
美团实践!如何做指标诊断分析?
分享嘉宾:王庆 美团 数据分析专家
编辑整理:刘学 字节跳动
出品平台:DataFunTalk
导读:指标为什么升?为什么降?为什么不升也不降?相信这是数据从业者经常面对的灵魂三问!在竞争激烈的市场环境下,如何快速准确定位问题原因变得越来越重要。本文将结合在外卖业务中的诊断分析实践,与大家分享数据科学在业务诊断分析中的一些应用经验。
主要从四个方面进行展开:
为什么要做诊断分析?
如何做诊断分析?
智能诊断案例解析
Tips:诊断分析中易犯的错误
为什么要做诊断分析呢?可以从两个方向理解:诊断分析是有价值的,并且与每个人息息相关。
诊断分析的价值,至少有两类:
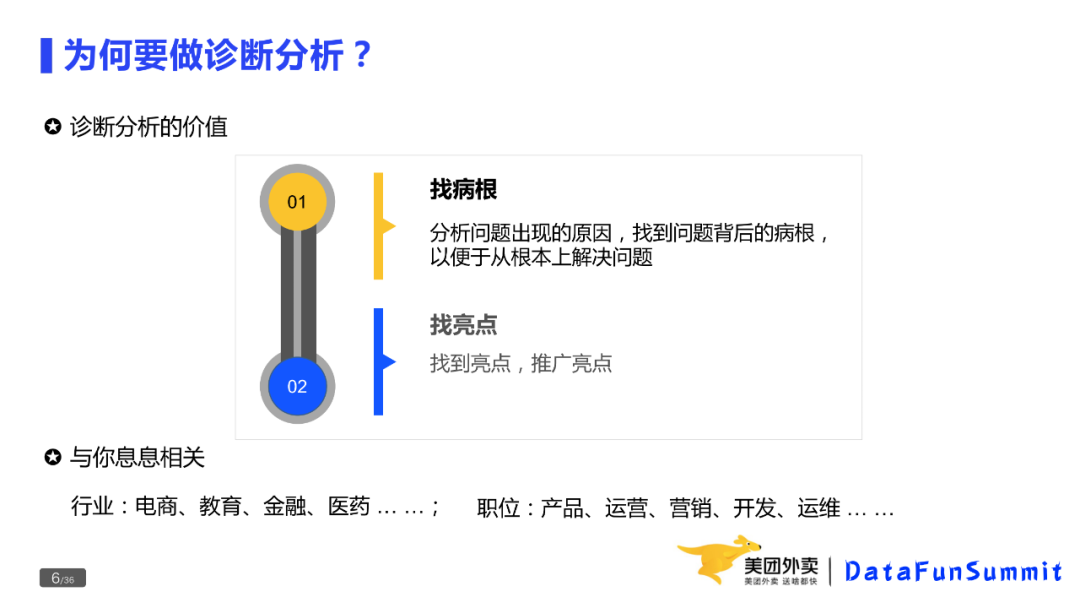
价值1:找病根,确认问题出现的原因,为策略制定和问题解决提供方向。
比如,2020年12月份,谷歌宕机了45分钟,损失了大概170万美金,事后需要对宕机的原因进行分析;再比如,今年抖音发生一次事故,很多用户登录不上影响用户体验并且影响了广告收入,那为什么崩了,也需要引入诊断分析。
诸如此类的问题,在互联网公司经常出现,那就需要及时发现问题、分析原因、制定策略、解决问题,以避免发生类似问题。
当然,并不是所有的问题都能找到原因或者是需要找原因的。比如上班途中车胎扎了,因为属于偶发性因素,不需要找原因;再比如,通过数据分析发现了一批特别喜欢吃辣的用户,则未必能找到吃辣的原因,而且哪怕找到原因,也未必有价值。反而不如先把这个发现利用起来。
价值2:找亮点,然后推广亮点。
找亮点,找到亮点后,推广亮点。当前,多数公司的推荐系统,就是在利用找亮点,基本上把亮点做到了极致。
本次分享主要是论述价值1:找病根。
1. 什么是诊断分析
Gartner对诊断分析有一个定义:Diagnostic analytics is a form of advanced analytics that examines data or content to answer the question, “Why did it happen?”
上述概念比较抽象,结合工作中的实践,我认为,诊断分析就是通过数据分析对问题进行拆解,并通过对比找到问题发生的原因。这种定义方式,比较容易利用数据化的语言进行表达,并且可在工作中进行充分利用。
2. 什么是问题
诊断分析的关键是就是对问题的拆解。那什么是问题呢?在日常数据分析工作中,又会遇到哪些问题?
