
简单有效 | Transformer通过剪枝降低FLOPs以走向部署(文末获取论文)

1 简介
Visual Transformer在各种计算机视觉应用中取得了具有竞争力的性能。然而,它们的存储、运行时的内存以及计算需求阻碍了在移动设备上的部署。在这里,本文提出了一种Visual Transformer剪枝方法,该方法可以识别每个层中通道的影响,然后执行相应的修剪。通过促使Transformer通道的稀疏性,来使得重要的通道自动得到体现。同时为了获得较高的剪枝率,可以丢弃大量系数较小的通道,而不会造成显著的损害。
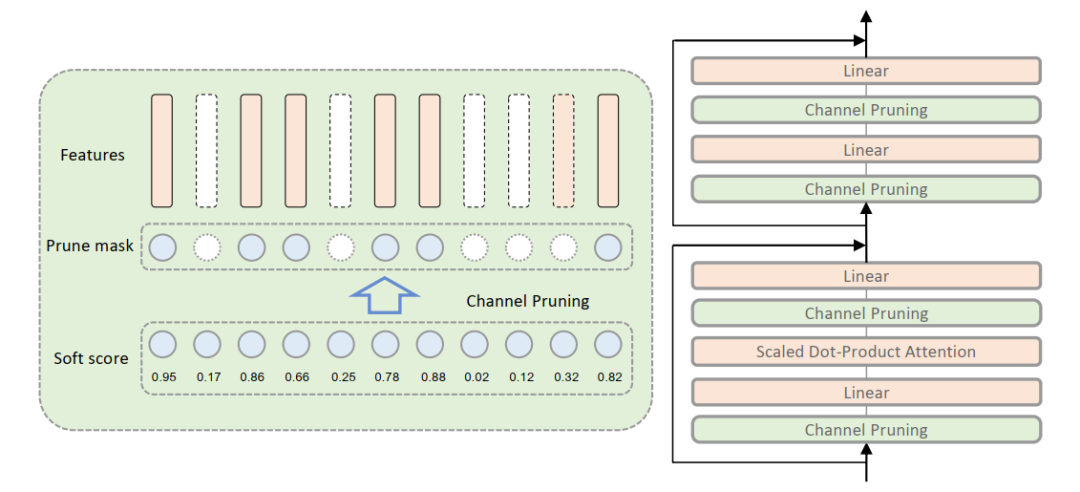
Visual transformer修剪的流程如下:
Training with sparsity regularization Pruning channels Finetuning
在ImageNet数据集上验证了该算法的有效性。
2 Approach
2.1 复杂度分析
其实大家都知道典型的ViT结构包括Multi-Head Self-Attention(MHSA)、Multi-Layer Perceptron(MLP)、 layer normalization、激活函数以及Shortcut。
MHSA是Transformer组件,在token之间进行信息的交互。具体来说,将输入X通过全连接层转换为query 、key 和value ,其中n为patches的数量,d为embedding维数。这里利用self-attention对patch之间的关系进行建模:
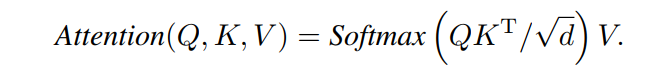
最后,利用线性变换生成MHSA的输出:
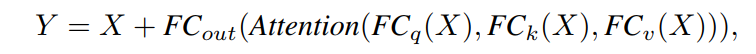
为了简化,忽略了layer normalization和激活函数。MHSA的参数量为,FLOPs为。对于双层MLP,可以写成:
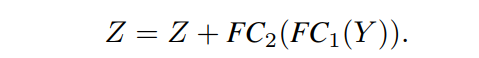
Hidden Layer dimension通常设置为,其参数量为, FLOPs为。与MHSA和MLP相比,layer normalization、激活函数和Shortcut的参数或FLOPs可以忽略。所以一个Transformer block约有的参数量和的FLOPs,其中MHSA和MLP占绝大多数计算量。
2.2 ViT剪枝
其实通过前面对于复杂度的分析可以看出来,绝大多数的计算量都被消耗再MHSA和MLP上了,所以为了实现Transformer架构的精简,作者着重于减少MHSA和MLP的FLOPs。
本文提出通过学习每个维度的重要性得分来减少特征的维度。对于特征,其中n表示待剪枝的通道数量,d表示每个通道的维度,而目标是保留重要的特征,去除无用的特征。假设最优的重要度评分为,即重要特征的评分为1,无用特征的评分为0。利用重要度分数可以得到剪枝后的特征:
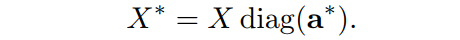
然而,由于其是离散值导致很难通过反向传播算法优化神经网络中的。因此,作者提出使用松弛为real value 。得到的soft pruned特征为:
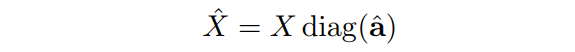
然后,relaxed importance scores 可以和transformer网络的端到端一起学习。
