
巧了,这几个项目,我王多鱼投(喂)了!
大家好,我是 Jack。
愉快的假期结束了,周末又休了两天年假,今天开启打工仔模式。

今天先热热身,分享几个假期看到的 AI开源项目。
1VToonify
人物头像风格迁移算法,又有了新进展。
如果你想拥有一个,和本人照片相像的卡通头像,不妨试试这类算法。
VToonify 相比于之前的算法,效果上得到了很大的改进。
左侧是原始照片,中间是夸张漫画风,右侧是漫画风。

这里有更多的效果,只能说生成效果真是越来越好了。

我们甚至可以根据自己喜欢的风格,灵活调整:


可以灵活切换不同的风格:

甚至多种风格进行融合:

VToonify 生成的这些人像不仅具有高度可调的卡通风格,而且包含了人像的很多细节。
动画影视作品、VR 场景都可以用到这项技术。
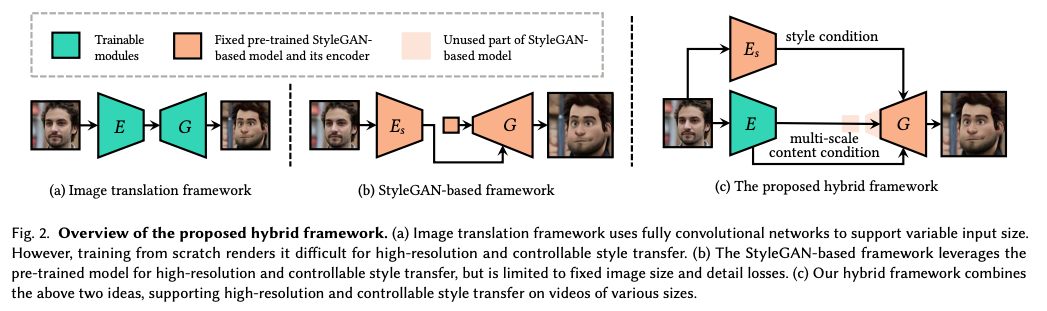
VToonify 结合了基于 StyleGAN 的框架和图像转换框架的优点,实现了可控的高分辨率人像视频风格转换。
项目地址:
https://github.com/williamyang1991/vtoonify
2DreamFusion
一句描述生成图像,text2img 这类算法我介绍过很多次。
最近也有很多新的研究成果,比如 clip2latent:

项目地址:
https://github.com/justinpinkney/clip2latent
不过,它不是我们今天的主角,仅仅是 2D 图像的生成已经无法满足研究者们了。
一句描述生成 3D 模型,Google 发布新作品。
文本描述直接生成 3D 模型,这个挺强的,效果优化好,又是一款创作利器。

