
Facebook 的 AI 识菜谱,把皮卡丘认成了煎蛋……|技术前沿洞察
大家好,一周技术前沿洞察又来啦!不少小伙伴说很喜欢这个栏目,小探们在找的时候也觉得,不仅有趣,而且实实在在地促进科技进步。
这周有啥技术进展呢:从 6G 到海水淡化,从仿真 AI 视频到打通机器人的视觉和触觉,一起来看!
大公司
诺基亚,爱立信和韩国SK Telecom合作开展6G研究
5G 刚刚开始落地,有关 6G 的信息就已经曝光。 近日,韩媒称韩国 SK 电信公司已经与两家欧洲电信设备制造商达成协议,将联手提升商用 5G 网络性能,并开发 6G 相关技术。
SK 公司在本月 12 日和 13 日分别与芬兰诺基亚公司和瑞典爱立信公司签署了谅解备忘录。根据协议,双方将共同开发6G核心技术,以便在下一代移动通信技术领域抢占先机并探索新的商业模式。
除了 6G,这些合作伙伴还将研究改进“超可靠、低延迟”的 5G 网络,以及分布式多输入多输出(MIMO),人工智能(AI),28GHz频段和5G独立(SA)组网在商业网络中的应用。

(图自telecomstechnews)
感兴趣的可以点击原文查看:
https://www.telecomstechnews.com/news/2019/jun/17/nokia-ericsson-sktelecom-6g-research/
Facebook: AI 能看图识菜谱了!
近日,Facebook AI 开源了一个 AI 系统,可以通过分析食物图片,判断需要用到的食材和制作过程,最后生成一份菜谱。

(由饼干图片生成的菜谱,图片来源 Facebook AI)
对于 AI 来说,从图片中推导出菜谱主要需要两方面的知识:一方面是搞清楚图片中是什么食物;另一方面则是推断出食材和配料的加工过程。传统方法倾向于将这一过程简化为匹配,系统首先判断出图片中是什么食物,再去已有数据库中搜索和匹配相应的菜谱。如果没有准确的对应菜谱,就会匹配一个最相似的。这样的方法依赖大量的菜谱数据,而且缺乏灵活性和多样性。
Facebook 研究人员采用了一种新的思路,把从图片到菜谱的过程视为一个条件生成系统。给定一张食物图片,AI 系统会先判断它包含哪些食材和配料,进而以图片、食材和配料表为条件,推导出它们的加工方式,最后根据加工方式的可能性从高到低排列,形成很多份菜谱。
不过有意思的是,这个 AI 系统可以接受和分析任何图片。比如上传个月亮图片,被识别成“家常煎饼”,上传个 iPhone,被当成“家常冰凝胶”,至于皮卡丘,则被当成了“煎蛋”。。。

所以问题来了,如何把皮卡丘能煎得好吃呢……
感兴趣的可以点击原文查看:
https://ai.facebook.com/blog/inverse-cooking/
Facebook发布软件框架,使编程机器人变得更容易
如何让机器人能够像人一样精准的摆动胳膊,是一项难题,这也是不少公司在寻找更好的编程机器人的一个方向。近日,Facebook 与卡耐基梅隆大学合作,推出了一种新的机器人开源框架,称为 PyRobot。
PyRobot 旨在帮助研究人员和测试人员在几个小时内就能上手使用机器人。如果说传统的机器人编程就像是在使用 DOS 操作系统,那么 PyRobot 就像是在使用 macOS 一样简单流畅。

