
【NLP】再见了,提示~ 谷歌发布自适应提示方法,从此告别提示工程!

作者 | 谢年年、ZenMoore
大模型虽好,但却存在着一个恼人的问题:大模型回答得好不好,取决于我们问题问得怎么样。一个好的、详细的问题往往可以产生惊人的效果...
所以... ChatGPT 问世之后,最火的书可能不是《ChatGPT 技术原理》,而是《提示工程(Prompt Engineering)指南》(如何让 ChatGPT 更能听懂你的问题)。
一时间,全球人民都捧起了这本“咒语”教程,开始背诵各种各样的“施咒”技巧,比如“Let's take a breath...”,比如“You are my grandma...”,比如...
但是够了!真正的人工智能是不需要解释的,你解释得越多,智能就越智障。理想的情况是,大模型可以帮你对问题进行合理的解释,帮你把一个简陋的问题变成一个好问题,就像 DALL·E 3 的原理那样(p.s., DALL·E 3 使用 GPT-4 来优化用户提示,从而提升图像和用户需求的一致性)。
幸运的是,最近谷歌发布了一篇博客,一口气介绍了两篇相关论文,可能有望帮助我们摆脱繁琐的提示工程...
文章概览
LLM在少样本学习和零样本学习中所展现的问题解决能力令人惊喜,这大大降低了对标注数据的强依赖性。仅需一点点prompt魔法,就可以获得不错的效果。
比如零样本方法可以直接提出需求而不需要提供样例示范,其操作简单且普适性强,但对模型的指导完全依赖模型内部知识,性能通常较弱。
少样本学习相比零样本来说,通过提供示范能更好地指导LLM输出答案,但前提是给出的是一个高质量的示范,否则可能比没有示范还要糟糕。
来看一个数学推理问题的例子:给问题添加一个正确的示范可以引导出对测试问题的正确解答(Demo1与问题),而添加一个错误的示范(Demo2与问题,Demo3与问题)会导致错误的答案。其中Demo2是一个正确但推理过程重复的示范,这也导致了最终输出重复;Demo3提供的则是一个答案错误的示范。

由此可见,样本示范的选择对LLM生成质量有很大的影响。
但对于复杂任务来说人工构造高质量示范样本难度很大,特别是对于需要领域知识的任务,如长文章摘要或医疗问题回答。因此自动生成可靠示范是非常有必要的。
为了解决这个困境,谷歌团队提出了一种名为 Consistency-Based Self-Adaptive Prompting(COSP)的方法,无需人工构造样本,仅使用无标签样本(通常容易获取)和模型自身的预测输出,即可构建LLM的伪示范,在推理任务中大大缩小了零样本和少样本之间的性能差距。同时本文还将这个思想扩展到广泛的通用自然语言理解(NLU)和自然语言生成(NLG)任务,在多个任务上展示了其有效性。这两篇工作分别被 ACL2023 和 EMNLP 2023 接收。
谷歌博客:
https://blog.research.google/2023/11/zero-shot-adaptive-prompting-of-large.html
论文一标题:
Better Zero-shot Reasoning with Self-Adaptive Prompting
论文一链接:
https://aclanthology.org/2023.findings-acl.216/
论文二标题:
Universal Self-Adaptive Prompting
论文二链接:
https://arxiv.org/pdf/2305.14926.pdf
论文一:COSP
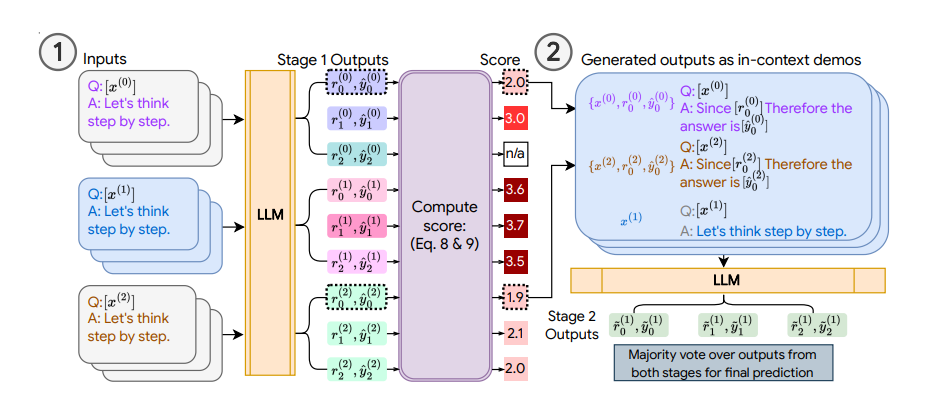
如果LLM对自己的答案很“自信”,那么应该在多次调用下输出相同答案,如果是这样,就说明该答案更可能是正确的,其置信度就比较高。因此可以考虑使用高置信度的输出及其输入作为伪示范。之所以叫做伪示范,是因为示范样例的答案仍然是LLM生成的并且没有经过真实答案检验。
基于此设想,COSP 方法的步骤如下:
-
将每个无标签的问题输入到LLM中,通过多次采样,模型将获得多个包含问题、生成的推理过程和答案的示范,并为其分配一个分数,以反映答案的一致性。输出次数越多的答案分数越高。
-
除了偏好更一致的答案外,COSP还惩罚回答中的重复问题(即重复的词语或短语),并鼓励选择多样性的示范。将一致的、非重复和多样化输出的偏好编码为一个评分函数,该函数由三个评分的加权和组成,用于选择自动生成的伪示范。
-
将伪示范与测试问题一起输入LLM中,并获得该测试问题的最终预测答案。
论文二:USP
COSP专注于推理问答任务,这些问题有唯一答案很容易测量置信度。但是对于其他任务,比如开放式问答或生成任务(如文本摘要),则会变得困难。为了解决这个限制,作者引入了USP(Uncertainty-based Self-supervised Prompting),将该思想推广到其他常见的NLP任务上。
选择伪示范的方法因任务类型变化而有所不同:
-
分类(CLS):LLM生成预测,使用神经网络计算每个类别的 logits, 并基于此选择置信度较高的预测作为伪示范。
-
短文本生成(SFG):这类问题类似于问答任务,可以使用COSP中提到的相同步骤进行处理,LLM生成多个答案,并对这些答案的一致性进行评分。一致性较高的答案被选择作为伪示范。
-
长文本生成(LFG):这类问题包括摘要和翻译等任务,通常是开放式的,即使LLM非常确定,输出也不太可能完全相同。在这种情况下使用重叠度度量,计算不同输出对于相同查询的平均ROUGE分数,选择具有较高重叠度的作为伪示范。

