
谈谈 Kubernetes list/watch 的设计原理
kubernetes 的设计里面大致上分为 3 部分:
API 驱动型的特点 ( API-driven)控制循环( control loops)与 条件触发 (Level Trigger)API 的可延伸性
而正因为这些设计特性,才使得 kubernetes 工作非常稳定。
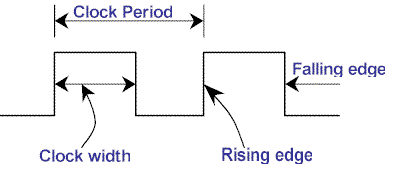
Level Trigger 与 Edge trigger
看到网上有资料是这么解释两个属于的:
条件触发(level-trigger,也被称为水平触发)LT 指: 只要满足条件,就触发一个事件(只要有数据没有被获取,就不断通知)。 边缘触发(edge-trigger)ET: 每当状态变化时,触发一个事件。
通过查询了一些资料,实际上也不明白这些究竟属于哪门科学中的理论,但是具体解释起来看得很明白。
LEVEL TRIGGERING:电流有两个级别,VH 和 VL。代表了两个触发事件的级别。如果将 VH 设置为 LED 在正时钟。当电压为 VH 时,LED 可以在该时间线任何时刻点亮。这称为 LEVEL TRIGGERING,每当遇到 VH 时间线就会触发事件。事件是在时间内的任何时刻开始,直到满足条件。
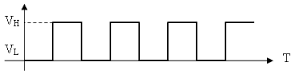
Edge TRIGGERING: 如图所示,会看到上升线与下降线,当事件在上升/下降边缘触发时(两个状态的交点),称为边缘触发(Edge TRIGGERING)。
如果需要打开 LED 灯,则当时钟从 VL 转换到 VH 时才会亮起,而不是一家处在对应的时钟线上,仅仅是在过渡时亮起。
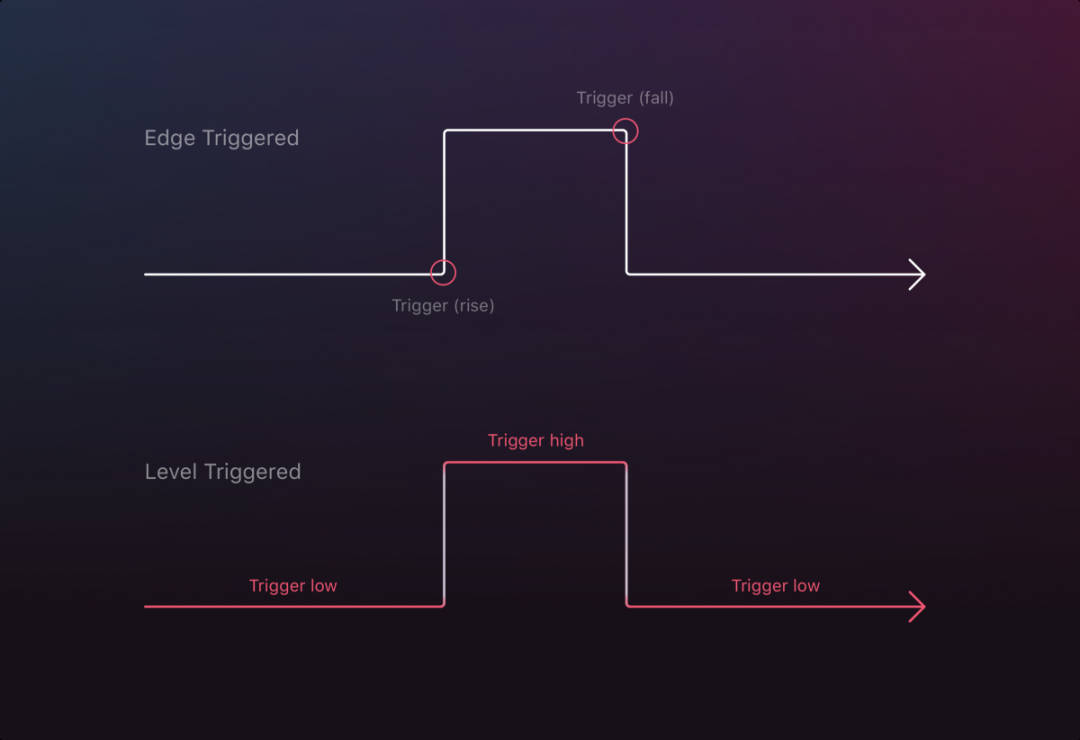
为什么 kubernetes 使用 Level Trigger 而不使用 Edge trigger
如图所述,两种不同的设计模式,随着时间形状进行响应,当系统在由高转低,或由低转高时,系统处在关闭或者不可控的异常状态下,应如何触发对应的事件呢。
换一种方式来来解释,比如说通过 加法运算,如下,i=3,当给 I+4 作为一个操作触发事件。
