
美团王庆:当老板对指标进行灵魂拷问时,该如何诊断分析?


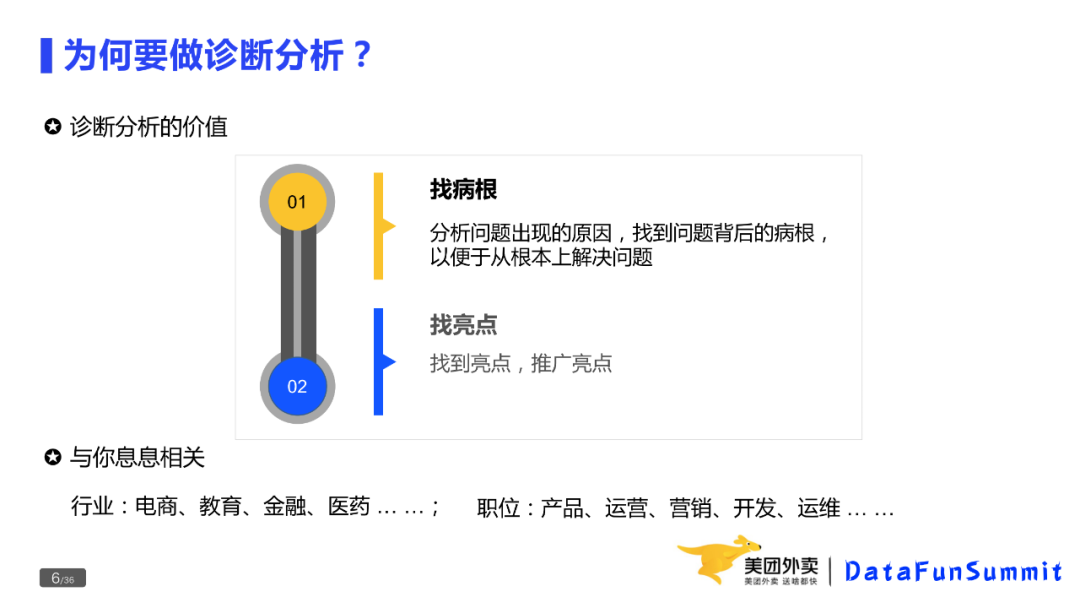
为什么要做诊断分析?
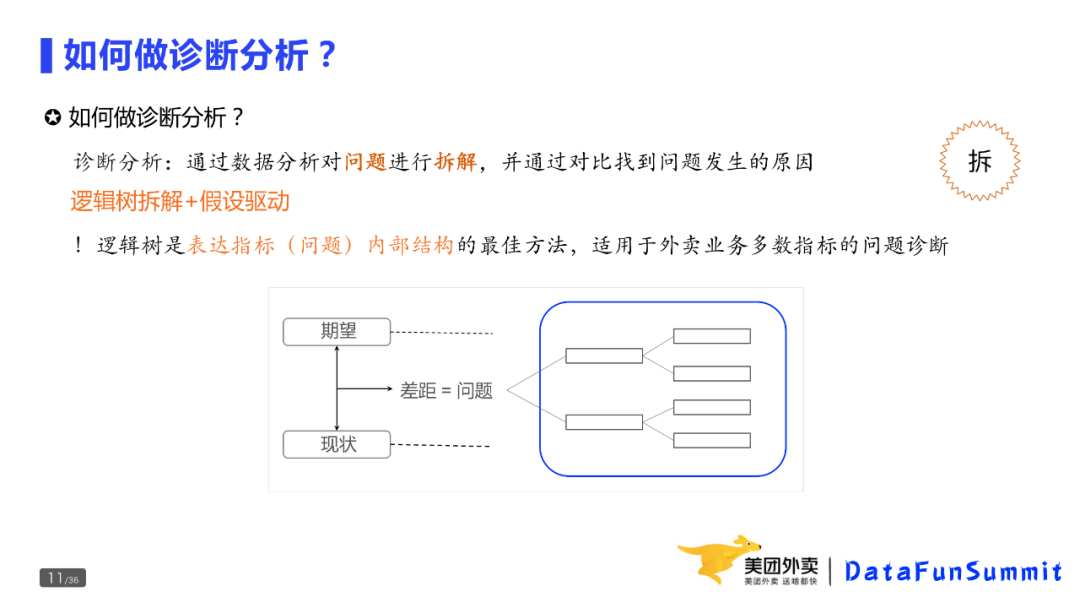