① 问题的定义
看几个常见的问题例子:

在工作中,我们经常会遇到的问题是中间3类。
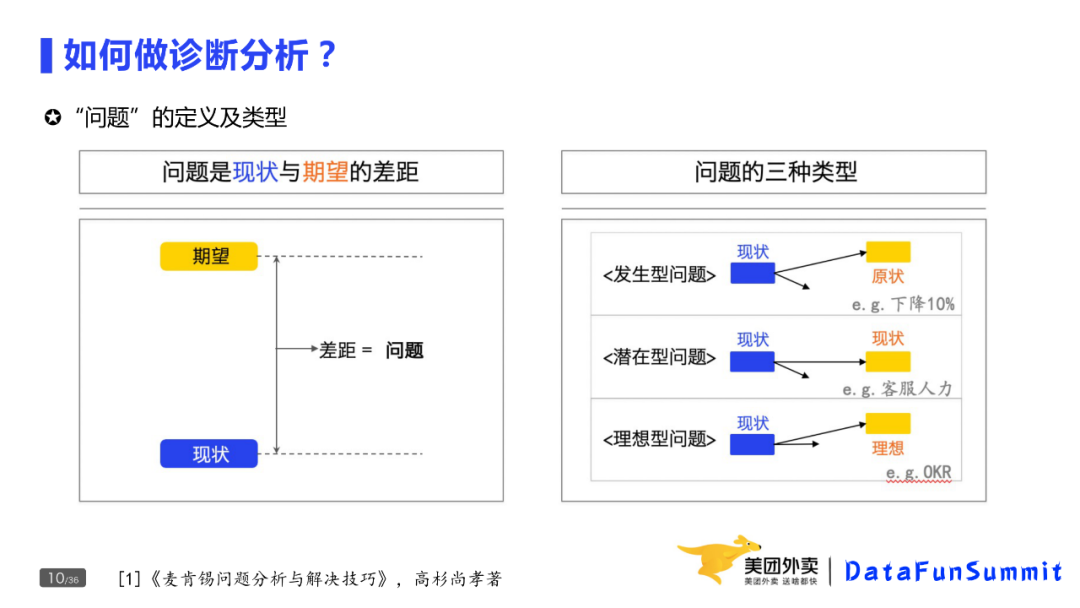
问题的定义是现状与期望的差距。
② 常见的问题类型
常见的问题有三类:
第一类是发生型问题。昨天相比订单量为什么下降10%?现状就是今天的订单量,期望是昨天的大量问题。
第二类是潜在型问题。天气变冷,客服人力是否够用,现状是当前的供需关系,期望是按这个趋势走下去,供需关系会怎样?是否存在差距,过剩还是不足?
第三类为理想型的问题,比如如何完成Q3的OKR,当前的访购率是10%,期望下个季度的访购率是12%,差距就是2pp。
本次分享,主要围绕发生型问题和潜在型问题展开。
3. 如何做诊断分析
一种相对普适性的方法就是“逻辑树+假设驱动”。 因为逻辑树能够帮助我们确定分析问题的框架,而假设驱动可以确定分析问题的视角。这里,逻辑树是表达指标(问题)内部结构的最佳方法,适用于外卖业务多数指标的问题诊断。
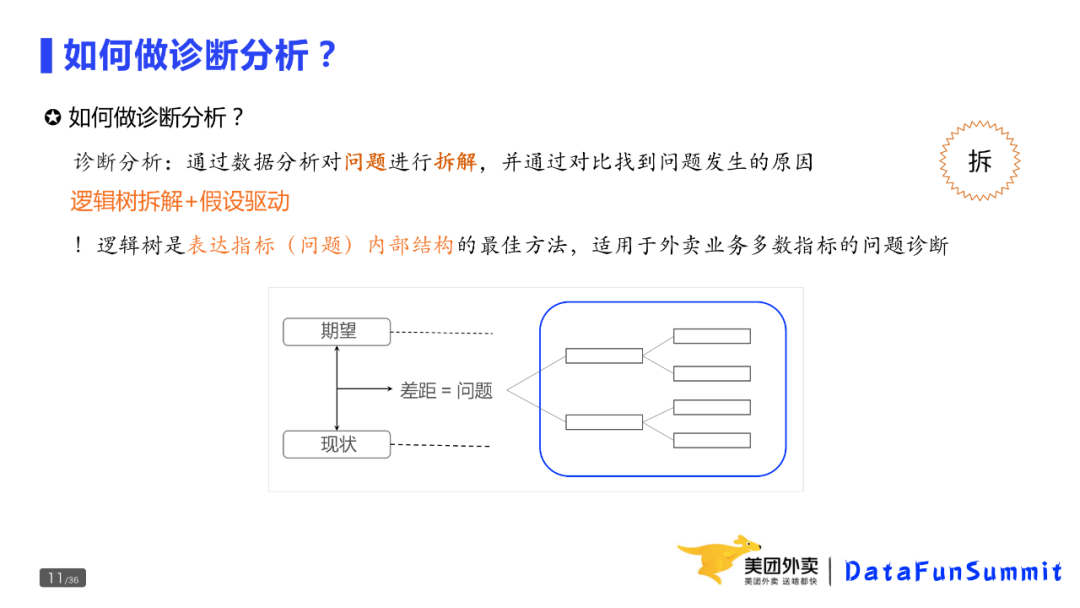
结合上图,再来看一下诊断分析的过程:首先是明确问题差距;有了问题后对问题拆解(注意:是对问题拆解而不是指标)。这里,需要进行两类拆解:一类是按照构成的期望占比拆解,一类是按实际占比拆解,最后对比两棵逻辑树的差异并给出原因。
通过一个交易额波动的例子,来看一下怎么用逻辑树+假设驱动解决诊断分析问题。
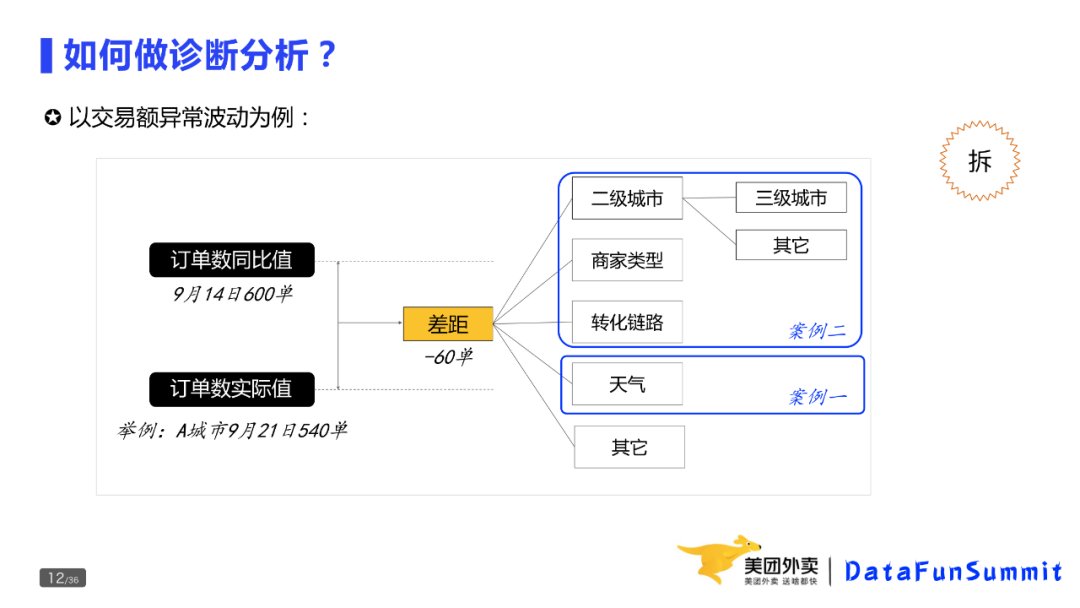
