
PVT:可用于密集任务backbone的金字塔视觉transformer!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
自从ViT之后,关于vision transformer的研究呈井喷式爆发,从思路上分主要沿着两大个方向,一是提升ViT在图像分类的效果;二就是将ViT应用在其它图像任务中,比如分割和检测任务上,这里介绍的PVT(Pyramid Vision Transformer) 就属于后者。PVT相比ViT引入了和CNN类似的金字塔结构,使得PVT像CNN那样作为backbone应用在dense prediction任务(分割和检测等)。
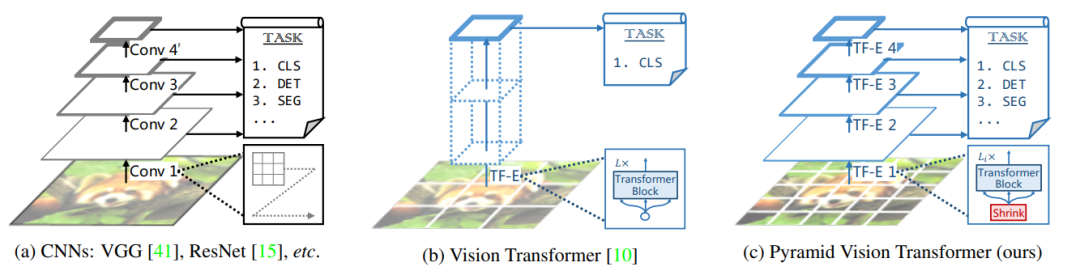
CNN结构常用的是一种金字塔架构,如上图所示,CNN网络一般可以划分为不同的stage,在每个stage开始时,特征图的长和宽均减半,而特征维度(channel)扩宽2倍。这主要有两个方面的考虑,一是采用stride=2的卷积或者池化层对特征降维可以增大感受野,另外也可以减少计算量,但同时空间上的损失用channel维度的增加来弥补。但是ViT本身就是全局感受野,所以ViT就比较简单直接了,直接将输入图像tokens化后就不断堆积相同的transformer encoders,这应用在图像分类上是没有太大的问题。但是如果应用在密集任务上,会遇到问题:一是分割和检测往往需要较大的分辨率输入,当输入图像增大时,ViT的计算量会急剧上升;二是ViT直接采用较大patchs进行token化,如采用16x16大小那么得到的粗粒度特征,对密集任务来说损失较大。这正是PVT想要解决的问题,PVT采用和CNN类似的架构,将网络分成不同的stages,每个stage相比之前的stage特征图的维度是减半的,这意味着tokens数量减少4倍,具体结构如下:
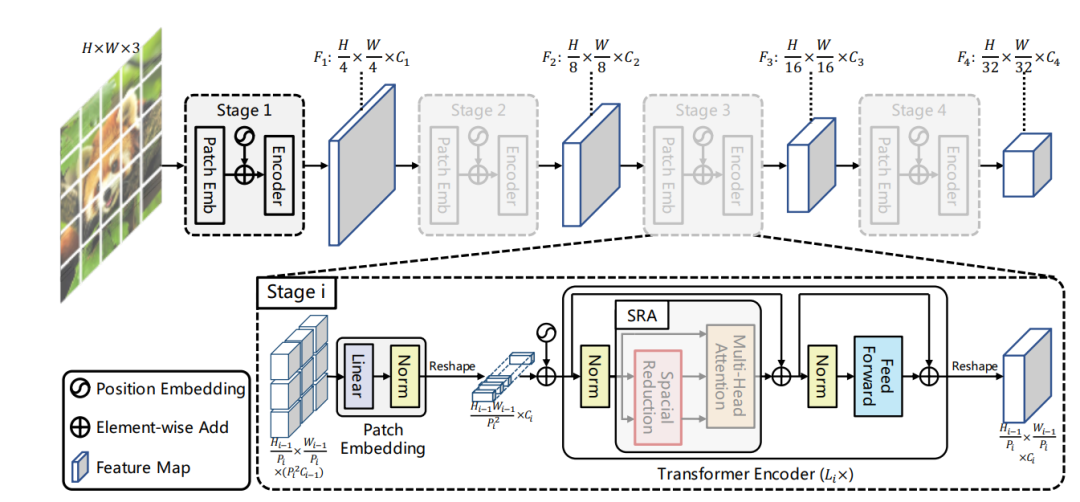
每个stage的输入都是一个维度的3-D特征图,对于第1个stage,输入就是RGB图像,对于其它stage可以将tokens重新reshape成3-D特征图。在每个stage开始,首先像ViT一样对输入图像进行token化,即进行patch embedding,patch大小均采用2x2大小(第1个stage的patch大小是4x4),这意味着该stage最终得到的特征图维度是减半的,tokens数量对应减少4倍。PVT共4个stage,这和ResNet类似,4个stage得到的特征图相比原图大小分别是1/4,1/8,1/16和1/32。由于不同的stage的tokens数量不一样,所以每个stage采用不同的position embeddings,在patch embed之后加上各自的position embedding,当输入图像大小变化时,position embeddings也可以通过插值来自适应。
不同的stage的tokens数量不同,越靠前的stage的patchs数量越多,我们知道self-attention的计算量与sequence的长度的平方成正比,如果PVT和ViT一样,所有的transformer encoders均采用相同的参数,那么计算量肯定是无法承受的。PVT为了减少计算量,不同的stages采用的网络参数是不同的。PVT不同系列的网络参数设置如下所示,这里为patch的size,为特征维度大小,为MHA(multi-head attention)的heads数量,为FFN的扩展系数,transformer中默认为4。
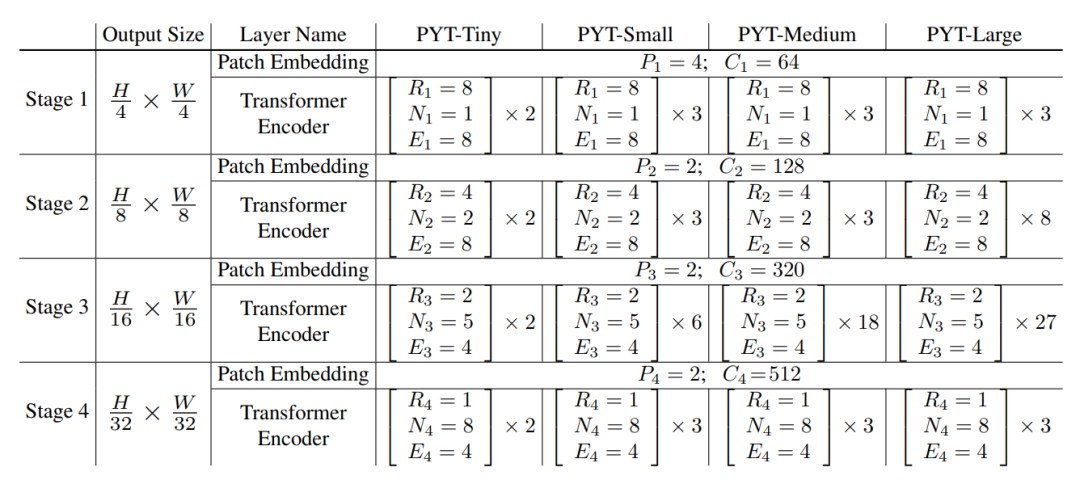
