
田渊栋团队新作:为什么非对比自监督学习效果好?ICML2021已接收

新智元报道
新智元报道
来源:arXiv
编辑:好困
【新智元导读】非对比自监督学习一直存在着几个基本理论问题:如何避免表征崩溃?学习到的表征的性质是什么?近日,田渊栋团队首次对模型训练的行为以及多个超参数的经验效应进行了分析,并提出了极为简单的预测器设置方法,论文已经被ICML 2021接收。
自监督学习 (SSL) 的对比方法通过最小化同一数据点(positive pairs)的两个增强视图之间的距离,和最大化不同数据点(negative pairs)的视图之间的距离来学习表征。
最近BYOL和SimSiam的非对比自监督学习方法在没有negative pairs的情况下也能表现出卓越的性能。
那么,为什么这些方法没有造成表征崩溃?
近期,田渊栋团队发表了一篇论文对这个问题进行了讨论,并且已经被ICML 2021接收。

https://arxiv.org/abs/2102.06810
作者受到简单线性网络中非线性学习动态的启发,提出了一种新方法DirectPred,它根据输入的统计数据直接设置线性预测器,而无需梯度训练。
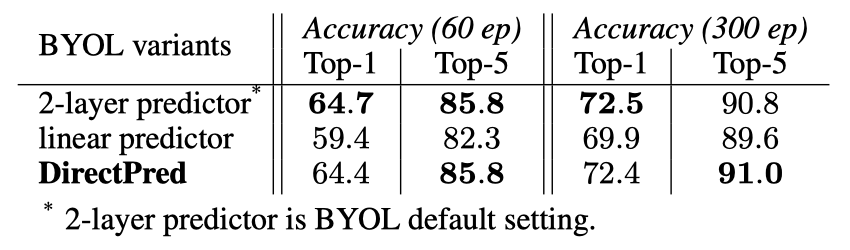
在ImageNet上,DirectPred的性能与使用BatchNorm的双层非线性预测器相当,并且在300个epoch的训练中比线性预测器强2.5%,在60个epoch的训练中强5%。
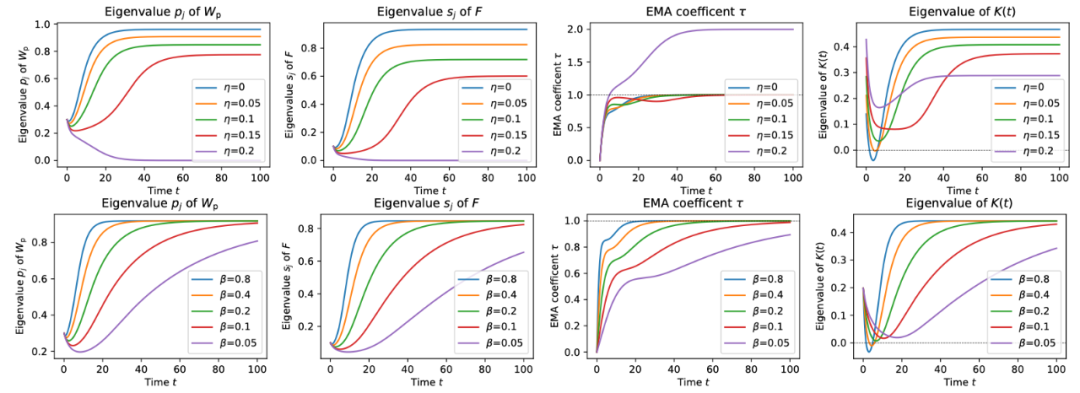
在本文中,作者首次尝试分析非对比自监督学习训练的行为以及多个超参数的经验效应:
指数移动平均线(EMA)或动量编码器 更高的预测器相对学习率(αp) 权重衰减 η
介绍
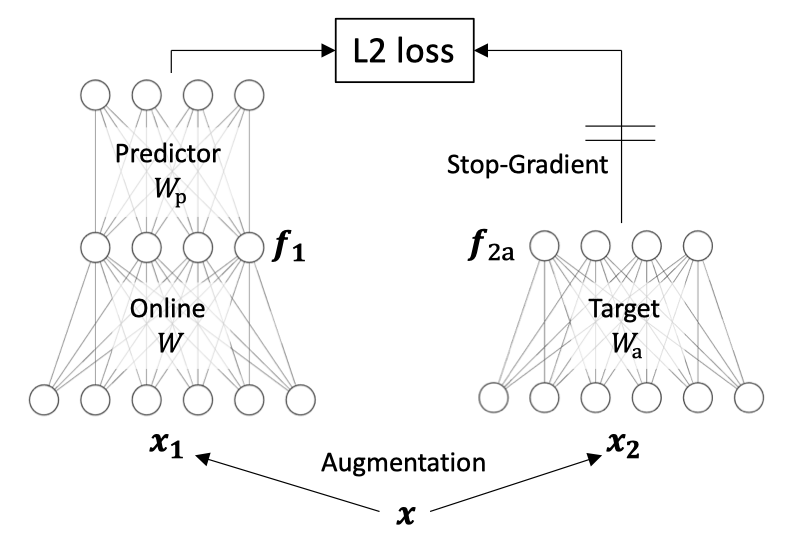
双层线性模型

免优化预测器Wp

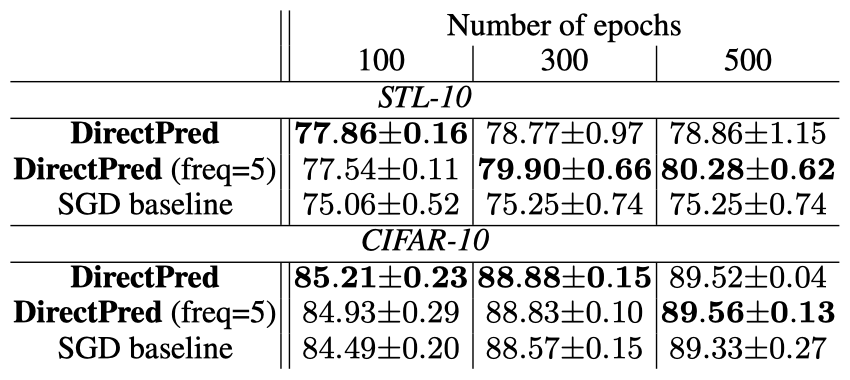

采用非对称损失,其中,损失使用标准SGD优化60个epoch,批大小为256。
采用对称损失、4096批大小和LARS优化器,并训练了300个epoch。
总结
作者介绍


参考资料:
https://arxiv.org/abs/2102.06810

评论