订单量周同比下降了10%,在这个例子中是60单,这就是问题。那问题为什么会发生?那就需要利用假设驱动,确定分析视角。比如可以从城市(假设)的维度进行拆解,发现其他城市的单量变化不大,而北京同比下降了,贡献其中的50单。那继续进行,为什么北京下降那么多?继续拆解后,发现是朝阳区贡献40单。再继续拆解,发现是上周下雨、本周晴天导致单量下降了42单,此时得出订单量下降的主要原因是天气变化。
在整个过程中,我们不断地问为什么,不断地对问题进行拆解,最终定位到问题发生的原因。
在上面的例子中,我们发现,哪怕知道了如何做诊断分析,还是需要投入大量的人力进行人工分析,数据获取的成本比较高,耗时耗力。所以需要通过一些算法和数据建模的方法,对诊断分析进行智能化、自动化,提升诊断分析的效率。
下面将通过美团外卖的两个项目,介绍怎么进行诊断分析:
项目1:天气指数
1. 背景与目标
① 项目背景
外卖作为O2O项目,分析和经营决策非常依赖线下场景信息。而其中一个重要的信息就是天气,而业务希望利用更准确的天气信息提升决策质量。
天气对于外卖的影响还是比较大的,比如下雨对DAU有正向促进作用,用户更可能登录APP点外卖;而春天比较舒适的日子,则会有抑制作用。
还是回到之前的例子。订单量下降,发现是DAU下降。那DAU下降,天气的影响又有多少。
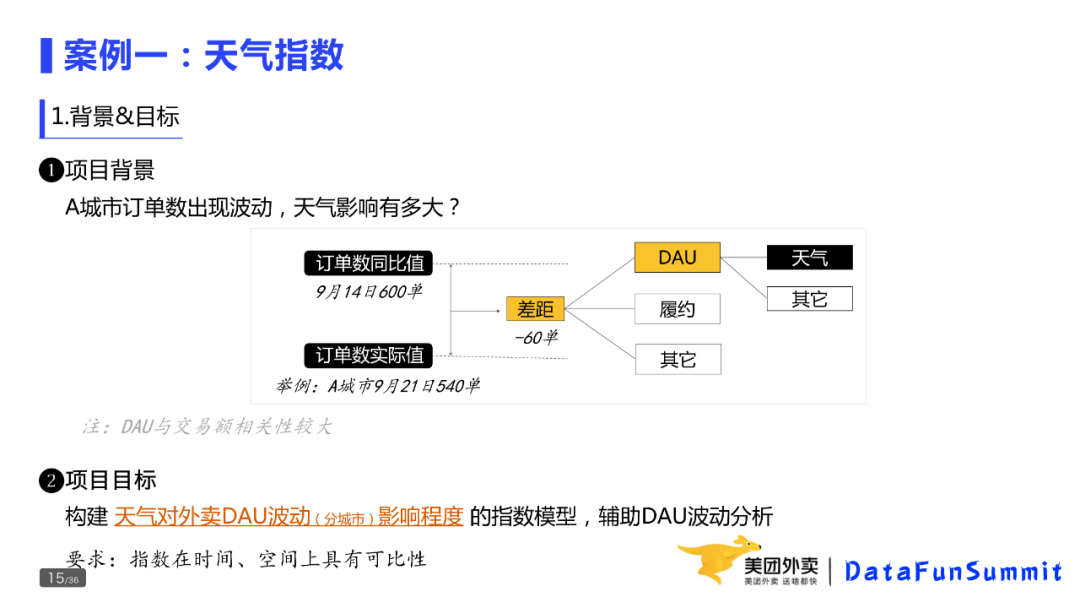
② 项目目标
构建天气对外卖DAU波动(分城市)影响程度的指数模型,辅助DAU波动分析。
当然,影响DAU的因素有很多,这里主要对天气进行建模。
业务上,需要指数在时间、空间上具有可比性。这里的可比性,是指所构建的指数,在不同的天气以及不同的地域上,表达的含义是一致的。比如,如果下雨对北京的DAU影响是20%,高温对上海的影响是20%。这两个20%应该表达同样的意思,才方便业务使用。
2. 方案制定