# let i=3
# let i+=4
# let i
# echo $i
7
当为 Edge trigger 时操作的情况下,将看到 i+4 ,而在 level trigger 时看到的是 i=7。这里将会从 ``i+4` 一直到下一个信号的触发。
信号的干扰
通常情况下,两者是没有区别的,但在大规模分布式网络环境中,有很多因素的影响下,任何都是不可靠的,在这种情况下会改变了我们对事件信号的感知。
如图所示,图为 Level Trigger 与 Edge trigger 的信号发生模拟,在理想情况下,两者间并没有什么不同。
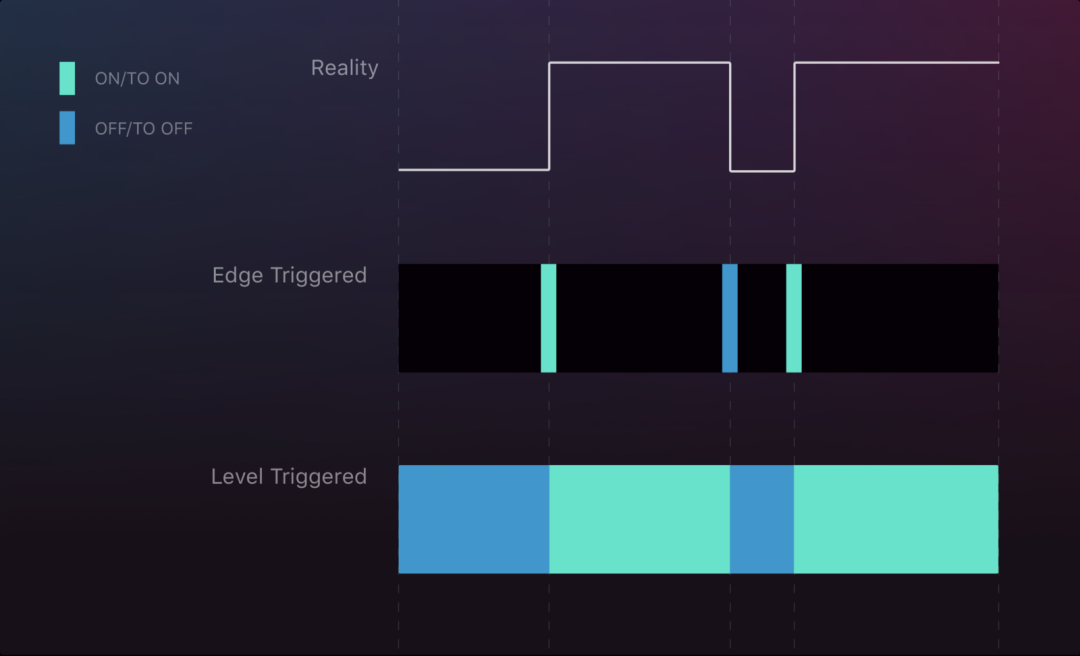
一次中断场景
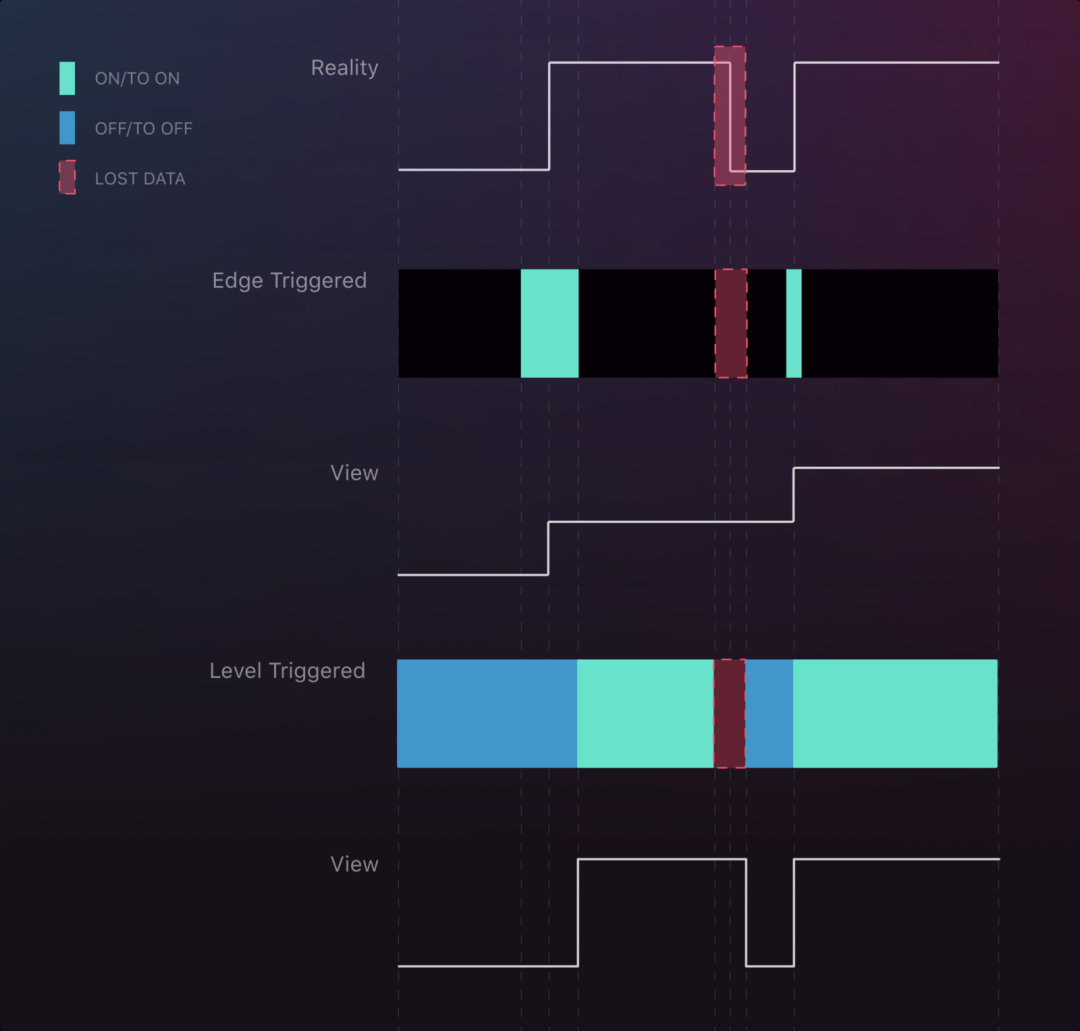
由图可知,Edge trigger 当在恰当的时间点发生信号中断,会对整个流产生很大的影响,甚至改变了整个状态,对于较少的干扰并不会对有更好的结果,而单次的中断,使 Edge trigger 错过了从高到低的变化,而 level trigger 基本上保证了整个信号量的所有改变状态。