可以见到随着stage,特征的维度是逐渐增加的,比如stage1的特征维度只有64,而stage4的特征维度为512,这种设置和常规的CNN网络设置是类似的,所以前面stage的patchs数量虽然大,但是特征维度小,所以计算量也不是太大。不同体量的PVT其差异主要体现在各个stage的transformer encoder的数量差异。
PVT为了进一步减少计算量,将常规的multi-head attention (MHA)用spatial-reduction attention (SRA)来替换。SRA的核心是减少attention层的key和value对的数量,常规的MHA在attention层计算时key和value对的数量为sequence的长度,但是SRA将其降低为原来的。SRA的具体结构如下所示:
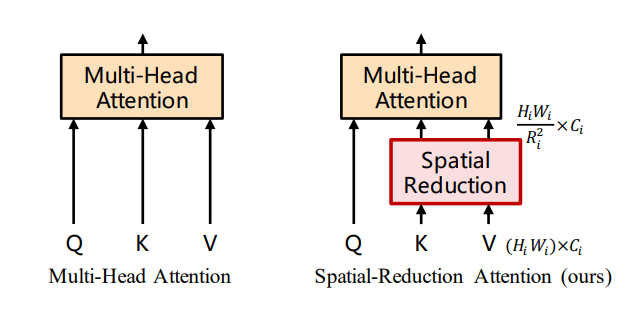
在实现上,首先将维度为的patch embeddings通过
reshape变换到维度为的3-D特征图,然后均分大小为的patchs,每个patchs通过线性变换将得到维度为的patch embeddings(这里实现上其实和patch emb操作类似,等价于一个卷积操作),最后应用一个layer norm层,这样就可以大大降低K和V的数量。具体实现代码如下:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
# 实现上这里等价于一个卷积层
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # 这里x_.shape = (B, N/R^2, C)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
从PVT的网络设置上,前面的stage的取较大的值,比如stage1的,说明这里直接将Q和V的数量直接减为原来的1/64,这个就大大降低计算量了。
PVT具体到图像分类任务上,和ViT一样也通过引入一个class token来实现最后的分类,不过PVT是在最后的一个stage才引入:
def forward_features(self, x):
B = x.shape[0]
# stage 1
x, (H, W) = self.patch_embed1(x)
x = x + self.pos_embed1
x = self.pos_drop1(x)
for blk in self.block1:
x = blk(x, H, W)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
# stage 2
x, (H, W) = self.patch_embed2(x)
x = x + self.pos_embed2
x = self.pos_drop2(x)
for blk in self.block2:
x = blk(x, H, W)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
# stage 3
x, (H, W) = self.patch_embed3(x)
x = x + self.pos_embed3
x = self.pos_drop3(x)
for blk in self.block3:
x = blk(x, H, W)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
# stage 4
x, (H, W) = self.patch_embed4(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # 引入class token
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed4
x = self.pos_drop4(x)