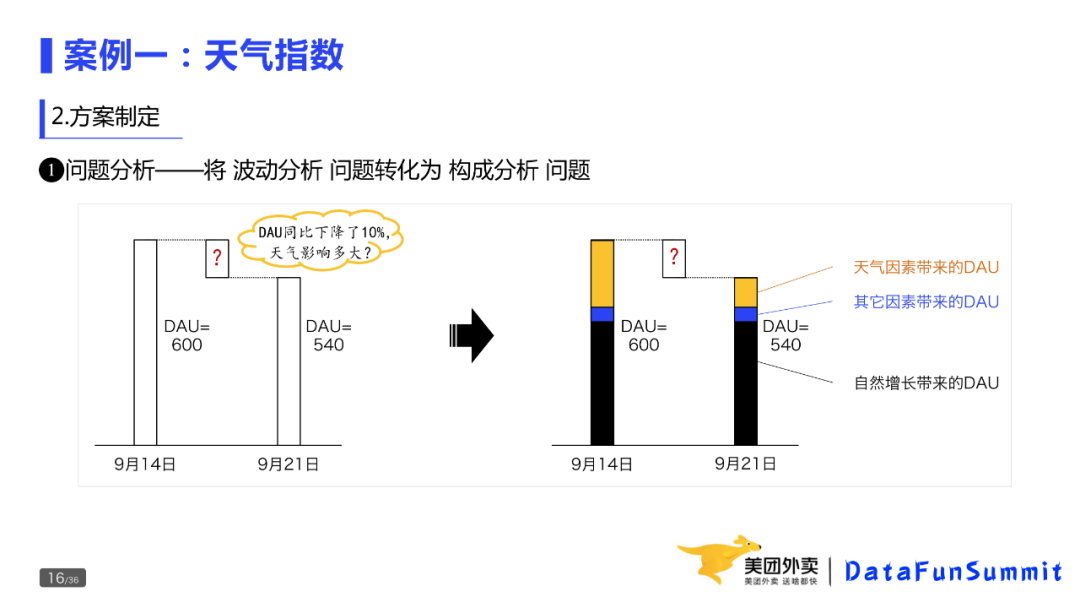
① 问题分析——将波动分析问题转化为构成分析问题
问题本身是要回答,业务下降的部分有多少是由天气带来的。为了解决这个问题,我们将DAU拆解成三个部分,分别是天气因素带来的DAU、其他因素带来的DAU以及自然增长带来的DAU。这里的自然增长,是指在没有天气和其他因素影响的前提下,DAU的正常值是多少。这里,如果我们把天气因素带来的DAU计算出来,问题就解决了。
② 相关要素及关系梳理——DAU构成及影响要素
这三个部分,又分别受到不同因素的影响:天气带来的影响,会受到温度、湿度、天气现象、次生灾害的影响,其他因素带来的DAU会受到业务策略、节假日等影响。
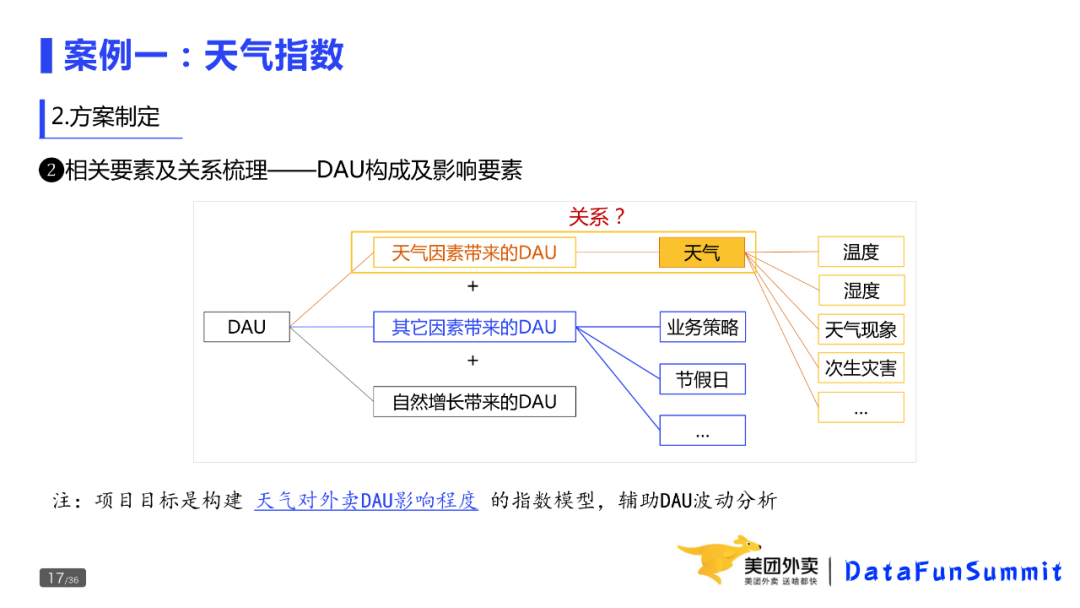
而项目目标是构建天气对外卖DAU影响程度的指数模型,辅助DAU波动分析。就是刻画图中黄色框所表达的关系。
③ 方案框架图
如下给出天气指数建设的整体方案:
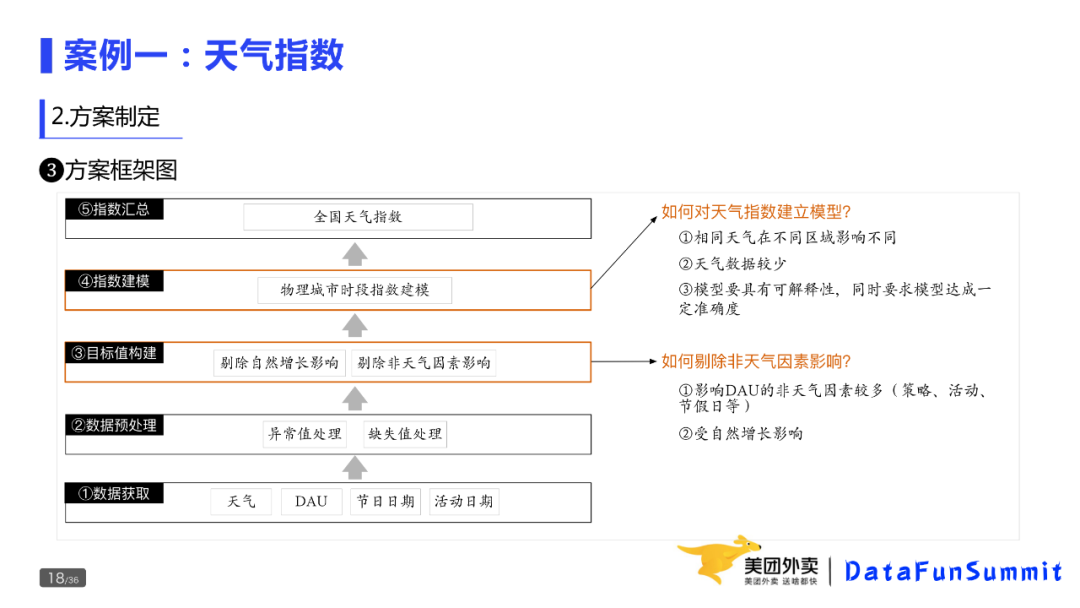
整个方案其实包括五部分,分别是数据获取、数据预处理、目标值构建、指数建模以及指数汇总。前两部分主要是为模型准备数据,后面是建立模型,并计算出天气指数。下面主要介绍第三、四部分。
3. 方案实施
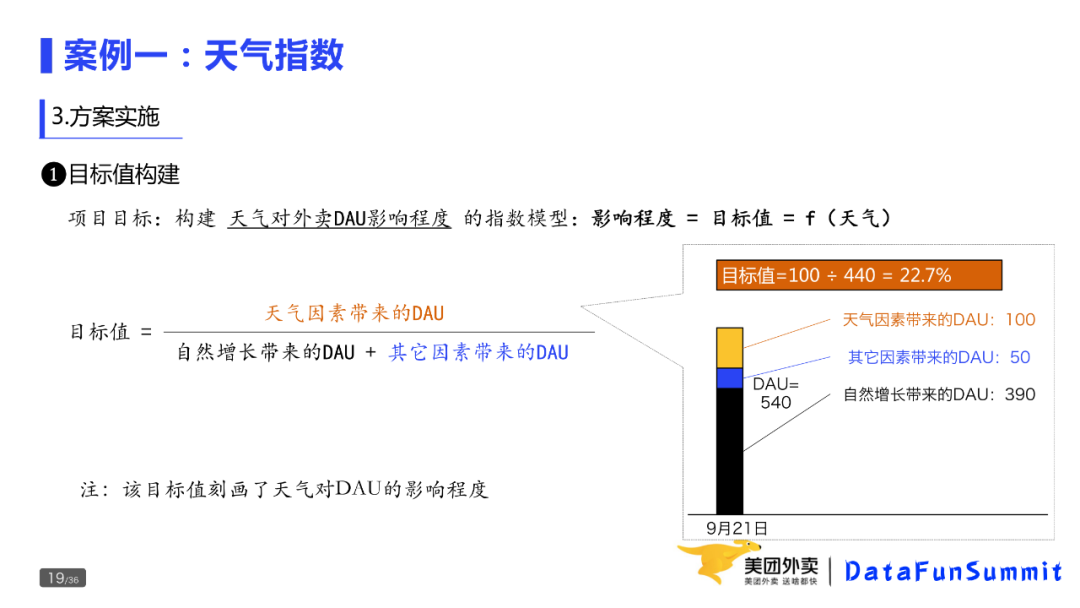
定义:

如上图所示,如果DAU为540万,其中三部分分别为100万、50万、390万,则目标值为100 / (390 + 50) * 100% = 22.7%。
因此,我们只要分别求出如上三个因素,就可以求解出目标值了。
a. 计算自然增长带来的DAU