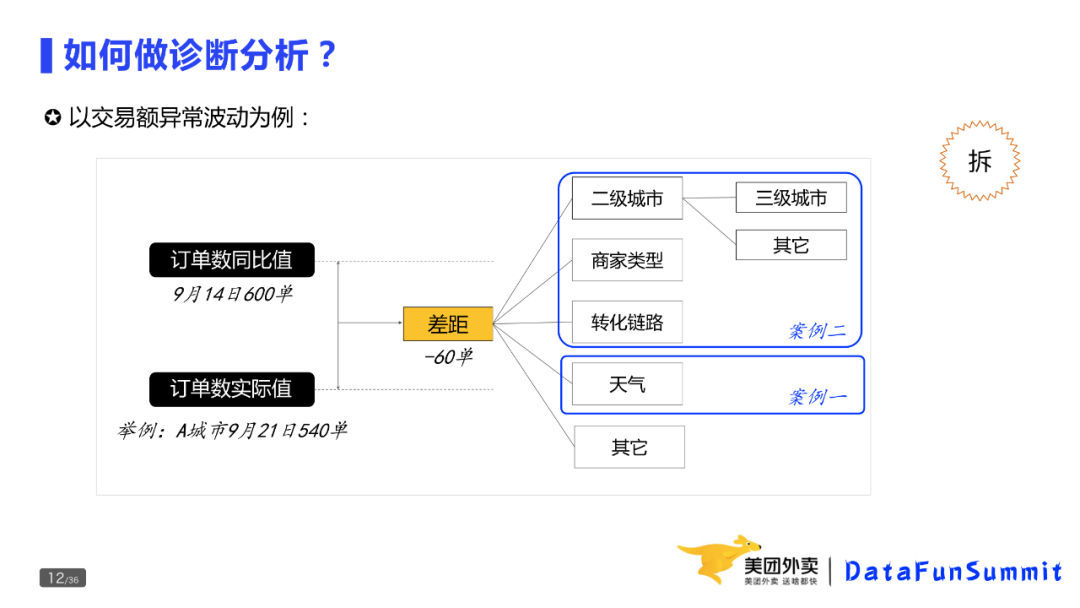
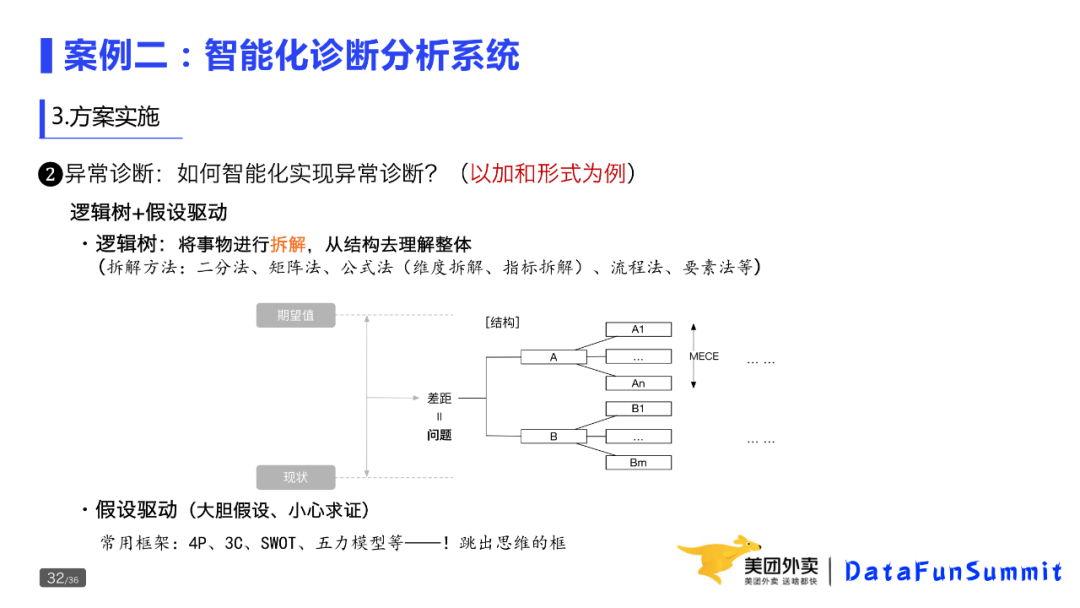
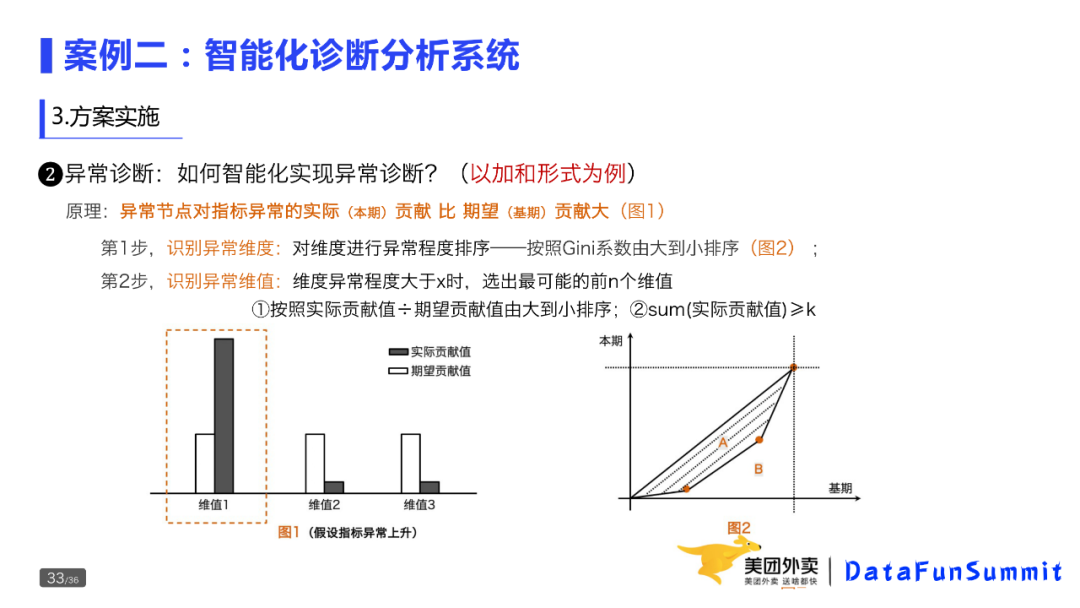