两次中断的场景下
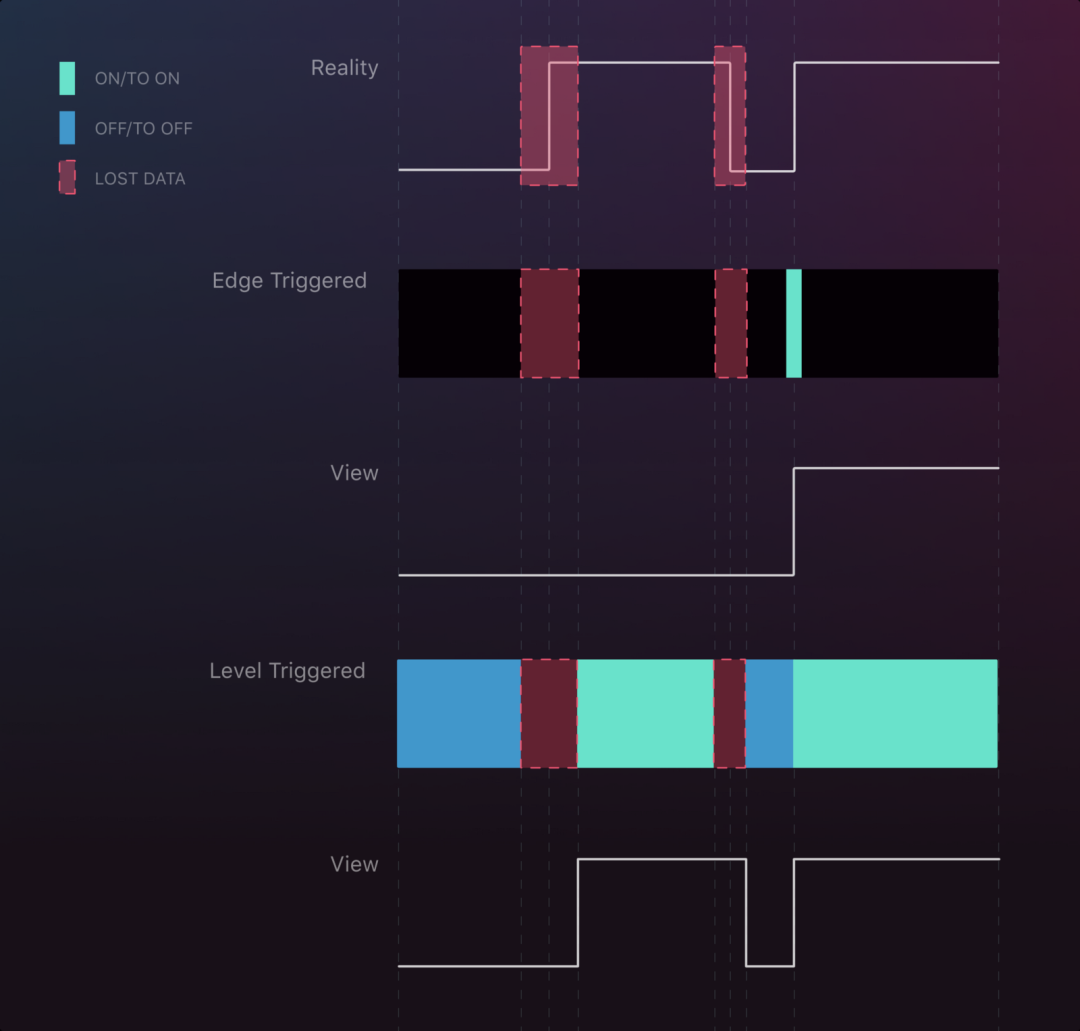
由图可看到,信号的上升和下降中如果存在了中断,Edge trigger 丢失了上升的信号,但最终状态是正确的。
在信号状态的两次变化时发生了两次中断,Level Trigger 与 Edge trigger 之间的区别很明显,Edge trigger 的信号错过了第一次上升,而 Level Trigger 保持了最后观察到的状态,直到拿到了其他状态,这种模式保证了得到的信号基本的正确性,但是发生延迟到中断恢复后。
通过运算来表示两种模式的变化情况
完整的信号
# let i=2
# let i+1
# let i-=1
# let i+1
# echo $i
3
Edge trigger
# let i=2
# let i+1
(# let i-=1) miss this
# let i+1
# echo $i
4
如何使理想状态和实际状态一样呢?
