
实操教程|YOLOv5实现自定义对象训练与OpenVINO部署全解析

极市导读
本文从数据准备、模型训练与模型转换部署三个部分详细介绍了如何使用YOLOv5训练自定义对象检测。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
大家好,前面写了一个OpenVINO部署YOLOv5推理的教程,收到很多反馈!这里就再写了一篇如何使用YOLOv5训练自定义对象检测,从数据准备到推理整个环节,帮助大家更好的使用YOLOv5来解决实际问题。整个文章主要分为三个部分,分别是数据准备与YOLO格式数据转换,模型训练与推理测试,模型转换为ONNX与部署。
数据下载与准备
数据下载我参考了别人提到一个Open Imag数据集的下载工具,github地址如下:
https://github.com/EscVM/OIDv4_ToolKit
用这个工具可以很方便的下载想要的数据,Open Image数据集包括包括100W+张图像,对象检测支持600个类别,所以很多图像都可以通过这个来下载,避免自己收集图像数据与标注数据的时间。所以首先需要执行
git clone https://github.com/EscVM/OIDv4_ToolKit
然后运行
pip3 install -r requirements.txt
安装好所有依赖,之后再下载数据集
python3 main.py downloader --classes Apple Orange --type_csv validation
意思是下载苹果跟橘子两个类别的图像标注数据。下载好的数据集文件夹结构如下:

分为三个文件夹,分别对应训练集、测试集、验证集。其中jpg文件是每个图像,labels里面的txt同名文件是每个图像中对象标注信息,格式如下:
name_of_the_class left top right bottomname_of_the_class 对象类别名称left top标注框左上角坐标right bottom 标注框右下角坐标
