotNetty的Sample(包括源码)就可以写出高效的网络框架.
另外DotNetty有libuv的插件, 可以将传输层放到libuv内, 减少托管语言的消耗.
DotNetty编程
由于我们是服务器编程, 需要处理多个Socket而不像客户端只需要处理一两个Socket, 所以在每个Socket上, 都需要做一些标记信息, 用来标记当前Socket的状态(是否登录, 用户是哪个等等); 还需要一个管理维护的这些Socket的管理者类.
链接状态
Socket的状态可以使用IChannel.GetAttribute来实现, 我们可以给IChannel上面增加一个SessionInfo的属性, 用来保存当前链接的其他可变属性. 那么可以这么做:
public class SessionInfo
{
//SessionID不可变
private readonly long sessionID;
public SessionInfo(long sessionID)
{
this.sessionID = sessionID;
}
//其他属性
}
static readonly AttributeKey<ConnectionSessionInfo> SESSION_INFO = AttributeKey<ConnectionSessionInfo>.ValueOf("SessionInfo");
//新链接
bootstrap.ChildHandler(new ActionChannelInitializer<IChannel>(channel =>
{
var sessionInfo = new SessionInfo(++seed);
channel.GetAttribute(SESSION_INFO).Set(sessionInfo);
//其他参数
}));
由于游戏服务器通常是有状态服务, 所以链接上还需要保存PlayerID, OpenID等信息, 方便解码器在解码的时候, 直接把消息派发给相应的处理器.
管理器和生命周期
托管语言有GC, 但是对于非托管资源还是需要手动管理. C#有IDisposable模式, 可以简化异常场景下资源释放问题, 但是对于Socket这种生命周期比较长的资源就无能为力了.
所以, 我们必须要编写自己的ChannelManager类, 并且遵从:
新链接一定要立刻放到Manager里面
通过ID来获取IChannel, 不做长时间持有
想要长时间持有, 则使用WeakReference
MessageHandler的异常里面释放Manager里面的IChannel
心跳超时也要释放IChannel
对于IChannel对象的持有, 一定要是短时间的持有, 比如在一次函数调用内获取, 否则问题会变得很复杂.
防止主动关闭Socket和异常同时发生, IChannel.CloseAsync()函数调用需要try catch.
参数调节
GameServer一般来讲单个网络线程就够了, 但是作为网关是绝对不够的, 所以网络库需要支持多线程Loop. 好在DotNetty这方面比较简单, 只需要构造的时候改一下参数, 具体可以看看Sample, 托管和Libuv的传输层构造不一样.
var bootstrap = new ServerBootstrap();
//1个boss线程, N个工作线程
bootstrap.Group(this.bossGroup, this.workerGroup);
if (RuntimeInformation.IsOSPlatform(OSPlatform.Linux)
|| RuntimeInformation.IsOSPlatform(OSPlatform.OSX))
{
//Linux下需要重用端口, 否则服务器立马重启会端口占用
bootstrap
.Option(ChannelOption.SoReuseport, true)
.ChildOption(ChannelOption.SoReuseaddr, true);
}
bootstrap
.Channel<TcpServerChannel>()
//Linux默认backlog只有128, 并发较高的时候新链接会连不上来
.Option(ChannelOption.SoBacklog, 1024)
//跑满一个网络需要最少 带宽*延迟 的滑动窗口
//移动网络延迟比较高, 建议设置成64KB以上
//如果是内网通讯, 建议设置成128KB以上
.Option(ChannelOption.SoRcvbuf, 128 * 1024)
.Option(ChannelOption.SoSndbuf, 128 * 1024)
//将默认的内存分配器改成 内存池版本的分配器
//会占用较多的内存, 但是GC负担比较小
//一个堆16M, 会占用多个堆
.Option(ChannelOption.Allocator, PooledByteBufferAllocator.Default)
.ChildOption(ChannelOption.TcpNodelay, true)
.ChildOption(ChannelOption.SoKeepalive, true)
//开启高低水位
.ChildOption(ChannelOption.WriteBufferLowWaterMark, 64 * 1024)
.ChildOption(ChannelOption.WriteBufferHighWaterMark, 128 * 1024)
.ChildHandler(new ActionChannelInitializer<IChannel>(channel =>
{
这里强调一下高低水位. 如果往一个Socket不停的发消息, 但是对端接收很慢, 那么正确的做法就是要把他T掉, 否则一直发下去, 服务器可能会内存不足. 这部分内存是无法GC的, 处理不当可能会被攻击.
