
前端正则进阶篇,高薪必看【超详细】

闲谈
说起正则 大家第一反应肯定是各种表单验证 什么用户名 密码 邮箱... 的确 前端使用正则进行用户输入验证是最常见的场景 但是我相信大多数的前端都忽略了正则这一块的知识点 和我一样 Ctrl+c Ctrl+v 各种正则表达式就到手了
哈哈 直到我看 Vue 源码-模板解析这块正则时 我的内心是崩溃的(这是什么火星文) 既如此那就让我们代表月亮消灭它
vue源码-解析属性相关正则
/^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
1 正则表达式 是什么
答:正则表达式就是处理字符串的
如何处理呢?
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子串、将匹配的子串做替换或者从某个字符串中取出符合某个条件的子串等。
记住两个关键作用:
1.搜索字符串 2.替换字符串
2 正则表达式 怎样创建
方法一:字面量方式
语法格式为: /正则表达式主体/修饰符(可选)
const reg = /\d/gi;
方法二:构造函数
语法格式为:new RegExp(正则表达式主体[, 修饰符])
const reg = new RegExp('\d', 'gi')
对比:字面量方式更简洁效率更高 但是无法拼接变量
常用_修饰符_如下
| 修饰符 | 作用 |
|---|---|
| i | 忽略大小写匹配 |
| g | 全局匹配,即是匹配一个后继续匹配,直到结束 |
| m | 多行匹配,即是遇到换行后不停止匹配,直到结束 |
3 正则表达式语法
3.1 字符集合与范围类[ ]

“
字符集合和范围类都是使用中括号[]定义的 区别:范围类在中括号[]里面是用短横线-连接(左边的要小于右边的 不然会报错)
3.2 预定义元字符类
| 代码 | 说明 |
|---|---|
| . | 匹配任意单个字符,除换行和结束符 |
| \d | 匹配数字,等价于 [0-9] |
| \D | 匹配非数字,等价于 [^0-9] |
| \s | 匹配空白字符 主要有(\n、\f、\r、\t、\v) |
| \S | 匹配非空白字符 |
| \w | 匹配任意单词字符(数字、字母、下划线),等价于[A-Za-z0-9_] |
| \W | 匹配任意非单词字符,与\w 相反,等价于[^a-za-z0-9_] |
3.3 边界类
| 代码 | 说明 | 举例 |
|---|---|---|
| ^ | 匹配字符串的开始 | /^a/匹配"an A",而不匹配"An a" |
| $ | 匹配字符串的结束 | /a$/匹配"An a",而不匹配"an A" |
| \b | 匹配单词的开始或结束 | /\bno/ 匹配 "at noon" 中的 "no" |
3.4 量词类
| 代码 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次(至少有一次) |
| ? | 重复零次或一次(可有可无) |
| {n} | 重复 n 次 |
| {n,m} | 至少 n 次最多 m 次 |
| {n,} | 至少 n 次 |
3.5 特殊符号类
| 代码 | 说明 | 举例 |
|---|---|---|
| / | 字面量方式声明正则时的界定符 | /xxx/ |
| \ | 对正则表达式功能字符的还原 | ?匹配它前面元字符 0 次或 1 次,/ba?/将匹配 b,ba,加了\后,"/ba\?"/将只匹配"ba?" |
| a |
3.6 捕获分组与非捕获分组( )
捕获分组(x) 匹配 x 并且捕获匹配项
例如:/(foo)/ 匹配且捕获 "foo bar" 中的 "foo"。被匹配的子字符串可以通过 元素[n] 中找到,或 RegExp 对象的属性 $n 中找到
`"foo bar".match(/(foo)\s+bar/)`
`// ["foo bar", "foo"]`
非捕获分组(?:x) 匹配 x 不会捕获匹配项。匹配项不能够从结果再次访问
`"foo bar".match(/(?:foo)\s+bar/)`
`// ["foo bar"]`
“