这里借用时间序列分析中的思想,对DAU做一个拟合,并将DAU分解出趋势项和周期项。定义:自然增长带来的 DAU=趋势项+周期项。
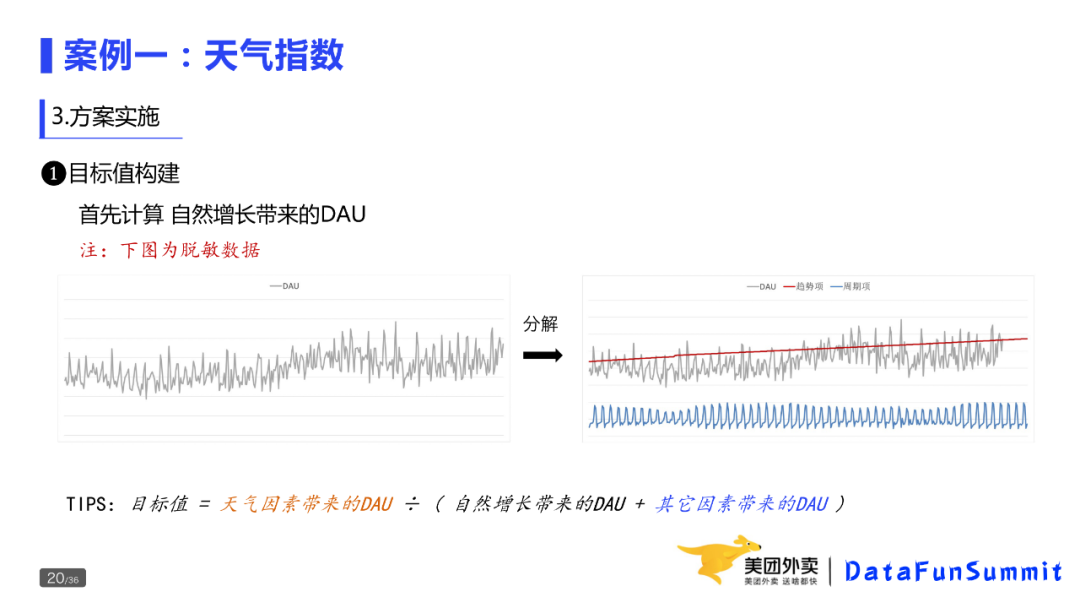
b. 计算其他因素带来的DAU
这个问题一般的反应是,先依次找出其他因素是什么,然后分别计算其影响。但这里会有三个困难:影响因素无法穷尽;影响无明显规律,比如五一具体影响多少,很难获得;影响会相互叠加,逐一剔除的技术难度极大。
这里,引入概率思想,认为其他因素之间相互叠加后,对DAU的影响为零。为什么可以忽略呢?一是其他因素,如活动、节假日,影响是随机出现的,模型一定程度上可以抵消这种影响;二是恶劣天气的影响远大于其他因素。因为这里是想通过算法学习天气对DAU影响的规律,不需要被太多因素去干扰。
c. 计算目标值

通过上述操作,将整个问题转化为一个回归问题。
整体有如下四个步骤:
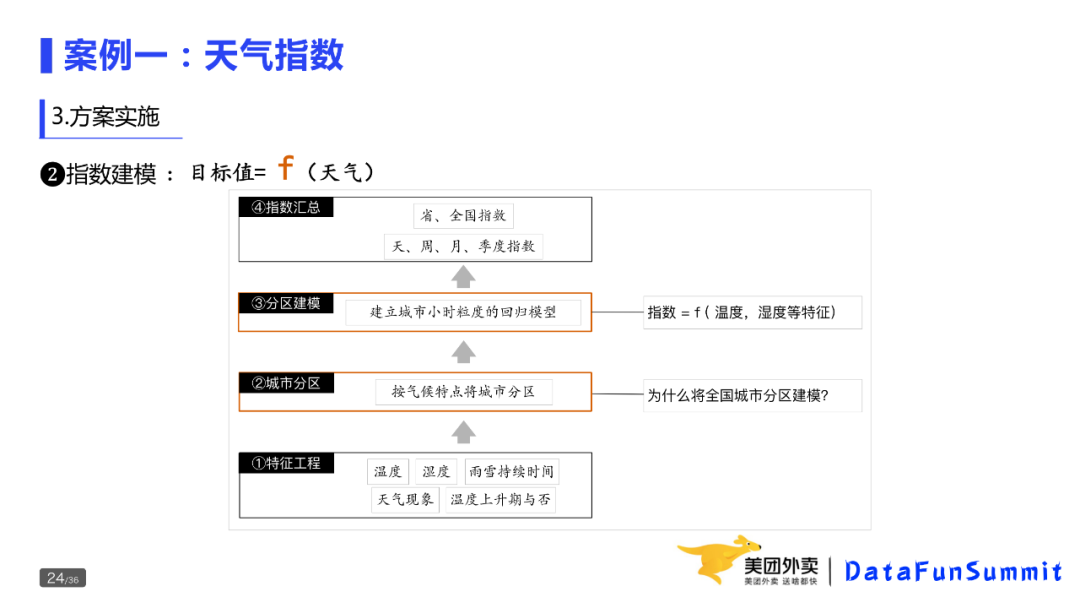
这里,第一步是特征工程,第二、三步依据气侯特点,将城市进行分区并分别建模,第四步是将细粒度的指数汇总,得到空间上更大颗粒度、时间上支持天、周、月、季等天气指数。
为什么要将全国城市分区建模?全国统一建模,面临天气在不同城市的影响不同;而每个城市分别建模,样本少,尤其是一些特殊天气较少。比如2018年和2019年的北京,就下了一两场雪,不可能找到什么规律。解决这类问题,想到两种方案:一个是采购更多的天气数据,增加样本量;第二个是通过聚类方法横向增加样本量,将天气、气候类型相似的天气放在一起建模。这里,我们采用了第二个方案:城市分区建模,充分利用已有数据。