编解码器和ByteBuffer的使用
DotNetty有封装好的IByteBuffer类, 该类是一个Stream, 支持Mark/Reset/Read/Write. 和Netty不太一样的是ByteBuffer类没有大小端, 而是在接口上做了大小端处理.
对于一个解码器, 大致的样式是:
public static (int length, uint msgID, IByteBuffer bytes) DecodeOneMessage(IByteBuffer buffer)
{
if (buffer.ReadableBytes < MinPacketLength)
{
return (0, 0, null);
}
buffer.MarkReaderIndex();
//这只是示例代码, 实际需要根据具体情况调整
var head = buffer.ReadUnsignedIntLE();
var msgID = buffer.ReadUnsignedIntLE();
var bodyLength = head & 0xFFFFFF;
if (buffer.ReadableBytes < bodyLength)
{
buffer.ResetReaderIndex();
return (0, 0, null);
}
var bodyBytes = buffer.Allocator.Buffer(bodyLength);
buffer.ReadBytes(bodyBytes, bodyLength);
return (bodyLength + 4 + 4, msgID, bodyBytes);
}
真实情况肯定要比这个复杂, 这里只是一个简单的sample. 读取消息因为需要考虑半包的存在, 所以需要ResetReaderIndex, 在编码的时候就不存在这个情况.
编码的情况就要稍微简单一些, 因为解码可能包不完整, 但是编码不会出现半个消息的情况, 所以在编码初期就能知道整个消息的大小(也有部分序列化类型会不知道消息长度).
var allocator = PooledByteBufferAllocator.Default;
var buffer = allocator.Buffer(Length);
buffer.WriteIntLE(Header);
buffer.WriteIntLE(MsgID);
//xxx这边写body
用ByteBuffer编码Protobuf
之所以这边要单独提出来, 是因为高性能的服务器编程, 需要榨干一些能榨干的东西(在力所能及的范围内).
很多人做Protobuf IMessage序列化的时候, 就是简单的一句msg.ToByteArray(). 如果服务器是轻负载服务器, 那么这么写一点问题都没有; 否则就会多产生一个byte[]数组对象. 这显然不是我们想要的.
对于编码器来讲, 我们肯定是希望我给定一个预定的byte[], 你序列化的时候往这里面写. 所以我们来研究一下Protobuf的消息序列化.
//反编译的代码
public static Byte[] ToByteArray(this IMessage message)
{
ProtoPreconditions.CheckNotNull(message, "message");
CodedOutputStream codedOutputStream = new CodedOutputStream(new Byte[message.CalculateSize()]);
message.WriteTo(codedOutputStream);
return (Byte[])codedOutputStream.CheckNoSpaceLeft();
}
通过代码分析可以看出内部在使用CodedOutputStream做编码, 但是这个类的构造函数, 没有支持Slice的重载. 通过dnSpy反汇编发现有一个私有的重载:
private CodedOutputStream(byte[] buffer, int offset, int length)
{
this.output = null;
this.buffer = buffer;
this.position = offset;
this.limit = offset + length;
this.leaveOpen = true;
}
这就是我们所需要的接口, 有了这个接口就可以在ByteBuffer上面先申请好内存, 然后在写到ByteBuffer上, 减少了一次拷贝和内存申请操作, 主要是对GC的压力会减轻不少.
这边给出示意代码:
var messageLength = msg.CalculateSize();
var buffer = allocator.Buffer(messageLength);
ArraySegment<byte> data = buffer.GetIoBuffer(buffer.WriterIndex, messageLength);
//这边需要通过反射去调用CodedOutputStream对象的私有构造函数
//具体可以研究一下
using var stream = createCodedOutputStream(data.Array, data.Offset, messageLength);
msg.WriteTo(stream);
stream.Flush();
至此, 我们就实现了高效的编码和解码器.
网络小包的处理
小包处理的一般思路不外乎合批, 合批压缩. 后者实现的难度要稍微高一点. 主要是游戏的流量还没有高到每一帧都会发送超过几百字节(小于128Byte的包压缩起来效果没那么好).