比如输入:
a high quality photo of a pineapple
我们就可以得到这样一个 3D 模型,可以查看它的各个角度:
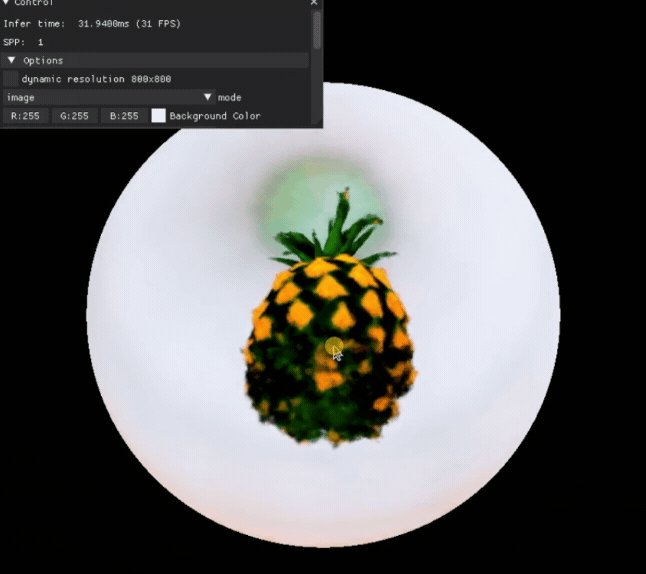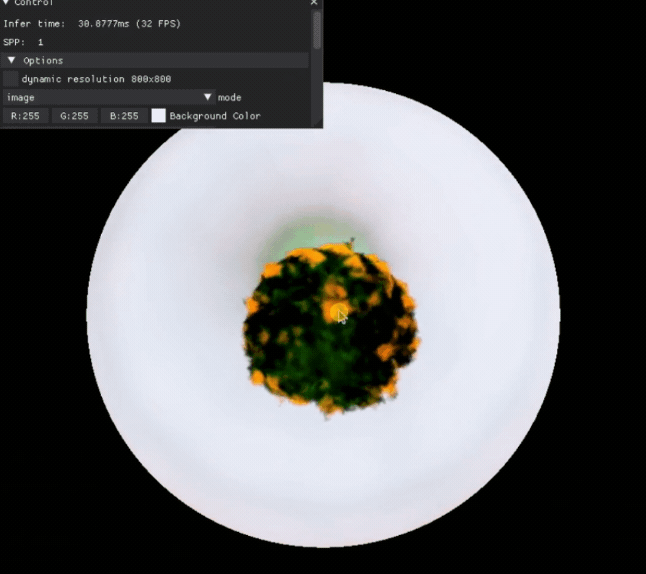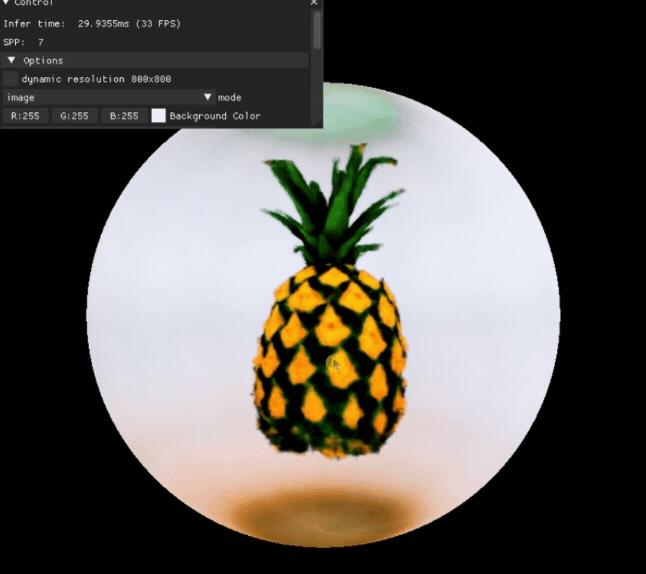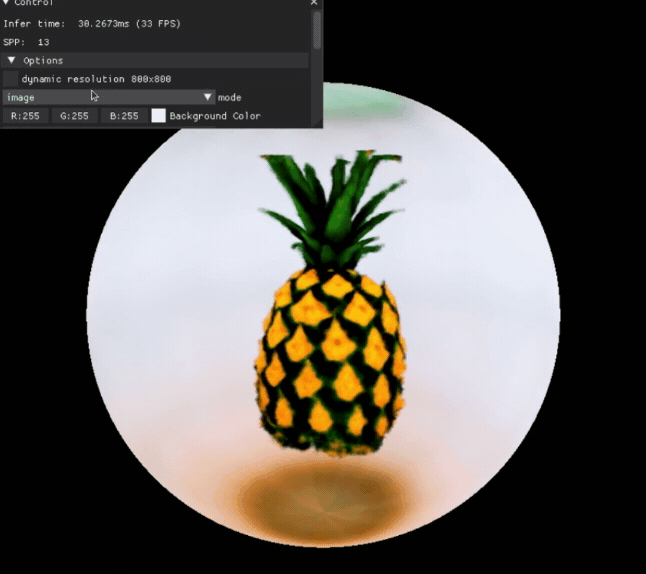
也可以对一些 3D 模型的属性进行编辑:
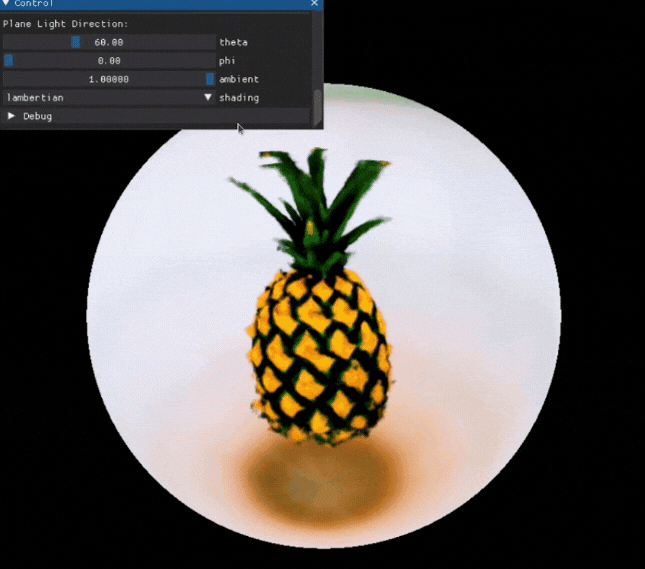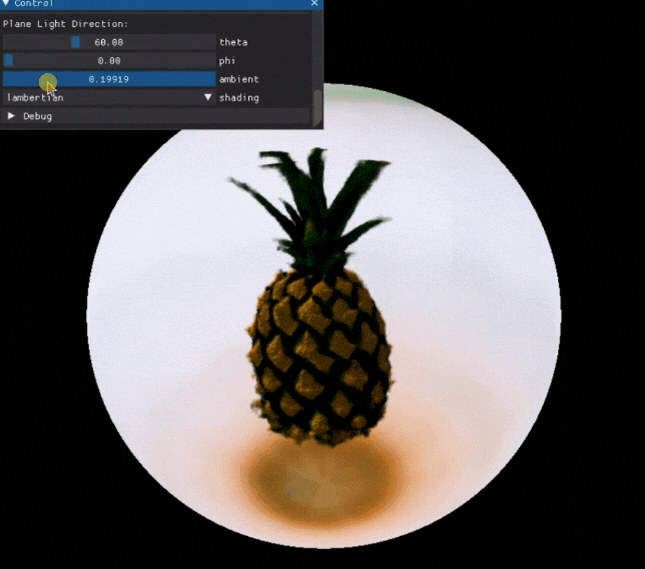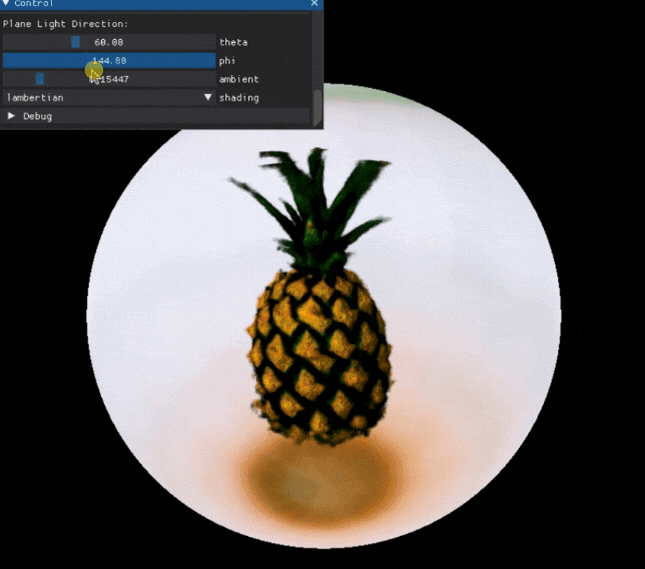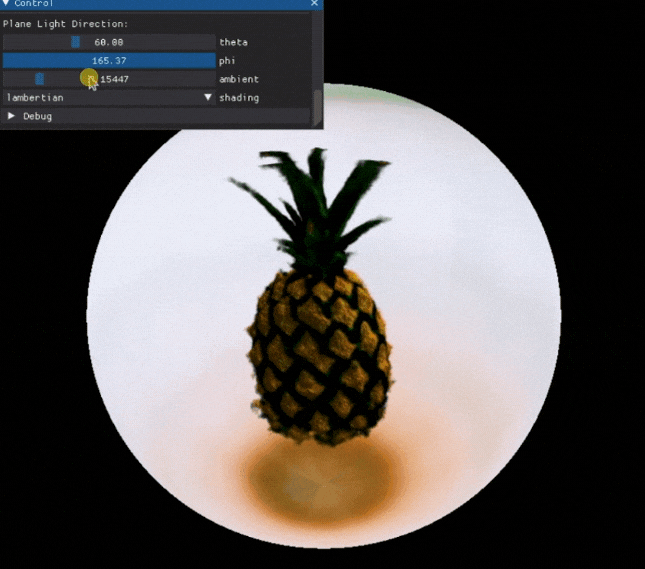
项目还提供了 Colab ,可以快速体验,感兴趣的小伙伴可以试一试。
项目地址:
https://github.com/ashawkey/stable-dreamfusion
3MDM
续 GAN 之后,大放异彩的是扩散模型。
除了生成图像,还可以生成动作。
比如Human Motion Diffusion Model,人体运动扩散模型,简称 MDM。
我们直接看下效果:


这东西有什么用呢?
要知道,无论做游戏,还是拍电影。
在做特效时,演员需要穿上特制的服装,贴上 marker,在动捕系统的覆盖下完成表演。
后期制作时,特效师将采集到的肢体动作和面部表情重定向到虚拟角色中,然后经过不断的后处理让虚拟人的动作尽可能真实。
因此,动作捕捉+重定向+后处理涉及大量的人工操作,过程十分烧钱。
有了这类动作生成模型,就能够快速又真实的生成特定的动作,大大节省成本。
话说,我还蛮期待真正的元宇宙时代的到来。
项目地址:
https://github.com/guytevet/motion-diffusion-model
4絮叨
3D 相关的研究多了起来,感兴趣的小伙伴都可以看一看。
今天就聊这么多吧,我是 Jack,我们下期见~
