
关于深度学习发展的必然及未来的思考
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


来自 | 知乎
作者 | Flood Sung
地址 | https://zhuanlan.zhihu.com/p/375226190
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
1 前言
凯文凯利的《必然》相信很多朋友都有读过,里面描述了很多科技发展的必然趋势。那么这里,我们想仅对深度学习领域的发展进行思考,看是不是里面也存在着必然。我们会先探讨一些已知的必然,然后再聊聊一些未来的必然。
下面的观点仅代表个人看法,如有不足敬请批评指正
2 深度学习是AI的必然
在过去,人们对于符号主义还是连接主义是有争论的,但现在深度学习取得成功让连接主义取得了胜利。
这里的必然在于人写不出所有的规则和特征,所以用神经网络作为载体,通过数据去拟合。
未来要实现AGI还需要很多新的技术,但如OpenAI的首席科学家ilya sutskever 在一次访谈中说的,AGI一定会是以深度神经网络的形式产生。
3 深度学习的特性让大数据,大网络,高算力的发展成为必然
这一条在现在看来是毋庸置疑的。早在深度学习刚火起来的那几年,吴恩达就已经宣传了这三点的重要性。
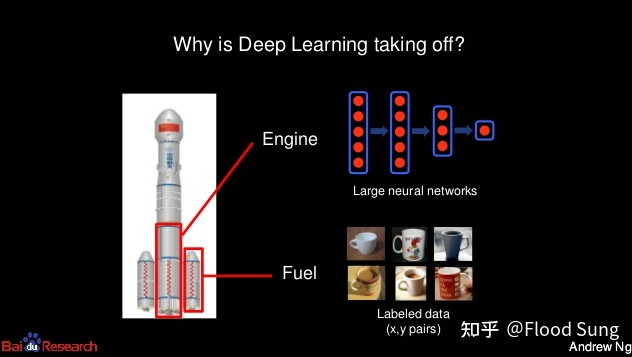
但就算如此,恐怕大多数人仍然会对网络模型的爆炸式增长产生的效果感到震惊,比如去年的GPT-3。
而接下来的几年,网络模型的大小仍然会继续加大,直到神经网络的连接数超过人脑神经元的连接数,至于会产生什么效果,我们拭目以待。
为什么是这样?
因为深度学习本质是基于统计学,深度学习做的事情就是对所有的数据进行统计,只是神经网络能够对高维数据进行复杂的统计,从而输出最优的概率统计结果。所以,数据越多越全面,效果就有可能越好。
并且,神经网络还具备泛化能力,看到相似的场景也能输出相似的概率,从而让深度学习进入实用化阶段。
那么,这个时候,如何产生巨量的数据进行训练呢?
监督学习需要对数据进行标注,而标注需要靠人工,这是需要成本的。这就意味着标注的数据是无法爆炸式增长的,也因此,图灵奖得主Yann Lecun在几年前就提出:
2 无监督/自监督学习的发展是必然
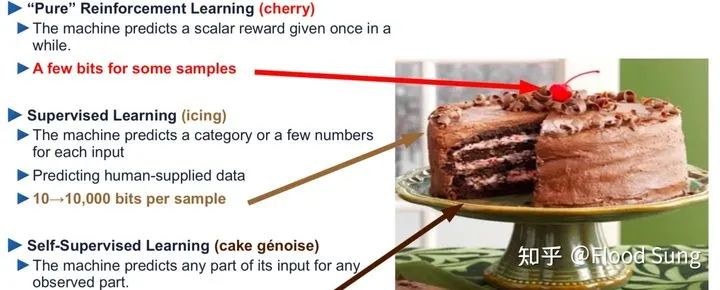
这几年学术界的发展完全印证了这一点,为什么大模型率先在NLP上取得成功,因为NLP使用的语言数据可以不需要标注。
不过Yann Lecun对强化学习的判断并不完全对。在现实世界,要获取有用的样本很难,但是在虚拟环境,样本是可以无尽获取的,所以这几年强化学习依然取得了巨大的进步。无论是AlphaStar还是OpenAI Dota Five,都是在虚拟环境下每天训练几百万,几千万局。
我们只能说强化学习的样本利用低是对的(Sample Inefficiency)。
虽然强化学习有这样的问题,但依然无法阻止它成为下一个必然!
3 决策系统必然要使用深度强化学习
这一条和深度学习是AI的必然是一样的道理。
人是无法手工写出所有的规则和特征的!
以自动驾驶为例,目前的自动驾驶主要还是以人工规则为主,只是在视觉感知端使用了深度学习。但是由于人工规则的局限性,就算使用了几万个if语句,也仍然无法保证自动驾驶系统能够处理所有的corner case。对于自动驾驶来说,如果这个系统无法达到99.9999999%的有效性,就无法真正意义上的脱离人工让其完全自己托管。这可以很容易计算,就算自动驾驶1000公里需要人介入一次,那每1000公里可能就有造成一次事故,这就很可怕了。
如何解决?只能最终将希望寄托在深度强化学习+模仿学习上,让AI在虚拟环境中去试错,去遍历所有的可能,去跑个1亿亿公里来学习。
自动驾驶只是机器人的一种形态,其他机器人的应用也类似,比如机械臂的抓取,需要99.99%的准确率才有使用的价值,根本上还是要让人工介入的次数足够少,从而真正意义上不需要人工,降低成本。
基于这样的判断,我们有了下面的必然:
4 Sim2Real是通往完全自动驾驶及其他通用机器人的必然
现实世界不可能提供足够的数据,所以我们只能通过在虚拟环境中训练,再迁移到现实环境。
虚拟环境好处很多,比如可以加速,可以大规模并行,可以不担心安全问题。
但要实现Sim2Real,却对虚拟环境的真实性提出了极高的要求。
比如自动驾驶的训练,我们需要能够构建出和真实别无二致的场景,去覆盖所有的场景!