总的来说,在第一个阶段,针对不同的任务类型,调用语言模型对无标签数据生成输出,并基于 logit 熵值、一致性或者重叠度等指标进行置信度打分,最后选择置信度高的样本作为上下文示范。在第二阶段,将这些伪的上下文示范作为语言模型输入的一部分,对测试数据进行预测。
实验结果
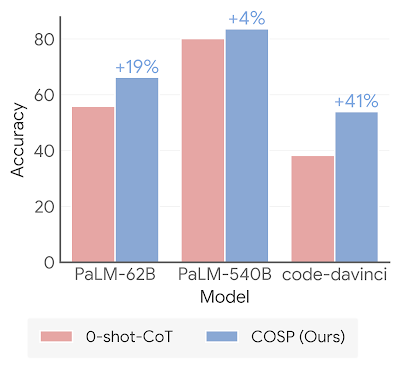
▲图1
如图1所示,通过三个LLM在六个算术和常识推理问题上进行比较,相同的计算资源条件下,COSP方法在零样本设置下取得了更好的性能。通过自动生成的示范和策略性的选择示范,COSP能够提供更一致和相关的答案,从而提高了模型的推理能力。
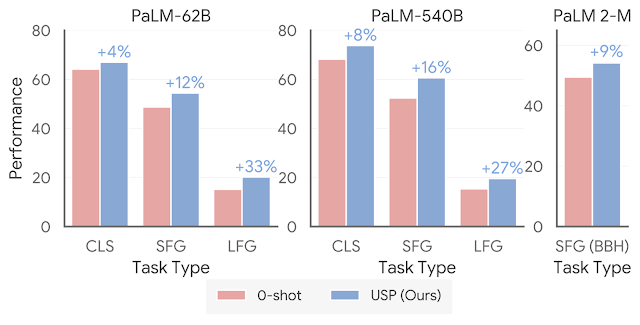
▲图2
如图2所示,对于USP,作者将分析扩展到更广泛的任务范围,包括超过25个分类任务、短文生成和长文生成任务。可以看到在不同的任务中,USP超越了zero-shot基准。

▲图3
本文还针对BIG-Bench Hard任务进行了测试,如图3所示,每一行代表一个任务。以前LLM在这些任务中表现不如人类,而现在大部分任务上LLM都超越了人类的平均表现。而USP同样优于基线,即使是与人工制造的提示样本(图中3-shot)相比也具备一定的竞争力。
结论
总的来说,本文提到的COSP和USP方法通过自动构造伪样本的方式弥合了零样本与少样本之间的差距,对自然语言理解与生成一系列广泛的任务都适用。
加上前几天,我们解读的一个小妙招从Prompt菜鸟秒变专家!加州大学提出PromptAgent,帮你高效使用ChatGPT!文章中提到模型可以自动迭代优化Prompt,将平平无奇的prompt打造成媲美专家设计的prompt。现下,模型还可以自动生成伪示范,提升零样本的能力。继续发展下去,prompt工程师一职会不会也快要失业了呢?

往期精彩回顾
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)