(通过PyRobot编码LoCoBot,让机器人可以准确摆动手臂,动图来自Wired.com)
PyRobot本身并不是一个底层操作系统,而是机器人操作系统(简称ROS)的上层,与亚马逊的 RoboMaker 类似,可以帮助开发者更好的编程机器人。
更多技术细节可以访问:
https://ai.facebook.com/blog/open-sourcing-pyrobot-to-accelerate-ai-robotics-research/
美国高校
机器人的视觉和触觉感官,能够互通了!
对于人类来说,触觉帮助我们感受物理世界,而视觉帮助我们看到物理世界的样子。但是,对于机器人来说,当前视觉和触觉还是分离的。它们的视觉感知和触觉感知还不相通。
为了弥合这种差距,来自麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员研发了一种技术,使机器人可以通过触觉信号推测出物体的样子;同样的,通过视觉信号,推测出物体的触感。
该团队使用摄像头记录了近 200 件物品,如工具,家用产品,织物等,并让机器人触摸这些物体超过 12,000 次。随后,他们将这 12,000 个视频片段分解为静态帧,编制成为包含 300 多万个视觉/触觉配对图像的数据集“VisGel”。
基于这个数据集训练后,机器人可以基于视觉输入,推测出逼真的触觉信息;或者,通过触觉信息的输入,推测出是什么物体被碰触了,以及是哪个部位被碰触了。该研究团队使用的机器人手臂名叫 KUKA,触觉传感器名为 GelSight,是由麻省理工学院的另一个小组设计。
视觉和触觉这两种感官的结合,可以增强机器人的能力,并减少其在涉及操纵和抓取物体的训练任务时可能需要的数据。
感兴趣的可以点击原文查看:
https://www.csail.mit.edu/news/teaching-artificial-intelligence-connect-senses-vision-and-touch
莱斯大学将太阳能海水淡化系统的产量提高了50%
莱斯大学纳米光子学实验室(LANP)的研究人员表示,他们可以通过添加廉价的塑料镜片将太阳光浓缩到“hot spots”上,从而将太阳能海水淡化系统的效率提高了 50% 以上。
(注:hot spots 是指将一定量的光能能挤压到一个很小很小的体积的一种状态)

该项研究的主要研究员表示:提高太阳能驱动系统性能的典型方法是增加太阳能聚光器并带来更多光线。而他们的方法有个最大的优势是使用相同数量的光,然后可以廉价地重新分配这种能量,从而大大提高净化水的产量。
感兴趣的可以点击原文查看:
http://news.rice.edu/2019/06/17/hot-spots-increase-efficiency-of-solar-desalination/
“Deep Fakes”的克星:伯克利、南加大联手开发识别伪造视频的方法
目前,越来越多的研究人员在努力寻找准确识别 Deep Fakes 的假视频的方法。而来自加州大学伯克利分校和南加州大学的研究人员在这场竞赛中暂时走在了前面。
他们开发了一种方法,在大规模深度伪造数据集上进行评估,准确度达96%。这种方法适用于各类视频伪造技术,包括 Deep Fakes,人脸交换和 face2face 等。研究论文中表示,他们的检测方法的先进程度领先于内容伪造者的技术更迭能力。
研究人员使用了两个步骤:首先,他们输入了数百个经过验证的个人视频示例,把每个视频放在一起;然后,他们使用称为卷积神经网络的深度学习算法,确定了人脸的特征和模式,特别注意眼睛如何闭合或嘴巴如何移动。检测中,他们将新输入的视频与之前模型的参数进行比较,以确定一段内容是否超出常规,从而判断视频是否是伪造的。
所以,视频造价能被杜绝了吗?
更多研究详情,欢迎访问两所大学的官方博客:
https://news.berkeley.edu/2019/06/18/researchers-use-facial-quirks-to-unmask-deepfakes/
斯坦福大学跟英特尔合作:利用声波“看见”墙后物体
试想,当你站在墙前,想看到拐角处视线范围之外的事物,除了伸长脖子或者走过去,还有别的方法吗?
传统的非视距成像技术利用角落或障碍物周围墙壁反射的光波,重建出图像。但这种光学方法中用到的硬件非常昂贵,且对距离的要求较高。那么,如果不使用光波,转而使用声波呢?
来自斯坦福大学与英特尔实验室的研究人员构建了一个硬件原型 :一个装有现成麦克风和小型汽车扬声器的垂直杆。
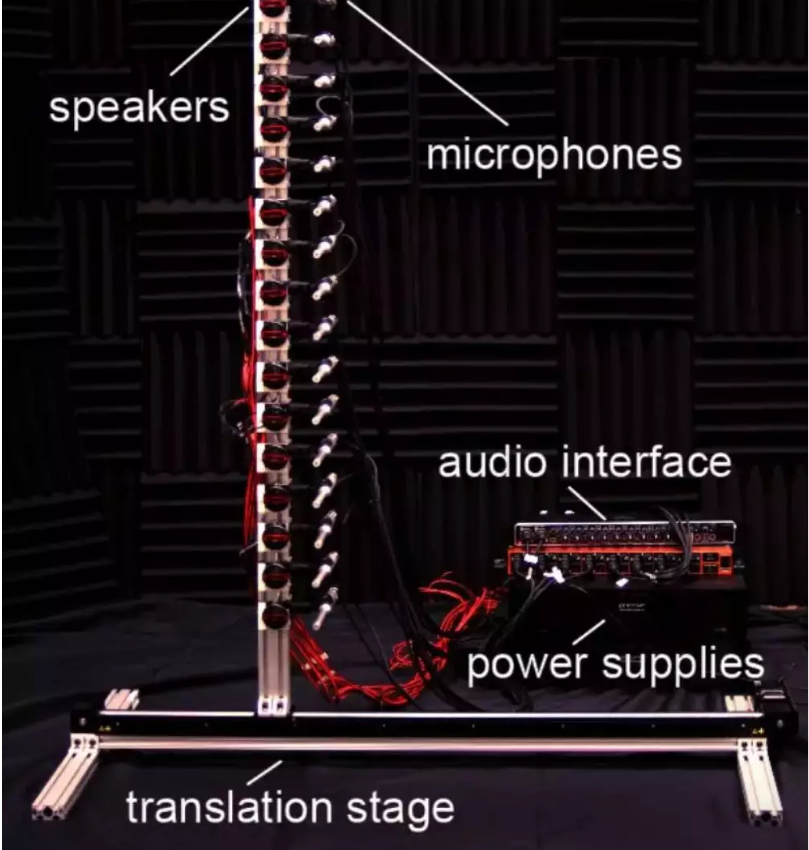
在实际操作中,扬声器会发出一串啾啾声,声音以一定角度弹到附近的墙壁上,然后撞到另一面墙上的一张字母 H 形状的海报板,最后声音以同样的方式反弹回麦克风。接下来,研究人员使用地震成像的算法,对字母 H 的外观进行粗糙重建。
结果显示,声学方法能够重建出两个字母的图像,且时间比光学方法高出 2 倍。这项技术距离应用还需要数年的时间,但作者表示,该技术的超声波版本最终可能会应用于自动驾驶汽车上,用来探测看不见的障碍物。
感兴趣的可以点击原文查看:
https://www.sciencemag.org/news/2019/06/scientists-use-sound-see-around-corners
海外高校
用散射光来重建物体形状:计算机视觉技术的又一步