所以,这带来了下一个必然!
5 AI在虚拟世界的应用要领先于现实世界
这里的原因不仅仅是因为现实世界的应用依赖于虚拟世界,同时也是深度学习本身的内在缺陷。
什么缺陷呢?
深度学习受益于数据,也依赖于数据,导致它存在的问题是无法自己推导出规则,从而在完全的ood(Out of Distribution)上work!
也就是如果测试的时候样本从来没见过,也不是之前的样本能组合出来的,那么神经网络就会傻掉!
这和人很不一样,人形成了一套符号系统,所以给出规则就懂得使用规则。目前的深度学习还无法自己基于样本产生有效的符号系统来实现这种泛化。
也就是说深度学习要成功,其实就只有走大数据这条路,并且是要尽可能的穷尽所有可能,才能让效果达到很好,让corner case出错的概率降到足够低。
所以
6 凡是对Corner Case要求很高的AI应用,都很难落地
简单点说就是出点错也没事的AI好落地,否则很难落地。
自动驾驶,机器人这些现实应用就是,出个错影响很大。
而NLP,虚拟世界中的游戏AI,特效这些则影响没有那么大。
这也就印证了第5条的必然。我们可以看到AI已经广泛的应用到搜索,游戏,视频特效等领域,并带来了巨大的商业价值。
以深度强化学习为例,在游戏AI中得到了真正意义上的落地,如果把所有使用了深度强化学习Agent的游戏算上,估计每天被调用上亿次,这是难以想象的。
同样,GAN在视频特效上得到了巨大的应用,一个火的特效可以被观看几十亿次。
基于前面的几点,虚拟世界的发展非常重要,现实世界的AI应用,特别是机器人上的应用,极度依赖于虚拟世界,因此
7 Metaverse将先于机器人革命出现
下面两图概括了Metaverse和机器人所需的AI技术:
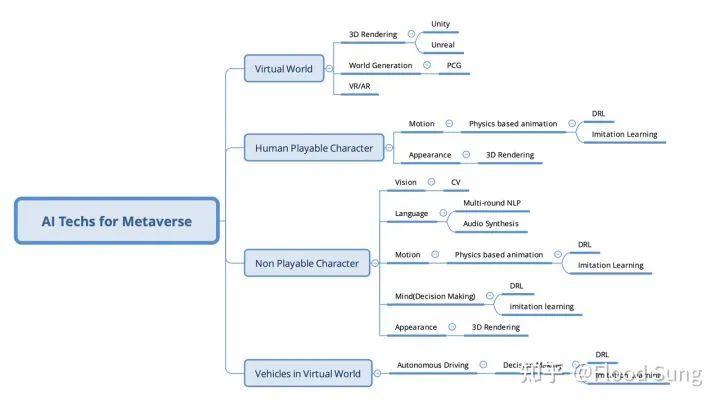
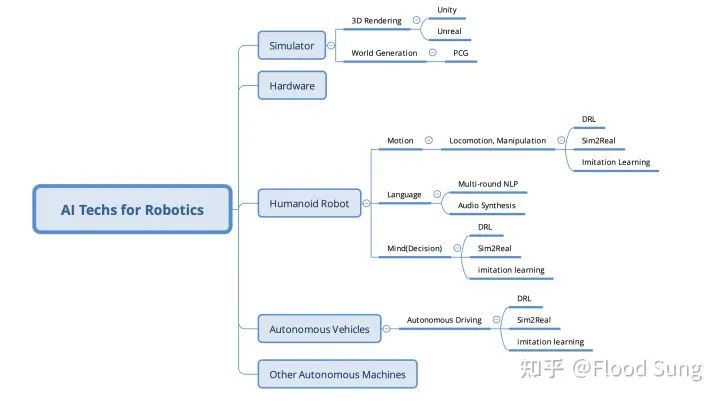
几乎是共通的,相信很多朋友会有不同意见,上图完全建立在Sim2Real的必然上!
这样的技术路线和西部世界里的做法是一模一样的。西部世界真是一部前瞻性极强的硬核科幻。
这里多聊几句Metaverse!
Metaverse是永恒的虚拟世界,除了逼真的虚拟环境给予其外在,大量智能的虚拟人/机器人才是其内核。这和目前游戏里的NPC一个道理。在3A游戏如GTA V中,NPC是一个必不可少的角色,在虚拟世界中充斥着大量的NPC来形成整个虚拟世界观与故事线。一个仅有人类的虚拟世界无法构造真正的Metaverse!
(当然,当前每个人对Metaverse的看法都不尽相同,这里仅一家之言)
鉴于Metaverse和机器人都对AI有着全方位的需求,我们可以得到下一个必然:
8 AGI将在Metaverse的发展中诞生,然后作用于现实世界
这里的AGI我们定义为具备完全拟人的语言,姿态,动作,行为,能够通过图灵测试。我们依然可以以西部世界里的机器人作为AGI的代表。
在发展Metaverse的NPC的时候,我们需要一步一步的改进里面的Vision,Language,Motion,Mind,这都是AGI的核心组件,有些组件也可以直接作用于现实世界比如Language,有些则需要更多的发展来实现sim2real。
9 小结
有了上面的分析,我们会越来越明白机器人革命道阻且长,需要很多组件的逐步完成。虽然目前我们也已经看到了很多机器人基于cv的应用,但离完成更复杂任务还很远。
但这也许不是什么坏事。
Metaverse才是下一个世代的主题,拥抱它并发展它。也许这里面对的社会问题比机器人革命到来面对的问题更大,但似乎技术是无法阻挡的,人类在不断的将自己推进深渊或者通往下一个前所未有的光明!
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!