上面的例子看上去非捕获分组貌似没什么用 其实它的用处很大 我们看看下面的例子
希望匹配字母,且字母之间可以为1或2时,但最终结果不需要中间的数字 只需要两边的字母
'abcd1j452h'.match(/[a-z]+(1|2)+([a-z]+)/);
["abcd1j", "1", "j"] //不使用非捕获分组 会把中间数字1也放入结果
'abcd1j452h'.match(/[a-z]+(?:1|2)+([a-z]+)/);
["abcd1j", "j"] //这样才完成需求
3.7 贪婪与非贪婪模式
默认使用贪婪模式 尽可能多的匹配
在重复量词后面加一个?,代表使用非贪婪模式,尽可能短的匹配
`"1234567".match(/\d{2,5}/)
//默认贪婪模式(尽可能匹配多)
[12345]`
`"1234567".match(/\d{2,5}?/)
//转成非贪婪模式
[12]`
3.8 正向肯定查找和正向否定查找
| 代码 | 说明 |
|---|---|
| x(?=y) | 只有当 x 后面紧跟着 y 时,才匹配 x。 |
| x(?!y) | 只有当 x 后面不是紧跟着 y 时,才匹配 x。 |
`const target = 'bg.png index.html app.js index.css test.png'
//从以上字符串中找出以png结尾的文件名
//不使用正向肯定查找的做法
target.match(/\b(\w+)\.png/g)
//["bg.png", "test.png"] 我们只想要文件名 不想要.png后缀`
`使用正向肯定查找
target.match(/\b(\w+)(?=\.png)/g)
// ["bg", "test"]`
“
注意:x(?=y)需要和非捕获分组(?:)区分开(写法很类似) 其次 x(?=y)最终匹配结果只有 x 没有 y
4 正则实例属性
RegExp.prototype.global 是否开启全局匹配
RegExp.prototype.ignoreCase 是否要忽略字符的大小写
RegExp.prototype.lastIndex 下次匹配开始的字符串索引位置
RegExp.prototype.multiline 是否开启多行模式匹配(影响 ^ 和 $ 的行为)
RegExp.prototype.source 正则对象的源模式文本
RegExp.prototype.sticky 是否开启粘滞匹配
5 正则实例方法
5.1 test
语法:regObj.test(str) 对字符串执行搜索
返回值:布尔值。测试 str 中是否存在匹配 regObj 模式的字符串,存在返回 true,不存在返回 false
“
用法很简单 但是有坑点 该方法在正则对象是否带有全局属性(g)下的表现不同
先介绍下正则对象的 lastIndex 属性,lastIndex 是正则表达式匹配内容时,开始匹配的位置。
不带全局属性 g
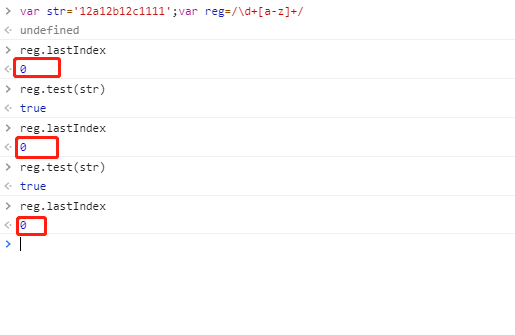
由上可见:刚开始都是从下标 0 处开始匹配,不带 g 时,无论执行多少次,该正则对像的 lastIndex 属性均不变
带全局属性 g
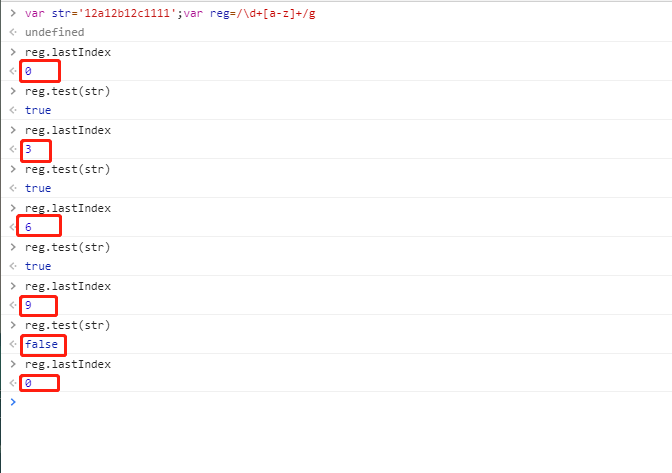
由上可见:该开始从下标为 0 处开始匹配,匹配后会自动修改该正则对象的 lastIndex 属性,且修改为当前表达式匹配内容的最后一个字符的下一个位置。一直到字符串结尾,重新设置 lastIndex 为 0。可见其中有一次匹配失败了 因为从 lastIndex 为 9 开始继续查找就没有匹配的结果了 这一点一定要注意
5.2 exec
语法:regObj.exec(str)对字符串执行搜索
返回值:如果没有匹配的文本则返回 null,否则返回一个结果数组:
返回的数组:第一个元素与正则表达式相匹配的文本;第二个元素是与 RegExpObject 的第一个捕获组相匹配的文本(如果有的话);第三个元素是与 RegExpObject 的第二个捕获组相匹配的文本(如果有的话),以此类推。
“
该方法在正则对象是否带有全局属性(g)下的表现不同 其表现和 test 一致