所以, 只有登录的时候, 服务器把玩家的几十K到上百K数据发送给客户端的时候, 压缩的时候才有效果; 平时只需要合批就可以了.
合批还能解决另外一个问题, 就是网卡PPS的瓶颈. 虽然是千兆网, 但是PPS一般都是在60W~100Wpps这个范围. 意味着一味的发小包, 一秒最多收发60W到100W个小包, 所以需要通过合批来突破PPS的瓶颈.
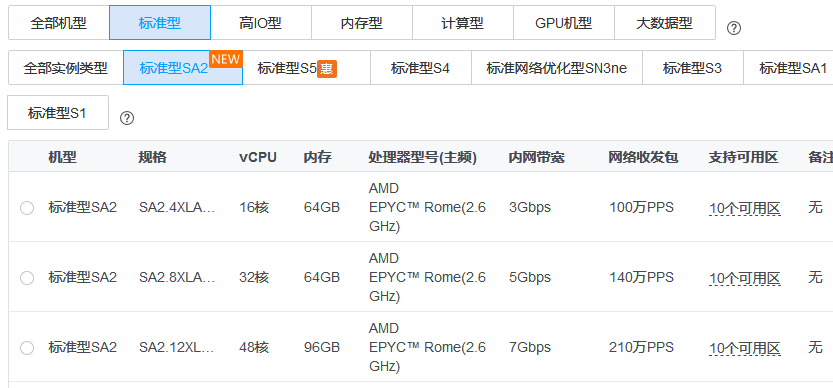
这是腾讯云SA2机型PPS的数据:
DotNetty中合批的两种实现方式. 先说第一种.
DotNetty发送消息有两个API:
WriteAsync
WriteAndFlushAsync 其中第一个API只是把ByteBuffer塞到Channel要发送的队列里面去, 第二个API塞到队列里面去还会触发真正的Send操作.
比如说我们要发送4个消息, 那么可以先:
//queue是一个List<IMessage>
for(int i = 0; i < queue.Count; ++i)
{
if ((i + 1) % 4 == 0)
{
channel.WriteAndAsync(queue[i]);
}
else
{
channel.WriteAsync(queue[i]);
}
}
channel.Flush();
然后我们研究DotNetty的源码, 发现他底层实现也是调用发送一个List的API, 那么就可以达到我们想要的效果.
还有一种方式, 就是把想要发送的消息攒一攒, 通过Allocter New一个更大的Buffer, 然后把这些消息全部塞进去, 再一次性发出去. 彩虹联萌服务器用的就是这种方式, 大概10ms主动发送一次.
DotNetty的缺点
与其说是DotNetty的缺点, 不如说是所有托管内存语言的缺点. 所有托语言申请和释放资源的开销是不固定的, 这是IO密集型应用面临的巨大挑战.
在C++/Rust带有RAII的语言里面, 申请一块Buffer和释放一块Buffer的消耗都是比较固定的. 比如New一块内存大概是25ns, Delete一块大概是30~50ns.
但是在托管内存语言里面, New一块内存大概25ns, Delete就不一定了. 因为你不能手动Delete, 只能靠GC来Delete. 但是GC释放资源的时候, 会有Stop. 不管是并行GC还是非并行GC, 只是Stop时间的长短.
只有消除GC之后, 程序才会跑得非常快, 和Benchmark Game内跑的一样快.
所以, 为了避免这个问题, 需要:
1、把IO和计算分开
这就是传统游戏服务器把Gateway和GameServer分开的好处. IO密集在Gateway, GC Stop对GameServer影响不大, 对玩家收发消息影响也不大.
2、把IO放到C++/Rust里面去
这不是奇思妙想, 是大家都这么做. 例如ASP.NET Core就用libuv当做传输层.
所以对于游戏服务器来讲, 可以在C++/Rust内实现传输层, 然后通过P/Invoke来和Native层通讯, 降低IO不断分配内存对计算部分的影响.
3、将程序改造成Alloc Free
如果我不分配对象, 就不会有GC, 也就不会对计算有影响. 这也是笔者才彩虹联萌服务器内做的事情.
Alloc Free是我自己造的词汇, 类似于Lock Free. 但是不是说不分配任何内存, 只是把高频分配降低了, 低频分配还是允许的, 否则代码会非常难写.