最后,目标有了,天气有了,引入XGBOOST模型建立关系。从模型效果上看,完全可以满足业务要求。具体的数据,这里就不展示了。
项目2:智能化诊断分析系统的建设
1. 背景与目标
① 项目背景
为什么要开发这套智能化诊断分析系统?三个方面:
一个是刚需,业务侧希望通过对指标的监控,发现业务问题、机会和潜在的风险,以及定位背后的原因,用于辅助经营决策;
第二个是痛点,外卖侧的指标和维度非常多,靠人工分析和诊断的成本很高,对分析师的业务能力和专业素质要求也比较高,而现在的系统又无法做到有效的诊断分析;
最后是高频,业务侧的经营决策以及日常用数,都会遇到指标的波动,并期望知道波动的原因。
② 项目目标
构建一套帮助用户发现指标是否有异常并定位指标异常原因的智能化异动分析系统,提升异常分析效率,从而提升决策的效率和质量。
整个系统会包括两部分:异常识别和异常诊断。
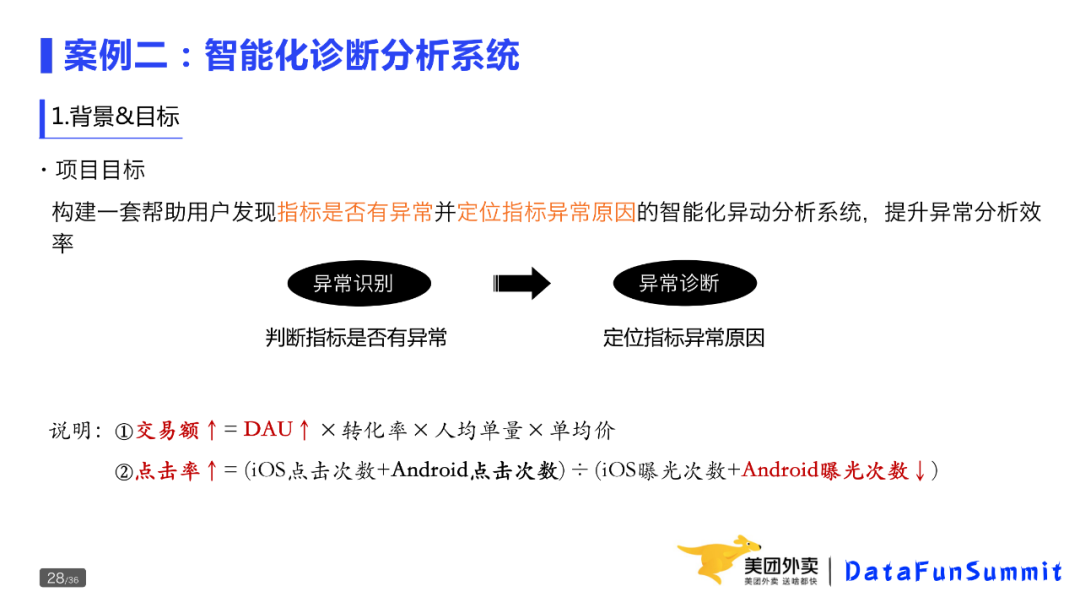
比如上面两个例子,交易额的异常上升,通过纵向拆解,可以定位到DAU;点击率的异常上升,定位到Android曝光次数的下降。
2. 方案制定
方案制定主要包括5个模块,数据获取、数据预处理、异常识别、异常诊断和数据服务。这里主要介绍算法部分的实现思路。异常识别主要是自动化判断是否异常,做到“知其然”,而异常诊断模块,要回答异常波动的原因,做到“知其所以然”。下面分别进行介绍。

3. 方案实施
① 异常识别
比如看如下一种场景,一天早上,老板说我发现最近单量下降了,帮我看一下原因。这里,有几个问题:单量下降是和谁比下降了,环比、同比还是去年同期;下降了,下降了多少,是1%还是10%。