如何做诊断分析?
智能诊断案例解析
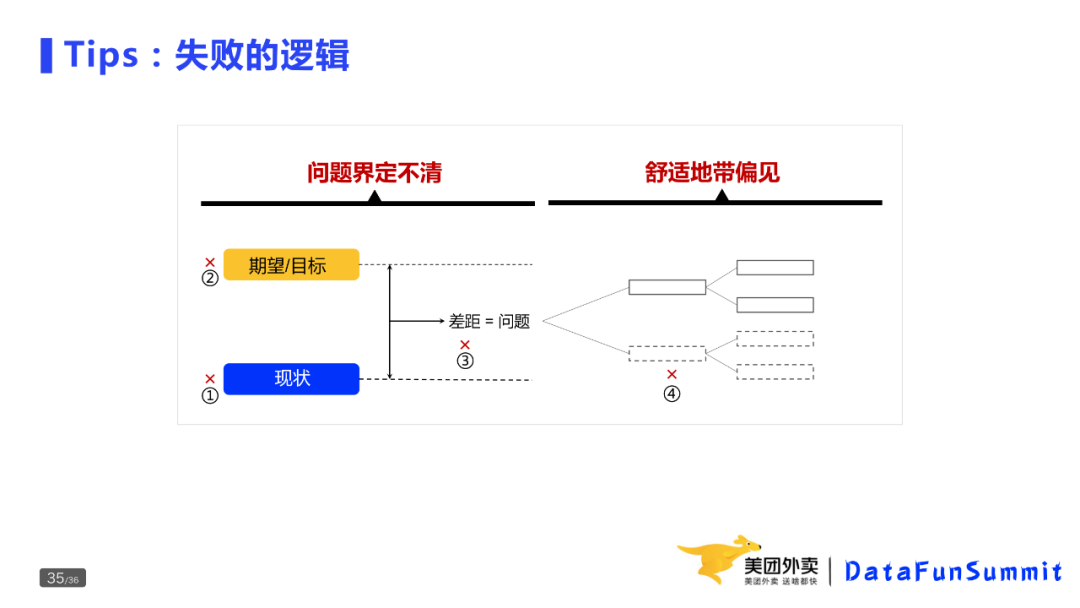
Tips:诊断分析中易犯的错误

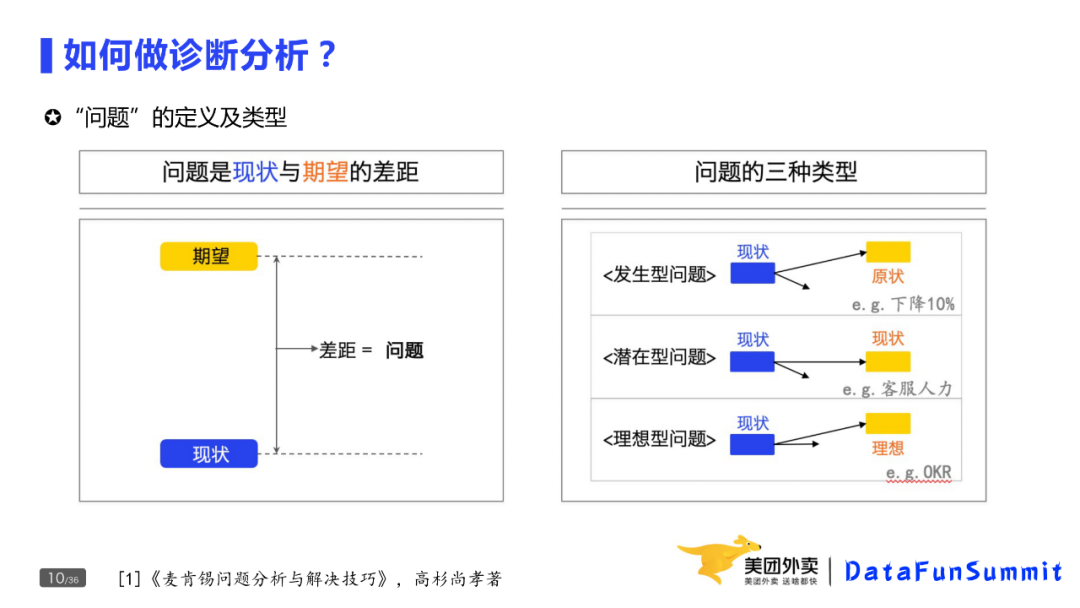