转换为YOLO标注格式数据,首先看一下标注文本文件与图像的文件夹结构
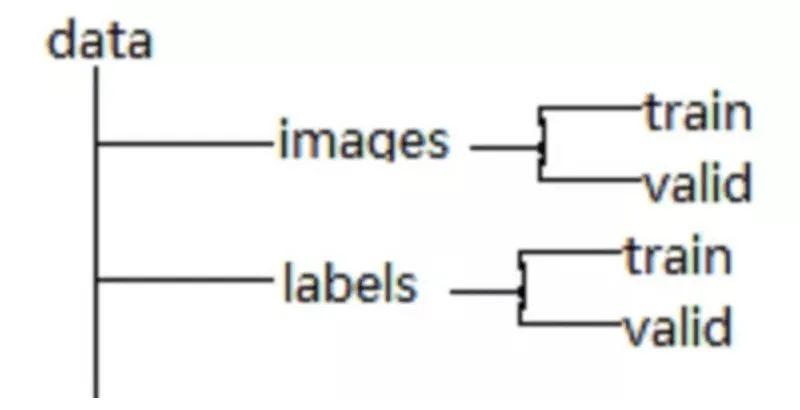
其中images是所有图像的集合,labels是所有标签信息集合。train表示训练集、valid表示测试集。这里需要注意的是,labels信息中的标签信息YOLO格式标注框需要把原始标注信息的标注框格式从:
Left top right bottom
转换为
Center_x, center_y, width, height
并归一化到0~1之间,这部分我写了一个脚本来完成label标签的生成。代码如下:
for f in files: if os.path.isfile(os.path.join(current_dir, f)): image = cv.imread(os.path.join(current_dir, f)) label_file = os.path.join(current_dir, "label", f.replace(".jpg", ".txt")) yolo_label = f.replace(".jpg", ".txt") data_label_text_f = os.path.join(valid_label_dir, yolo_label) file_write_obj = open(data_label_text_f, 'w') with open(label_file) as f: boxes = [line.strip() for line in f.readlines()] clazz_index = -1 # create new file for box in boxes: anno_info = box.split(" ") if anno_info[0] == "Cricket": print("class name: ", anno_info[0] + " ball") x1 = float(anno_info[2]) y1 = float(anno_info[3]) x2 = float(anno_info[4]) y2 = float(anno_info[5]) clazz_index = 0 else: print("class name: ", anno_info[0]) x1 = float(anno_info[1]) y1 = float(anno_info[2]) x2 = float(anno_info[3]) y2 = float(anno_info[4]) clazz_index = 1 h, w, c = image.shape cx = (x1 + (x2 - x1) / 2) / w cy = (y1 + (y2 - y1) / 2) / h sw = (x2 - x1) / w sh = (y2 - y1) / h file_write_obj.write("%d %f %f %f %f\n"%(clazz_index, cx, cy, sw, sh)) # cv.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)),(0, 0, 255), 2, 8) file_write_obj.close()最后需要创建一个dataset.ymal文件,放在与data文件夹同一层,它的内容如下:
# train andval datasets (image directory or *.txt file with image paths)train:football_training/data/images/train/val: football_training/data/images/valid/# number ofclassesnc: 2# class namesnames:['Cricketball', 'Football']
其中
Cricketball与Football是我从Open Image中下载的两个类别数据。nc:2 表示识别两个类别。
这样就完成了整个数据集准备部分。
模型训练与推理测试
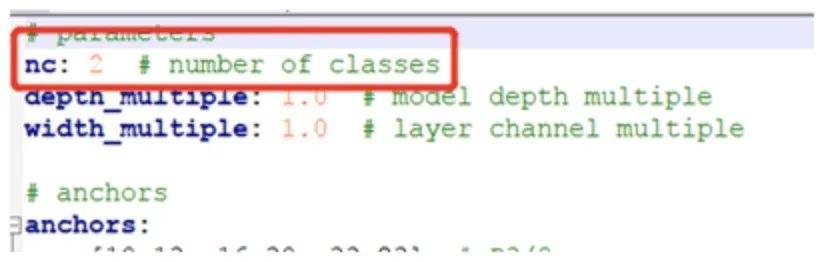