所以这个模块,需要解决三个问题:第一个是比什么,就是比较什么样的业务指标;第二个是和谁比,是不同对象的横向对比,比如北京与上海,还是同一对象在纵向比;第三个是怎么比,是绝对比较(现状和期望的绝对差),还是相对比较(现状和期望的比值、TOPN、或者概率分布等),注意,很多距离类的函数都可以用到这边。
② 异常诊断

异常诊断包括定性与定量两部分。其中,定量部分又包括贡献分析和构成分析,贡献分析是指当指标异常时进行公式拆解,包括指标拆解,还有维度拆解,然后量化相关指标对指标异常的贡献度,接下来主要介绍加和形式的诊断分析;构成分析,就是用来判断指标结构是否有异常。很多时候,业务指标没有问题,但他的内部结构有问题。比如埋点错误,将安卓下面的埋在了其他之中,虽然整体上没有问题。而定性部分包括两个方法,相关分析和事件分析。相关分析,是指对不具有公式关系的指标进行简单分析,比如一个交易上升,定位到某个具体的活动上线;而事件分析,与相关分析有些类似,主要包括一些相关事件,如天气、节假日、活动等。后期会尝试量化事件对于业务指标的影响。
下面,以加和形式的异常诊断为例,介绍一下如何智能化的实现异常诊断。
还是采用第二部分介绍的“逻辑树+假设驱动”。系统主要是提供构建逻辑树的功能,当然,还需要提供用户分析视角,就是假设驱动。而诊断效果的好坏,往往非常依赖于用户提供的分析视角。诊断效果不仅取决于模型设计,且依赖于使用系统的人,如果没有找到好的分析视角,也不会得到很好的结果。
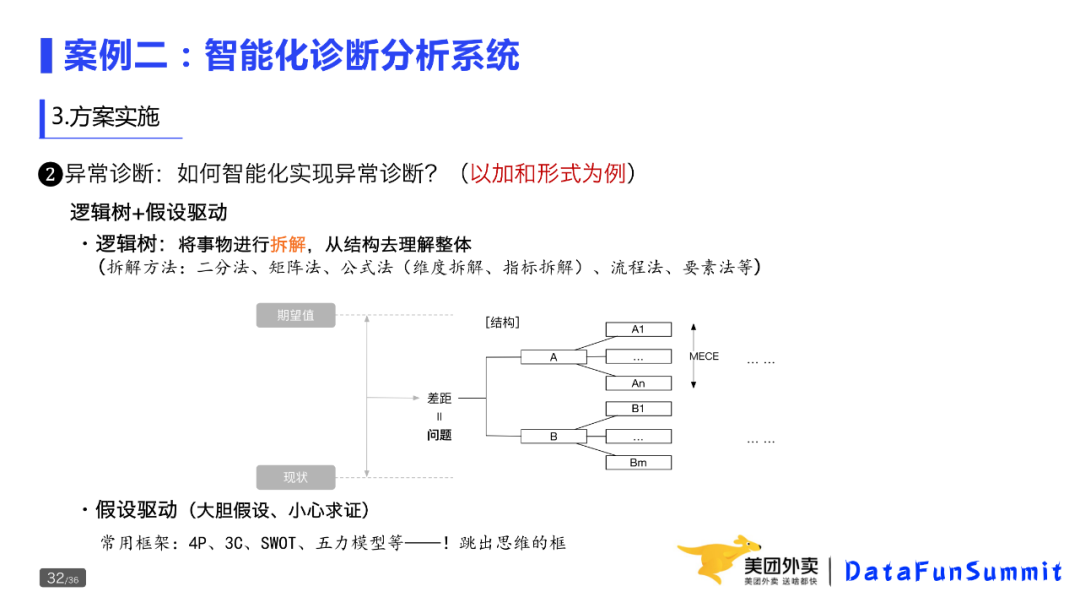
比如外卖DAU异常了,从城市维度看,是不是城市有异常;从订单维度看,是不是线下做了活动。这些都需要用户提前告知系统。当然,从系统建设角度看,也有义务去收集分析的维度。
那算法是怎么定位异常的呢?