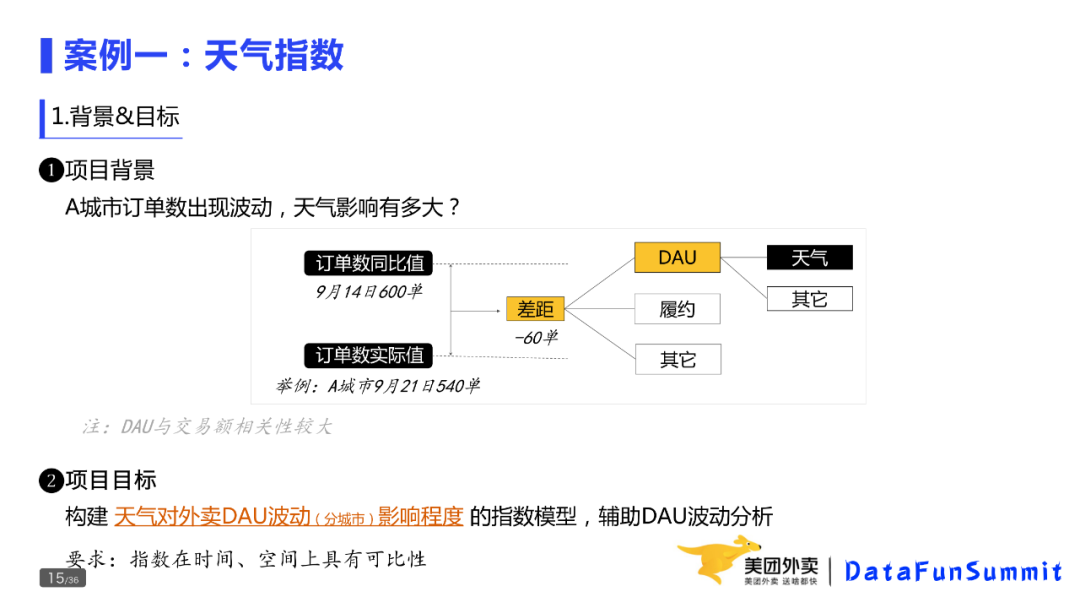
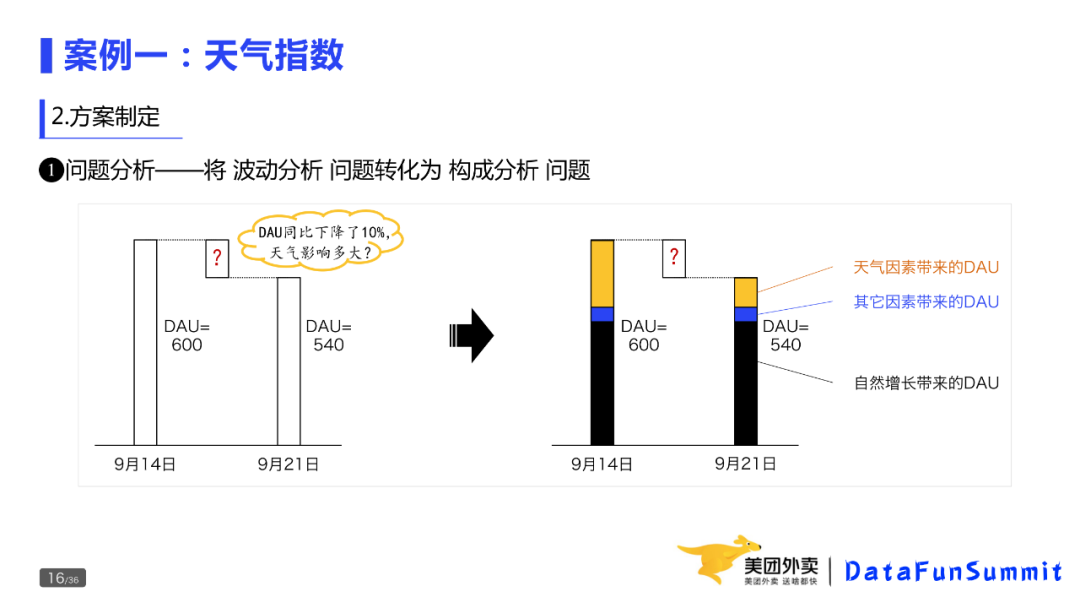
