
分享一套 Spark 作业的性能优化方案
这年代,做数据的,没人不知道 Spark 是什么吧。作为最火的大数据计算引擎,现在基本上是各互联网大厂的标配了。
比如,字节跳动基于 Spark 构建的数据仓库,服务了几乎所有的产品线,包括抖音、今日头条、西瓜视频等。再比如,百度基于 Spark 推出 BigSQL,为海量用户提供次秒级的即席查询。可以说,在海量数据处理上,Spark 的角色至关重要。
想到我刚刚接触 Spark 那会儿,真心佩服它的开发效率,是真高啊!MapReduce 上千行代码才能实现的业务功能,Spark 几十行代码就搞定了。
现在就更牛了,去年 6 月,Spark 直接从 2.4 直接升级到了3.0,最大的亮点就在于性能优化,它添加了诸如自适应查询执行(AQE)、动态分区剪裁(DPP)、扩展的 Join Hints 等新特性。这估计会让 Spark 在未来 5 到 10 年继续雄霸大数据生态圈。
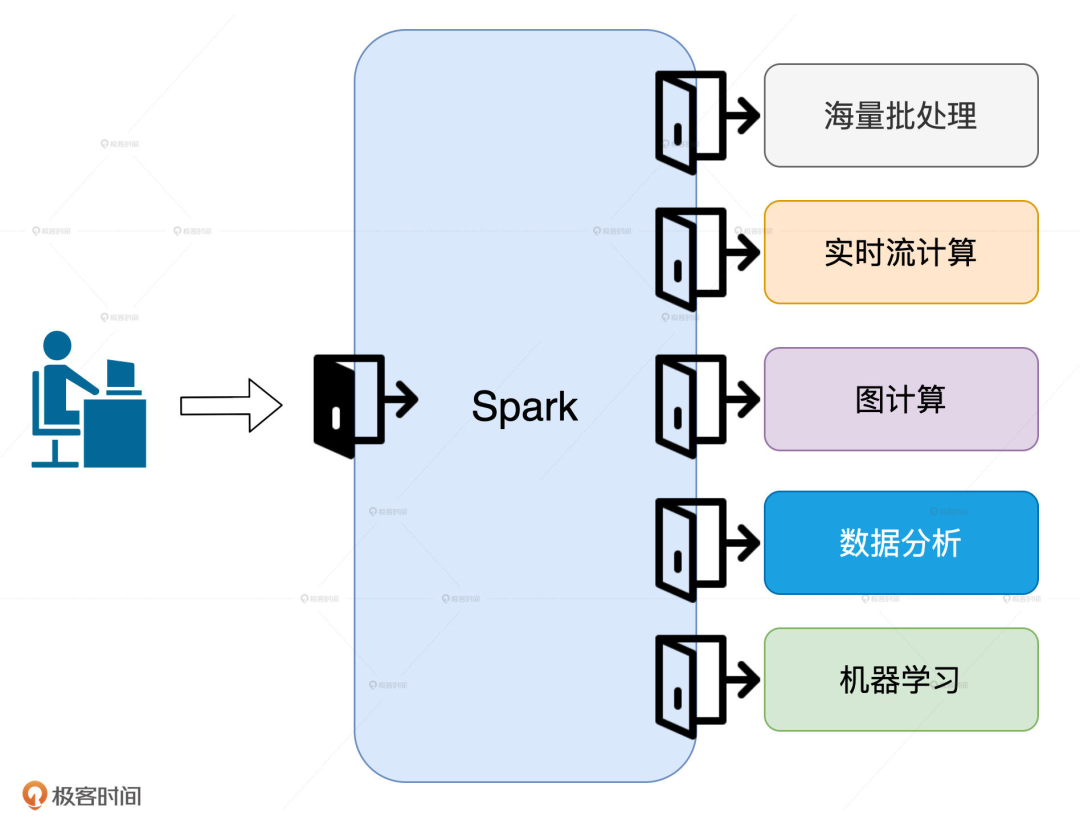
就目前来说,Spark 有海量批处理、实时流计算、图计算、数据分析和机器学习这 5 大应用场景,不论你打算朝哪个方向深入,「性能调优」都是必须要跨越的一步。
原因很简单,对于这 5 大场景来说,提高执行性能是刚需。想要精通 Spark,就得拿下“性能调优”这把万能钥匙。
很多开发者都意识到这一点,但难就难在,市面上关于 Spark 性能调优的资料,大都不系统,只是在讲一些常规的调优技巧和方法。而对于一些大神分享的调优手段,只是“照葫芦画瓢”做出来的东西,也总是达不到预期的效果,比如:
明明都是内存计算,为什么我用了 RDD/DataFrame Cache,性能反而更差了?