这里我分别基于yolov5l.ymal与yolov5s.ymal完成了模型训练,需要修改的只有一个地方,就是把类别数目从80改为2。图示如下:
然后执行训练脚本的命令行如下:
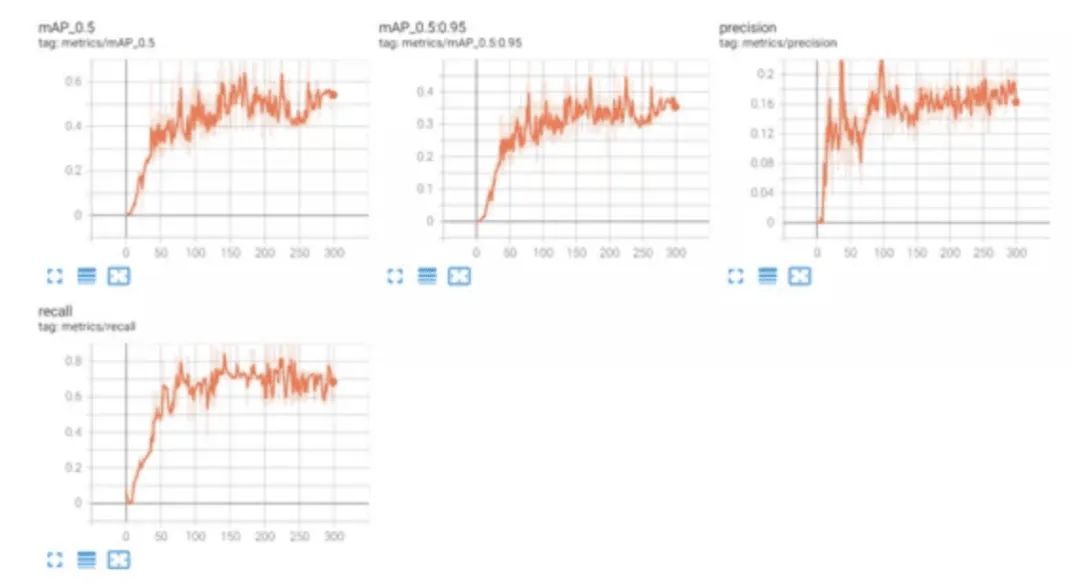
python train.py --data --epochs 300 football_training/dataset.yaml --cfg football_traing/yolov5l.yaml --weights '' --batch-size 1推荐的参数中没有这么小的batchi-size,我是用笔记本训练,发现2就爆内存了,人穷!有条件的把这个参数调大点,效果会好!训练时可以通过tensorboard查看训练实时变换,图示如下:
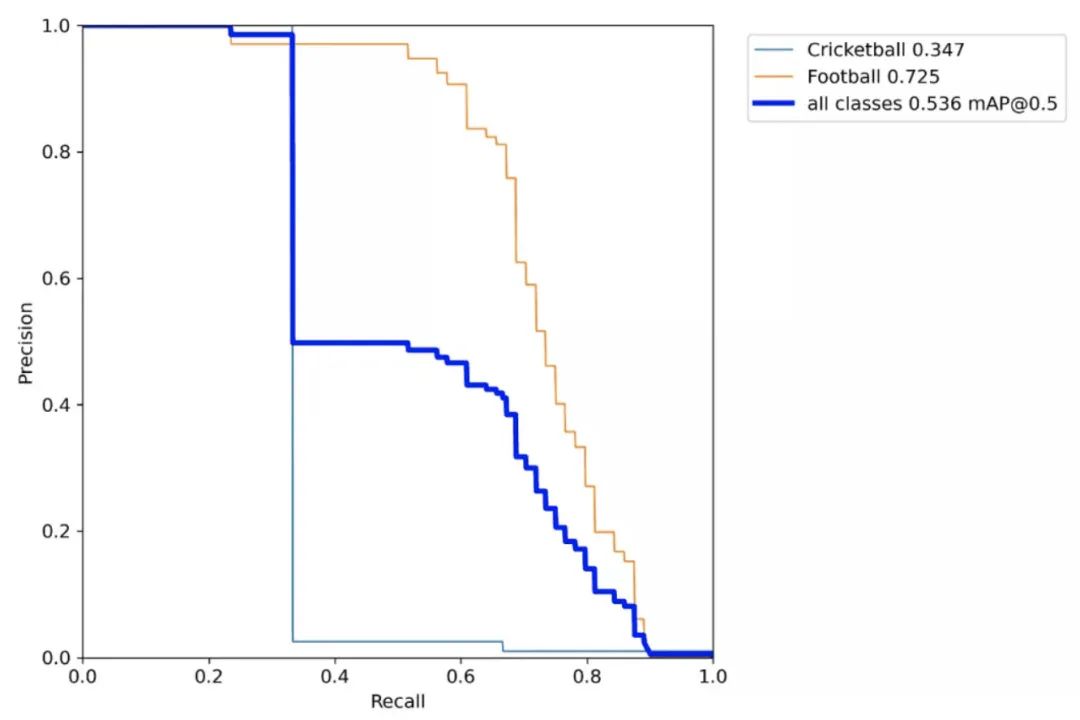
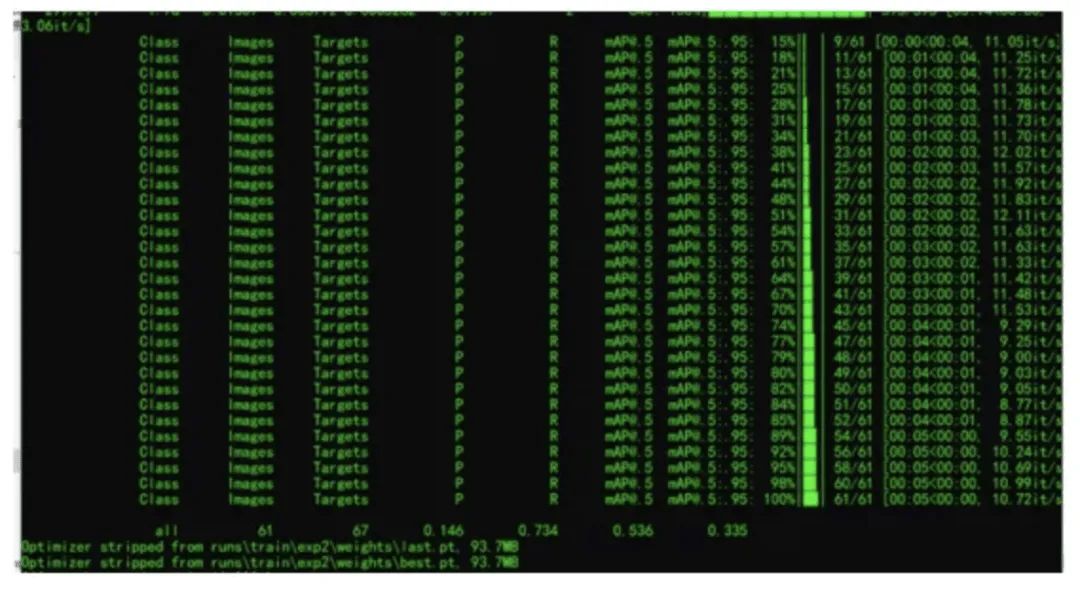
最终每个类别的AP得分
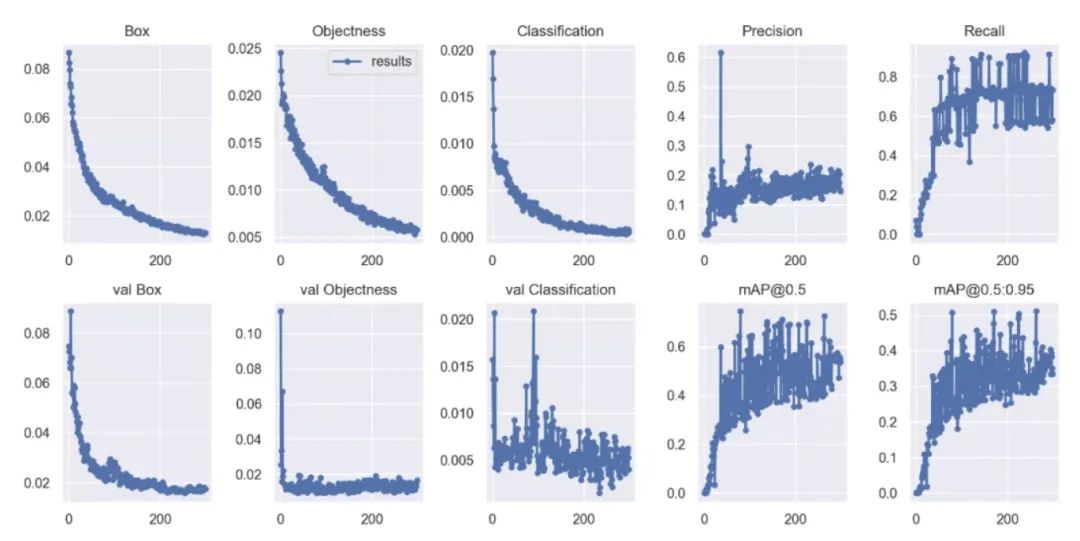
最终训练完成得到best.pt文件
运行测试视频
python detect.py --source football_training/test.mp4 --weights football_training/best.pt --conf 0.5ONNX格式推理部署
通过下面的脚本转换为ONNX文件
python models/export.py --weights football_training/best.pt --img 640 --batch 1然后再转换为OpenVINO的IR中间文件格式
运行效果如下:
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“82”获取CVPR 2021-LightTrack直播回放及PPT~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