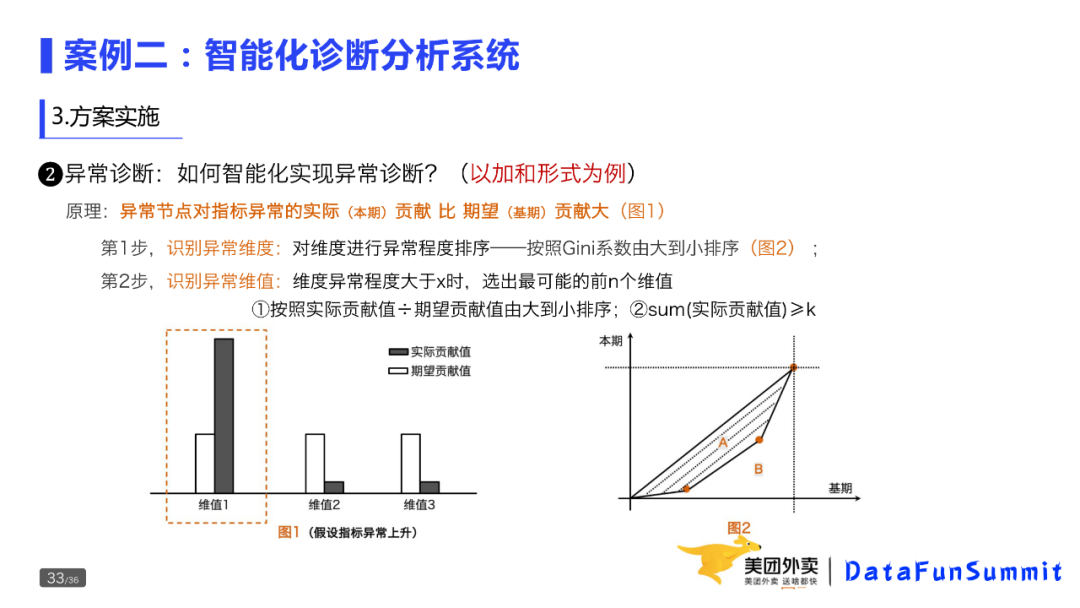
所谓异常,就是异常节点对指标异常的实际(本期)贡献比期望(基期)贡献大。这与问题的定义是一致的。当然,异常诊断的算法有很多,但原理大同小异,一般包括两个部分:第一个是识别异常维度,该系统采用的方法类似于基尼系数;第二部分是识别异常维值,依然从问题的定义出发,选出对异常贡献最大的维值。这里不介绍算法的细节,近期会公开相关文章。
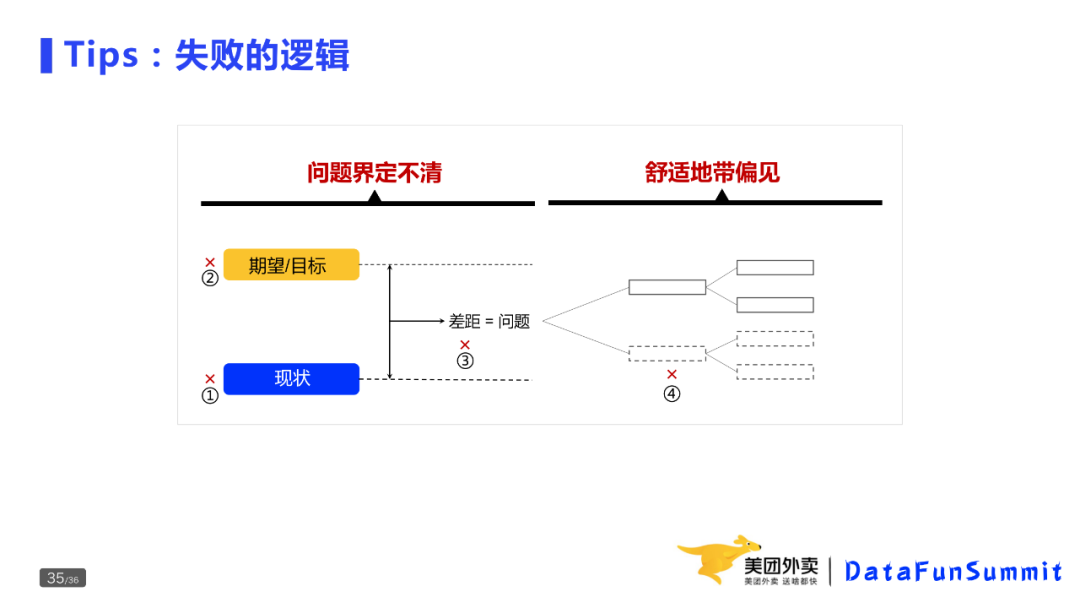
为什么诊断会失败呢?
能够顺利解决问题的一个很重要的原因是诊断分析结果的好坏,即是否找到真正的原因。这里,将导致诊断效果不理解的原因概括为两个方面:一个是问题界定不清楚,一个是停留在舒适地带。
原因1:问题界定不清楚
回到问题的定义,是指现状与期望的差距。这里有三个关键词,一是现状。有时候我们无法正确描绘问题,主要原因就是对现状的认识不清。比如想诊断外卖的供需关系是否正常,就需要定义清楚当前的供需关系;二是期望,选择是否合理。比如每次节假日回来的那周,都会收到业务侧的反馈,比如国庆回来,为什么10月9号环比10月2号订单量异常下降了?这里就是选择的对比对象的问题,如果没有意识到这个问题,而是直接进行拆解,效果未必好;三是差距,即问题的定义。比如小城市的订单量波动10%,可能是正常的,但北京的就不正常。
原因2:舒适地带偏见
就是在分析的时候停留在舒适区,在有限的时间、有限的维度内进行诊断,只寻找局部最优解,很容易导致漏诊和误诊。当然,局部与全局是相对的,当前场景的全局最优,可能是更大场景的局部。所以要不断扩大认知边界,提供找到全局最优的可能性。举一个实际的例子,有一天,美团搜索入口的单量异常,业务方和算法排查了几天时间,搜索链路的各个环节经排查后都正常。最后经分析发现,有一个入口在做活动,把流量吸走了。而之前的分析,只是限制在了搜索这样一个场景下,走了很多弯路。
总结一下,如果想要顺利地解决问题,还是要在每个环节有逻辑地做事,增加成功的概率。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:


推荐阅读
欢迎长按扫码关注「数据管道」