for blk in self.block4:
x = blk(x, H, W)
x = self.norm(x)
return x[:, 0]
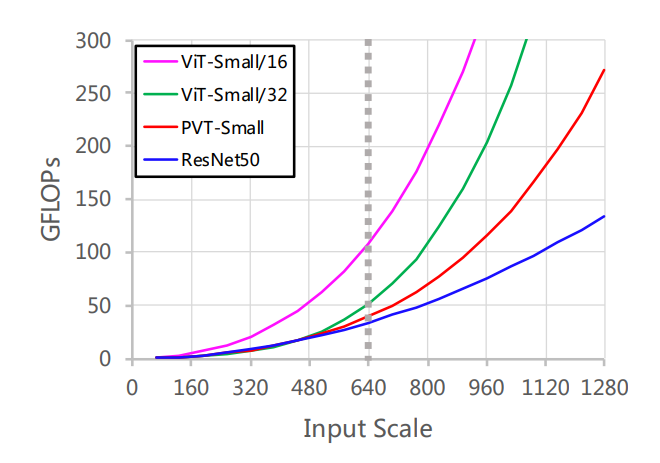
具体到分类任务上,PVT在ImageNet上的Top-1 Acc其实是和ViT差不多的。其实PVT最重要的应用是作为dense任务如分割和检测的backbone,一方面PVT通过一些巧妙的设计使得对于分辨率较大的输入图像,其模型计算量不像ViT那么大,论文中比较了ViT-Small/16 ,ViT-Small,PVT-Small和ResNet50四种网络在不同的输入scale下的GFLOPs,可以看到PVT相比ViT要好不少,当输入scale=640时,PVT-Small和ResNet50的计算量是类似的,但是如果到更大的scale,PVT的增长速度就远超过ResNet50了。
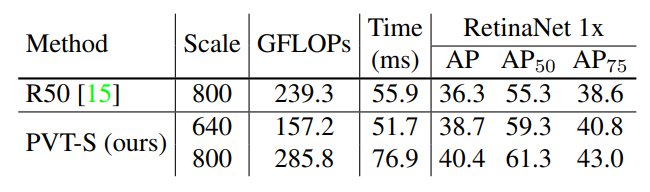
PVT的另外一个相比ViT的优势就是其可以输出不同scale的特征图,这对于分割和检测都是非常重要的。因为目前大部分的分割和检测模型都是采用FPN结构,而PVT这个特性可以使其作为替代CNN的backbone而无缝对接分割和检测的heads。论文中做了大量的关于检测,语义分割以及实例分割的实验,可以看到PVT在dense任务的优势。比如,在更少的推理时间内,基于PVT-Small的RetinaNet比基于R50的RetinaNet在COCO上的AP值更高(38.7 vs. 36.3),虽然继续增加scale可以提升效果,但是就需要额外的推理时间:
所以虽然PVT可以解决一部分问题,但是如果输入图像分辨率特别大,可能基于CNN的方案还是最优的。另外旷视最新的一篇论文YOLOF指出其实ResNet一个C5特征加上一些增大感受野的模块就可以在检测上实现类似的效果,这不得不让人思考多尺度特征是不是必须的,而且transformer encoder本身就是全局感受野的。近期Intel提出的DPT直接在ViT模型的基础上通过Reassembles operation来得到不同scale的特征图以用于dense任务,并在ADE20K语义分割数据集上达到新的SOTA(mIoU 49.02)。而在近日,微软提出的Swin Transformer和PVT的网络架构和很类似,但其性能在各个检测和分割数据集上效果达到SOTA(在ADE20K语义分割数据集mIoU 53.5),其核心提出了一种shifted window方法来减少self-attention的计算量。
相信未来会有更好的work!期待!
参考
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions whai362/PVT 大白话Pyramid Vision Transformer You Only Look One-level Feature Swin Transformer: Hierarchical Vision Transformer using Shifted Windows Vision Transformers for Dense Prediction
推荐阅读
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
"未来"的经典之作ViT:transformer is all you need!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
CondInst:性能和速度均超越Mask RCNN的实例分割模型
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