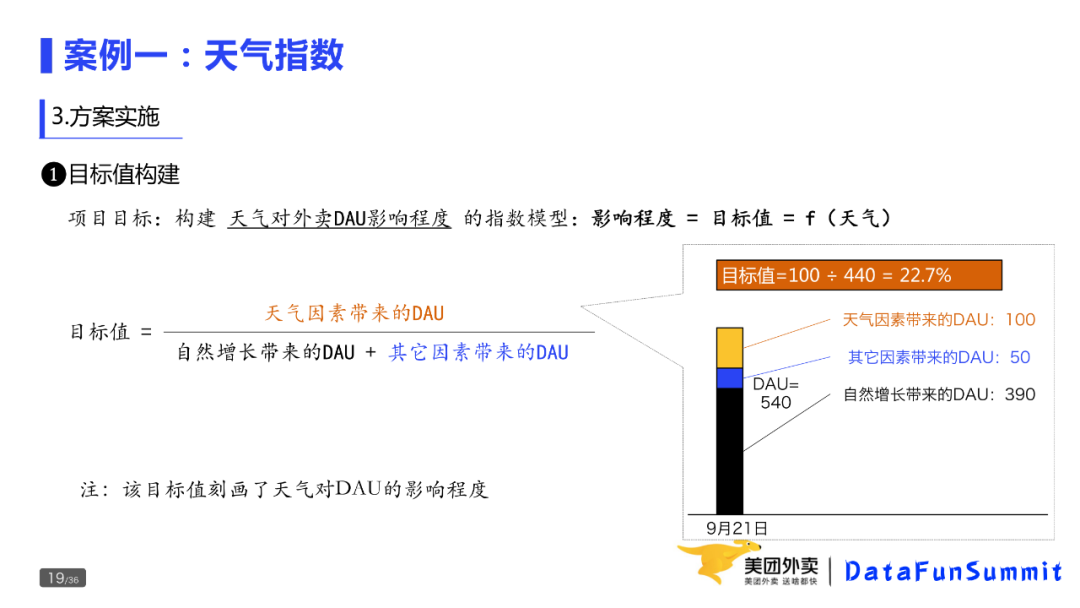
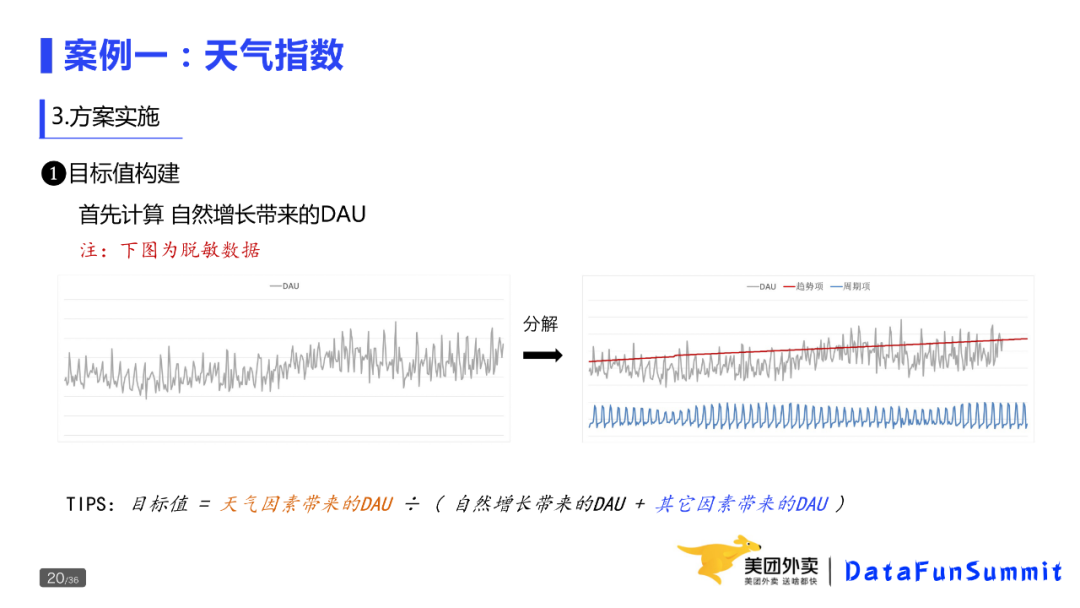
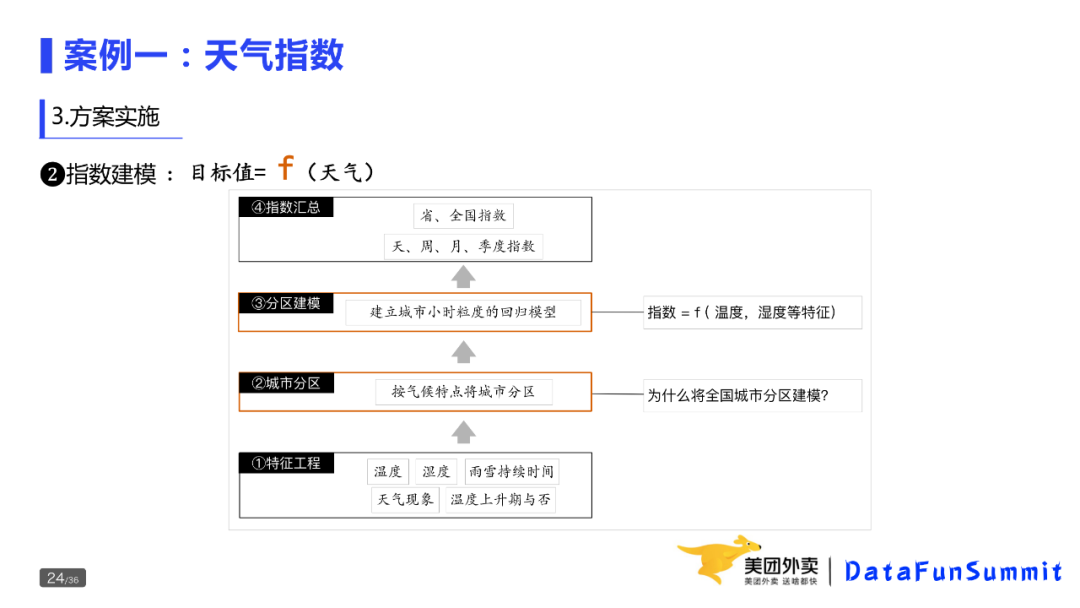
第一类是发生型问题。昨天相比订单量为什么下降10%?现状就是今天的订单量,期望是昨天的大量问题。
第二类是潜在型问题。天气变冷,客服人力是否够用,现状是当前的供需关系,期望是按这个趋势走下去,供需关系会怎样?是否存在差距,过剩还是不足?