(图自:www.cs.cmu.edu)
我们肉眼看到的大部分内容,都来自从物体直接反射到眼睛的光线;镜头对物体形状的捕捉也是如此。利用计算机视觉技术来重建物体的形状,以往也都是基于直接反射的光线。
微弱的散射光虽然可能会到达眼睛或镜头,但会被更直接,更强大的光源冲刷掉。 而 NLOS 技术的研究者们则在试图从散射光中提取信息 ,并生成场景、物体,特别是物体中不被直接看到的部分。
而卡内基梅隆大学的研究人员近日研发出可以用特殊光源和传感器来通过非直射光重建物体的形状的技术。
卡内基梅隆大学,多伦多大学和伦敦大学学院的研究人员表示,这种技术使他们能够非常细致的重建图像。作为实验,他们重建了乔治·华盛顿在一枚硬币上的轮廓。
卡内基梅隆机器人研究所助理教授 Ioannis Gkioulekas 说,这是研究人员首次能够通过散射光计算出毫米级和微米级弯曲物体的形状。虽然到目前为止,科学家们还只能在相对较小的区域内实现这种细致程度,但这为计算机视觉科学家们正在研究的更大规模的 NLOS 技术提供了重要的新组件。
感兴趣的可以点击原文查看:
https://www.cs.cmu.edu/news/researchers-see-around-corners-detect-object-shapes
伦敦帝国理工&三星:一张图、一段音频合成仿真 AI 视频
最近,来自三星人工智能研究中心和伦敦帝国理工学院的研究人员提出一种新型端到端系统,仅凭一张照片和一段音频,就可以生成新的讲话或唱歌视频,而且视频主角不只是动嘴,整个面部表情都会有比较自然的变化。例如,通过将爱因斯坦演讲的真实音频片段和他的一张照片相结合,研究人员可以快速创建一个前所未有的演讲视频。

这个研究的“前身”是三星莫斯科 AI 中心和 Skolkovo 科学技术研究所的一项研究。在那项研究中,研究人员利用一张图像就合成了人物头像的动图,而且头像中的人物可以“说话”(只动嘴不发声),蒙娜丽莎、梦露等名人画像、照片都可以用来作为原料。
这次的新研究出现在了计算机视觉顶会 CVPR 2019 上。该方法生成的视频具备两大特点:1. 视频中人物嘴唇动作和音频完全同步;2. 人物面部表情自然,比如眨眼和眉毛的动作。