为了加强importance scores的稀疏性,对系数应用L1正则化:,并通过添加训练目标来优化它,其中是稀疏超参数。经过稀疏惩罚训练后,得到一些重要值接近于零的transformer。对transformer中的所有正则化系数值进行排序,并根据预先定义的剪枝率获得阈值。在阈值下,通过将阈值以下的值设为0,较高的值设为1得到离散的:
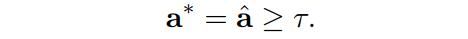
在根据importance scores 进行修剪后,被修剪的总transformer将被微调以减少精度下降。以上修剪过程记为:
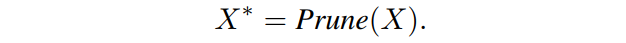
如图1所示,我们对所有MHSA和MLP块应用剪枝操作。它们的修剪过程可以表述为:

所提出的visual transformer pruning(VTP)方法为slim visual transformer提供了一种简单而有效的方法。
3 Experiments
3.1 ImageNet-100
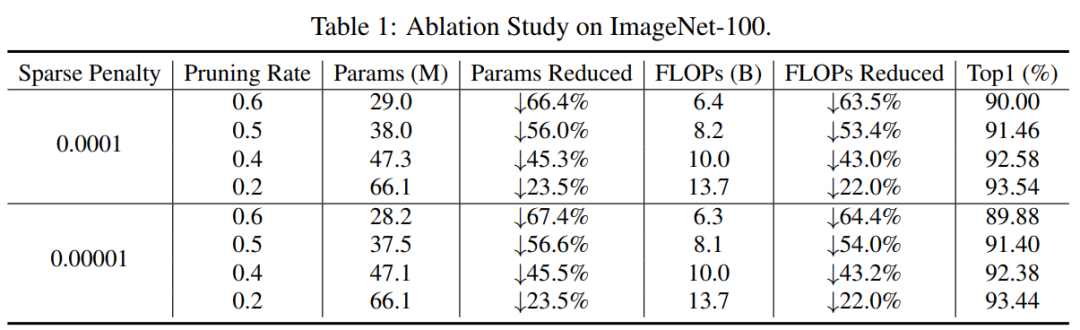
如表1所示从结果来看,剪枝率的大小与参数量和FLOPs的比例相匹配。例如,当修剪40%的通道的模型训练0.0001稀疏率,参数saving是45.3%,FLOPs saving是43.0%。可以看到在精度保持不变的情况下,参数和FLOPs下降了。此外,稀疏比对剪枝方法的有效性影响不大。
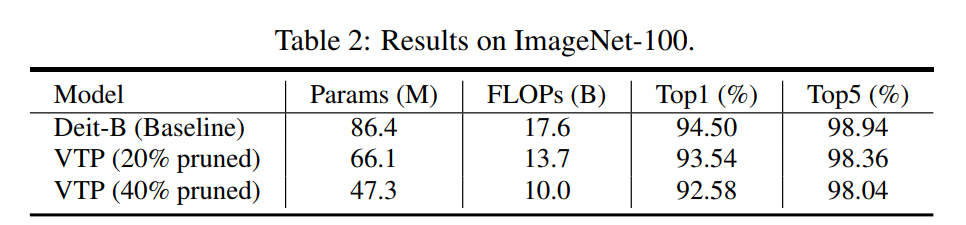
在表2中比较了Baseline模型和2种VTP模型,即20% pruned和40% pruned模型。精度会随着较大的下降而略有下降。当删除20%的通道时,22.0%的FLOPs被保存,准确率下降了0.96%。当删除40%的通道时,节省了45.3%的FLOPs,准确率也下降了1.92%。
3.2 ImageNet-1K
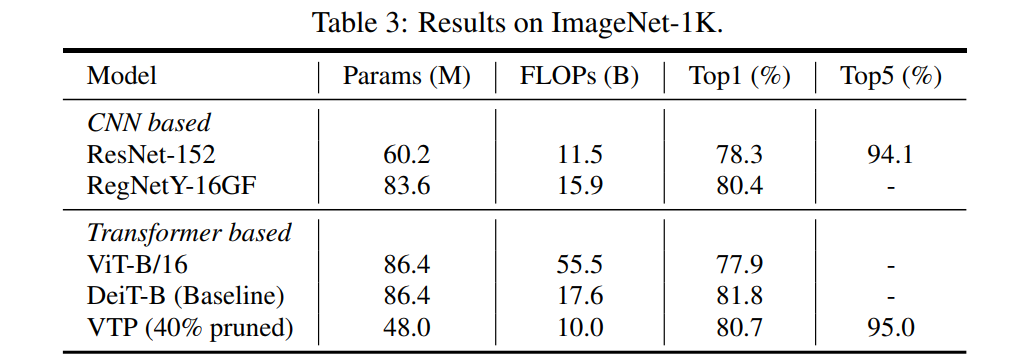
结果如表3所示。可以看出,与原始DeiT-B相比,在对40%的通道进行修剪后,VTP的准确率仅降低了1.1%。可以看出VTP的有效性可以推广到大规模数据集。
4 参考
[1].Visual Transformer Pruning
5 推荐阅读
又改ResNet | 重新思考ResNet:采用高阶方案的改进堆叠策略(附论文下载)
VariFocalNet | IoU-aware同V-Focal Loss全面提升密集目标检测(附YOLOV5测试代码)
最强Vision Trabsformer | 87.7%准确率!CvT:将卷积引入视觉Transformer(文末附论文下载)
全新FPN | 通道增强特征金字塔网络(CE-FPN)提升大中小目标检测的鲁棒性(文末附论文)
经典Transformer | CoaT为Transformer提供Light多尺度的上下文建模能力(附论文下载)
本文论文原文获取方式,扫描下方二维码
回复【VTP】即可获取论文
长按扫描下方二维码加入交流群
声明:转载请说明出处
扫描下方二维码关注【AI人工智能初学者】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!!!
点“在看”给我一朵小黄花呗![]()