在 Kubernetes 中,不仅仅是观察对象的一个信号,还观察了其他两个信号,集群的期待状态与实际状态,期望的状态是用户期望集群所处的状态,如我运行了 2 个实例(pod)。在最理想的场景下,集群的实际状态与期待状态是相同的,但这个过程会受到任意的外界因素干扰被影响下,实际状态与理想状态发生偏差。
Kubernetes 必须接受实际状态,并将其与所需状态调和。不断地这样做,采取两种状态,确定其之间的差异,并纠正其不断更改,以使实际状态达到理想状态。
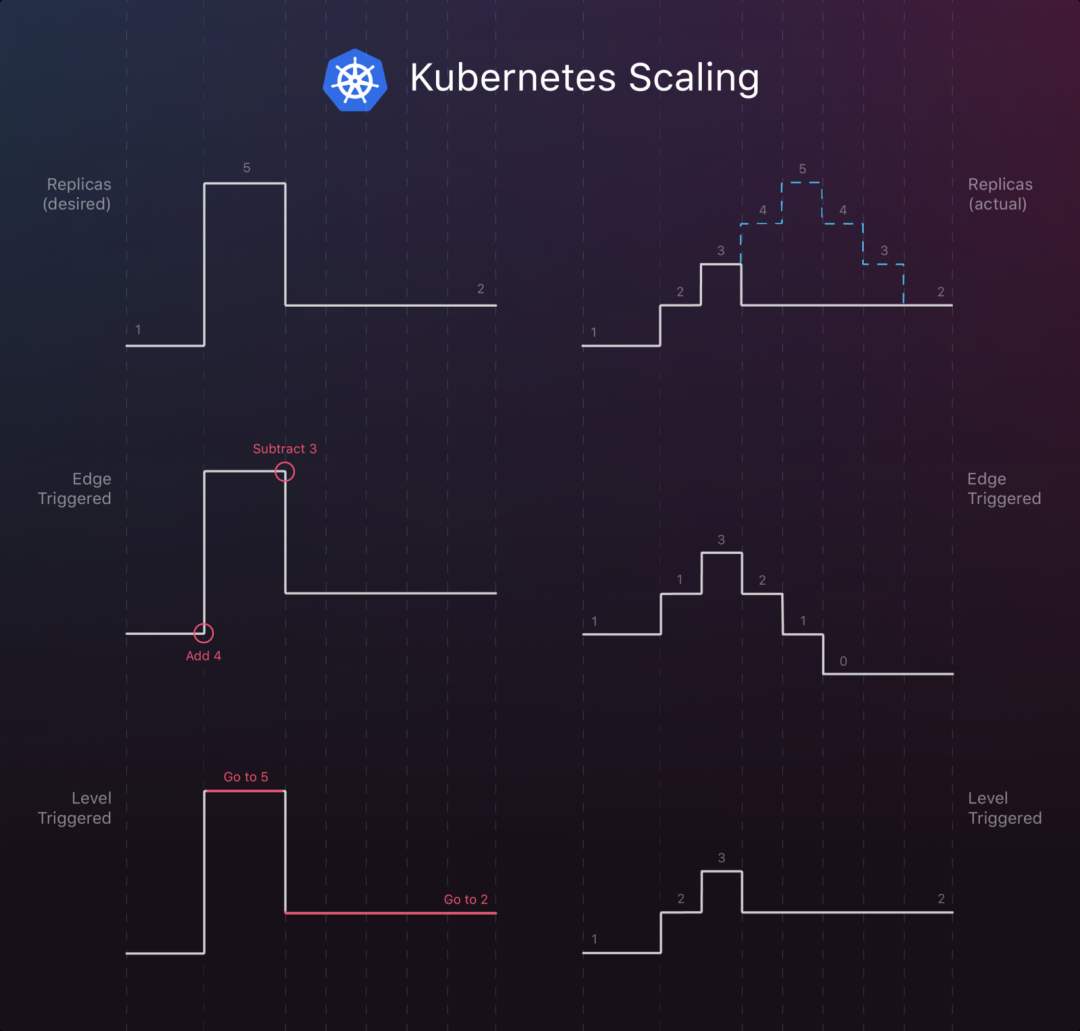
如图所示,在一个 Edge trigger 中,最终的结果很可能会与理想中的结果发生偏差。
当初始实例为 1 时,并希望扩展为 5 个副本,然后再向下缩容到 2 个副本,则 Edge trigger 环境下将看到以下状态:系统的实际状态不能立即对这些命令作出反应。正如图所述,当只有 3 个副本在运行时,它可能会终止 3 个副本。这就给我们留下了 0 个副本,而不是所需的 2 个副本。
# let replicas=1
# let replicas += 4 # 此时副本数为5,但是这个过程需要时间而不是立即完成至理想状态
# let replicas -= 3 # 当未完成时又接到信号的变化,此时副本数为3,减去3,很可能实际状态为0,与理想状态2发生了偏差
而使用 Level Trigger 时,会总是比较完整的期望状态和实际状态,直到实际状态与期望状态相同。这大大减少了状态同步间(错误)的产生。
总结
每一种触发器的产生一定有其道理,Edge trigger 本身并不是很差,只是应用场景的不同,而使用的模式也不同,比如 nginx 的高性能就是使用了 Edge trigger 模型,如 nginx 使用了 Level trigger 在大并发下,当发生了变更信号等待返回时,发生大量客户端连接在侦听队列,而 Edge trigger 模型则不会出现这种情况。