不带 g 时

带 g 时

6 字符串实例方法
6.1 search
语法:str.search(reg)找出首次匹配项的索引
返回值:返回匹配成功的第一个位置,如果没有任何匹配,则返回-1
'abc'.search(/b/)
//1
6.2 split
语法:str.split(reg[,maxLength]) 第一个参数可以是字符串或者正则表达式,它是分隔符;第二个参数可选,限制返回数组的最大长度。
返回值:数组
'abc-def_mno+xyz'.split(/[-_+]/, 3);
//["abc", "def", "mno"]
6.3 match
语法:str.match(reg)找到一个或多个正则表达式的匹配
返回值:数组或者 null
“
该方法在正则对象是否带有全局属性(g)下的表现不同
不带 g 时(只查找一次 遇到匹配之后就停止 返回结果和 exec 方法一致)
var str='12a12b12c1111';
var reg=/\d+([a-z]+)/;
str.match(reg)
//["12a", "a", index: 0, input: "12a12b12c1111", groups: undefined]
带 g 时(全局检索 如果找到了一个或多个匹配字符串,则返回一个数组--不包含捕获组)
var str='12a12b12c1111';
var reg=/\d+([a-z]+)/g;
str.match(reg)
//["12a", "12b", "12c"]
6.4 replace
语法:str.replace(reg/substr,newStr/function) 第一个参数可以是字符串或者正则表达式,它的作用是匹配。第二个参数可以是字符串或者函数,它的作用是替换。
返回值:替换了之后的新的字符串,原字符串不变
第一个参数是字符串和正则表达式的区别在于:正则表达式的表达能力更强,而且可以全局匹配。因此参数是字符串的话只能进行一次替换。
`'abc-xyz-abc'.replace('abc', 'biu');
// "biu-xyz-abc"`
`'abc-xyz-abc'.replace(/abc/g, 'biu');
// "biu-xyz-biu"`
第二个参数是字符串时
replace 方法为第二个参数是字符串的方式提供了一些特殊的变量,能满足一般需求。
$ 数字代表相应顺序的捕获组。注意,虽然它是一个变量,但是不要写成模板字符串${$1}biu,replace 内部逻辑会自动解析字符串,提取出变量。
var reg=/(\d{2})\/(\d{2})\/(\d{4})/
var str='09/05/2020'
var res=str.replace(reg,'$3-$2-$1') // 2020-05-09
第二个参数是函数时
字符串的变量毕竟只能引用,无法操作。与之相对,函数的表达能力就强多了。
函数的返回值就是要替换的内容。函数如果没有返回值,默认返回undefined,所以替换内容就是 undefined。
先看例子
var str='a1b2c3d4e'
var result=str.replace(/(\d)(\w)(\d)/g,(matchStr,group1,group2,group3,index,originStr)=>{
return group1+group3
}) //'a12c34e'
第一个参数 matchStr 是匹配结果 第二个参数以及到倒数第二个参数为止 如果有捕获组,函数的后顺位参数与捕获组一一对应。例如我们例子里面的 group1 到 group3 倒数第二个参数是匹配结果在文本中的位置 最后一个参数是源文本
ok 我们分析一下例子
第一次查找匹配到'1b2' 然后我们 return group1+group3 group1 是第一个捕获组 就是 1 group3 是第三个捕获组 2 字符串'1'+'2'就是'12' 所以用 12 替换了'1b2' 第一次替换之后的结果就是'a12' 然后继续向后查找将'3d4'替换成'34' 最终结果就是'a12c34e'
原文地址
https://juejin.cn/post/6844904153131515912