第三类为理想型的问题,比如如何完成Q3的OKR,当前的访购率是10%,期望下个季度的访购率是12%,差距就是2pp。


一个是刚需,业务侧希望通过对指标的监控,发现业务问题、机会和潜在的风险,以及定位背后的原因,用于辅助经营决策;
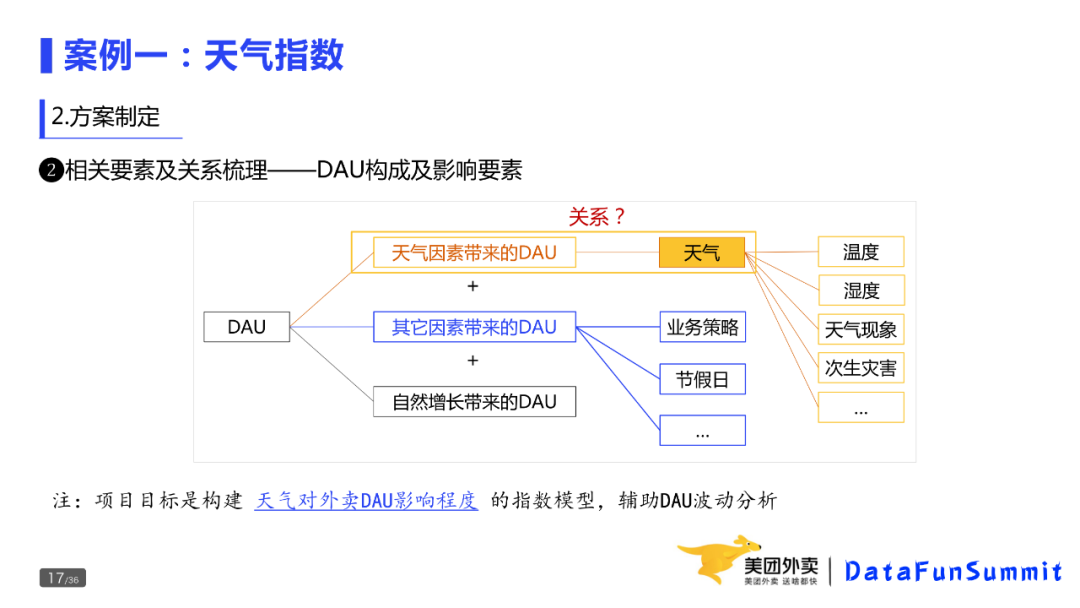
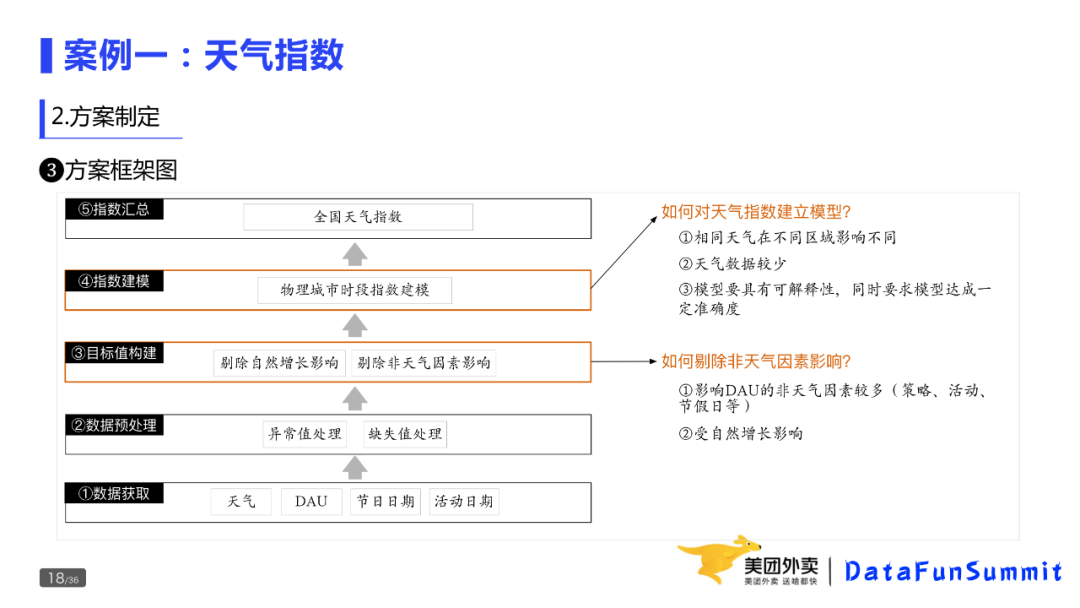