综上所述,kubernetes 在设计时,各个组件需要感知数据的最终理想状态,无需担心错过数据变化的过程。而设计 kubernentes 系统消息通知机制(或数据实时通知机制),也应满足以下要求:
实时性(即数据变化时,相关组件感觉越快越好)。消息必须是实时的。在 list/watch机制下,每当 apiserver 资源有状态变化事件时,都会及时将事件推送到客户端,以保证消息的实时性。消息序列:消息的顺序也很重要。在并发场景下,客户端可能会在短时间内收到同一资源的多个事件。对于关注最终一致性的 kubernetes 来说,它需要知道哪个是最新的事件,并保证资源的最终状态与最新事件所表达的一致。kubernetes 在每个资源事件中都携带一个 resourceVersion标签,这个标签是递增的。因此,客户端在并发处理同一资源的事件时,可以比较resourceVersion,以确保最终状态与最新事件的预期状态一致。消息的可靠性,保证消息不丢失或者有可靠的重新获取的机制(比如 kubelet和kube-apisever之间的网络波动(network flashover)需要保证 kubelet 在网络恢复后可以接收到网络故障时产生的消息)。
正是因为 Kubernetes 使用了 Level trigger 才让集群更加可靠。
参考资料
https://levelup.gitconnected.com/nginx-event-driven-architecture-demonstrated-in-code-51bf0061cad9 https://www.quora.com/What-is-meant-by-edge-triggering-and-level-triggering
原文链接:https://www.cnblogs.com/Cylon/p/15681121.html