网上吹得神乎其神的调优手段,为啥到了我这就不好使呢?
并行度设置得也不低,为啥我的 CPU 利用率还是上不去?
节点内存几乎全都划给 Spark 用了,为啥我的应用还是 OOM?
这些问题看似简单,但真不是一两句话就能说得清的。这需要我们深入Spark的核心原理,不断去尝试每一个API、算子,设置不同的配置参数,最终找出最佳的排列组合。
说到底,还是需要更多的学习案例与实操。我最近关注到 FreeWheel 机器学习团队负责人吴磊,总结了出一套关于「性能调优的方法论」。挺戳中我的,分享给大家👇
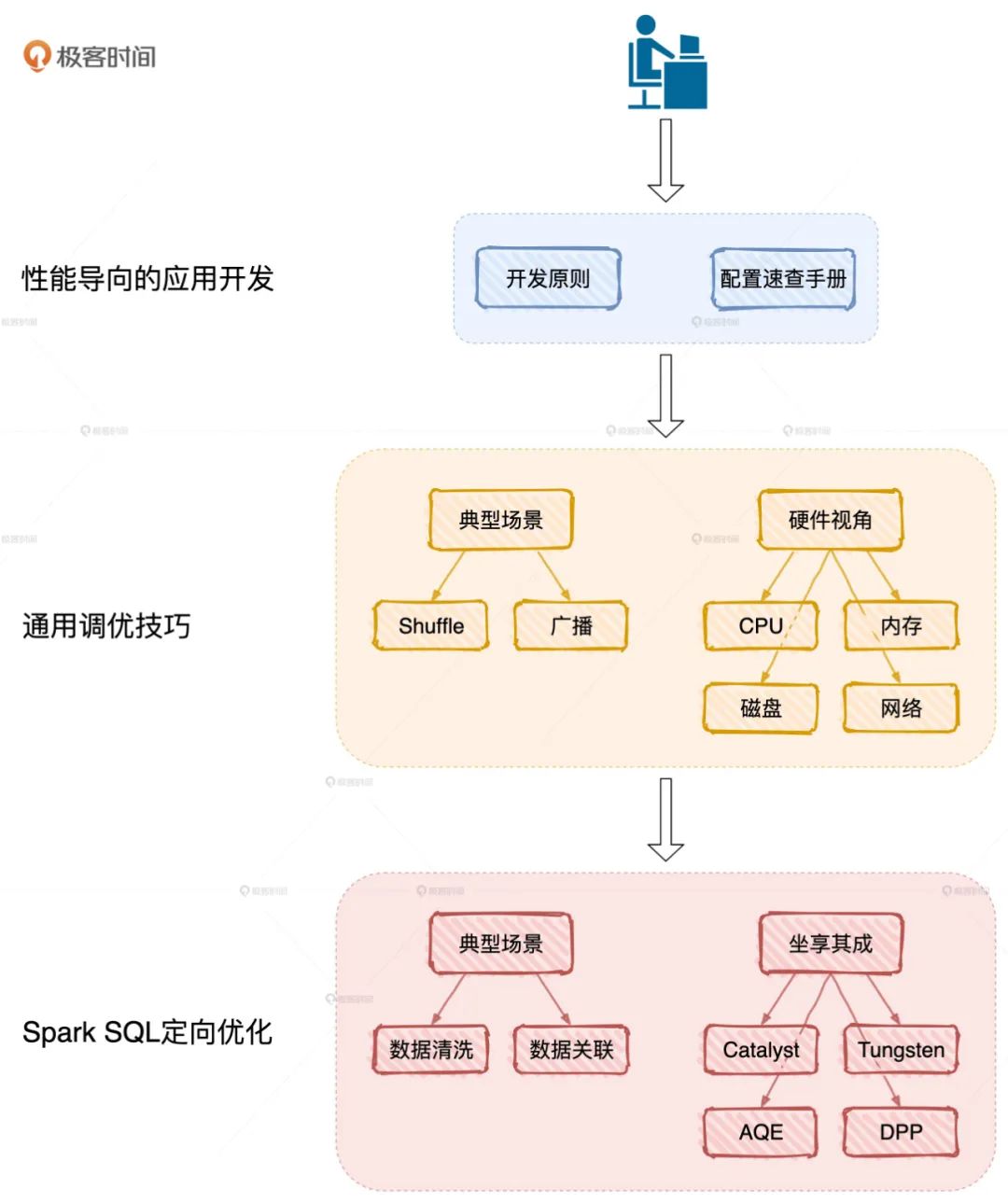
按图索骥开展性能调优
这张图来自吴磊的极客时间专栏《Spark 性能调优实战》,刚刚上线,不仅深入浅出的讲了 Spark 核心原理,还全面解析 Spark SQL 性能调优,总结了一份应用开发、配置项设置实操指南,真心实用。
最吸引我的是实操,专栏以「北京市汽油车摇号」数据为例,手把手带你实现一个分布式应用。一句话总结,就是能让你一站式加速 Spark 作业执行性能,是不是很牛。
△ 扫码免费试读或订阅
拼团 + 口令「Happy2021」
立省 ¥30,到手仅 ¥69
更有新人到手价 ¥59.9
作者是吴磊,现任 Comcast Freewheel 机器学习团队负责人,主要负责计算广告业务中机器学习应用的实践、落地与推广。之前也任职于 IBM、联想研究院、新浪微博,可以说具备丰富的数据库、数据仓库、大数据开发与调优经验了。
早之前听说过他,研究 Spark 是下了功夫的,而且做事儿有股“较真儿”的风格,看他上面总结的方法论图就知道,是个严谨、认真的人,跟着这样有实践、有理论,懂实现细节的大佬学习,错不了。
Spark 怎么能“学得快,还学得好”?
跟着大佬,能又快又好的学,那就是省“时间”,找到捷径、赚到了,目前专栏 3 个部分的内容,干货不少:
原理篇:聚焦 Spark 底层原理,打通性能调优的任督二脉
Spark 的原理非常多,但专栏聚焦于那些与性能调优息息相关的核心概念,包括RDD、DAG、调度系统、存储系统和内存管理。而且用的是最贴切的故事和类比、最少的篇幅,让你在最短的时间内掌握其核心原理,为后续的性能调优打下坚实的基础。
性能篇:实际案例驱动,多角度解读,全方位解析性能调优技巧
一部分是讲解性能调优的通用技巧,包括应用开发的基本原则、配置项的设置、 Shuffle 的优化、资源利用率的提升。另一部分会专注于数据分析领域,借助 Spark内置优化如 Tungsten、AQE 和典型场景如数据关联,和你聊聊 Spark SQL 中的调优方法和技巧。
实战篇:打造属于自己的分布式应用
专栏以 2011 - 2019 的《北京市汽油车摇号》数据为例,手把手教你打造一个分布式应用,带你从不同角度洞察汽油车摇号的趋势和走向。我相信,通过这个实战案例,你对性能调优技巧和思路的把控肯定会有一个“质的飞跃”。
除此之外,听说吴磊还会不定期地针对热点话题加餐,比如和 Flink、Presto 相比,Spark 有哪些优势,再比如 Spark 的一些新特性,以及业界对于 Spark 的新探索。这也能帮助我们更好地面对变化,把握先机。
吴磊很有耐心,可以说每条留言都回复。说实话,评论区都能学到不少东西,口碑有多好,我说了不算,截了一些评价供你参考:
不仅如此,我们还有一个特别活跃的 Spark 交流群,群友们每天都在群里互相交流技术心得,平时在群里也能涨知识。
专栏的目录我也放到这儿了,看着感觉很不错,理论和实践相结合。

在现在大数据技术领域,基本上是 Spark 形成了一家独大的局面,所以该抓住机会学习的,还得学。
再提醒下,原价 ¥99
结算时用优惠口令「Happy2021」
立省 ¥30,到手仅 ¥69
新人到手价 ¥59.9
走心的努力,才算真的努力。2 杯奶茶的价格,拿下这套 Spark 性能调优方法论,值了👇