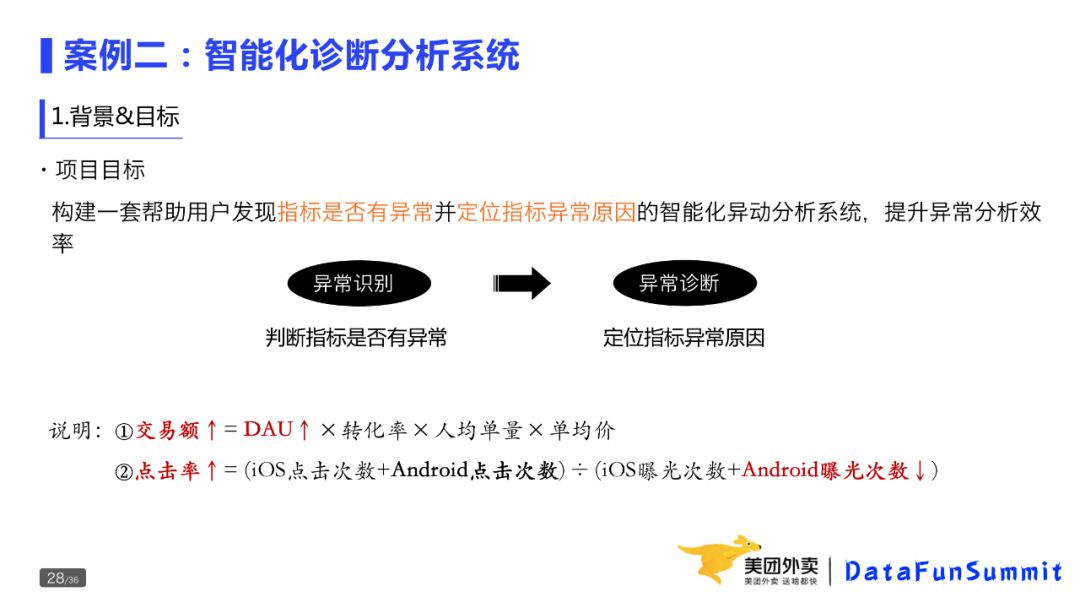
第二个是痛点,外卖侧的指标和维度非常多,靠人工分析和诊断的成本很高,对分析师的业务能力和专业素质要求也比较高,而现在的系统又无法做到有效的诊断分析;
最后是高频,业务侧的经营决策以及日常用数,都会遇到指标的波动,并期望知道波动的原因。


干货!最全需求评审指南,让你不再怕被怼
 点个“在看”吧
点个“在看”吧评论